 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal envelope and fine structure cues for dysarthric speech detection using CNNs
Paper and Code
Aug 25, 2021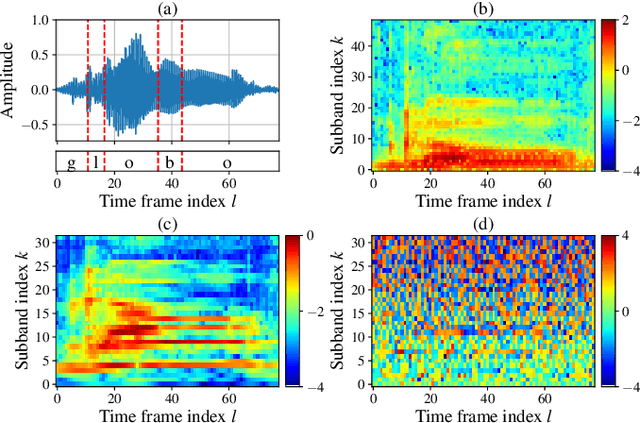
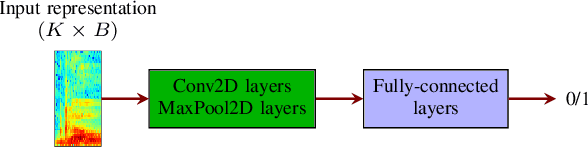
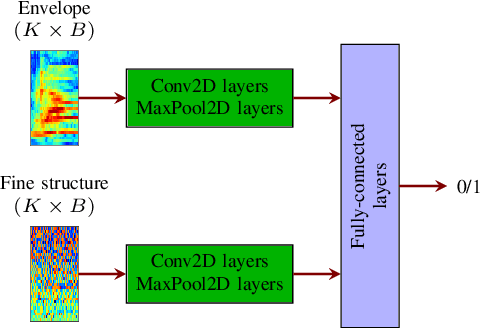
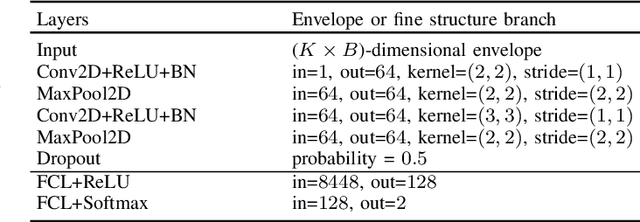
Deep learning-based techniques for automatic dysarthric speech detection have recently attracted interest in the research community. State-of-the-art techniques typically learn neurotypical and dysarthric discriminative representations by processing time-frequency input representations such as the magnitude spectrum of the short-time Fourier transform (STFT). Although these techniques are expected to leverage perceptual dysarthric cues, representations such as the magnitude spectrum of the STFT do not necessarily convey perceptual aspects of complex sounds. Inspired by the temporal processing mechanisms of the human auditory system, in this paper we factor signals into the product of a slowly varying envelope and a rapidly varying fine structure. Separately exploiting the different perceptual cues present in the envelope (i.e., phonetic information, stress, and voicing) and fine structure (i.e., pitch, vowel quality, and breathiness), two discriminative representations are learned through a convolutional neural network and used for automatic dysarthric speech detection. Experimental results show that processing both the envelope and fine structure representations yields a considerably better dysarthric speech detection performance than processing only the envelope, fine structure, or magnitude spectrum of the STFT representation.