 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Effects of Diffusion-based Conditional Generative Speech Models Used for Speech Enhancement on Dysarthric Speech
Dec 18, 2024In this study, we aim to explore the effect of pre-trained conditional generative speech models for the first time on dysarthric speech due to Parkinson's disease recorded in an ideal/non-noisy condition. Considering one category of generative models, i.e., diffusion-based speech enhancement, these models are previously trained to learn the distribution of clean (i.e, recorded in a noise-free environment) typical speech signals. Therefore, we hypothesized that when being exposed to dysarthric speech they might remove the unseen atypical paralinguistic cues during the enhancement process. By considering the automatic dysarthric speech detection task, in this study, we experimentally show that during the enhancement process of dysarthric speech data recorded in an ideal non-noisy environment, some of the acoustic dysarthric speech cues are lost. Therefore such pre-trained models are not yet suitable in the context of dysarthric speech enhancement since they manipulate the pathological speech cues when they process clean dysarthric speech. Furthermore, we show that the removed acoustics cues by the enhancement models in the form of residue speech signal can provide complementary dysarthric cues when fused with the original input speech signal in the feature space.
BraSyn 2023 challenge: Missing MRI synthesis and the effect of different learning objectives
Mar 18, 2024This work addresses the Brain Magnetic Resonance Image Synthesis for Tumor Segmentation (BraSyn) challenge, which was hosted as part of the Brain Tumor Segmentation (BraTS) challenge in 2023. In this challenge, researchers are invited to synthesize a missing magnetic resonance image sequence, given other available sequences, to facilitate tumor segmentation pipelines trained on complete sets of image sequences. This problem can be tackled using deep learning within the framework of paired image-to-image translation. In this study, we propose investigating the effectiveness of a commonly used deep learning framework, such as Pix2Pix, trained under the supervision of different image-quality loss functions. Our results indicate that the use of different loss functions significantly affects the synthesis quality. We systematically study the impact of various loss functions in the multi-sequence MR image synthesis setting of the BraSyn challenge. Furthermore, we demonstrate how image synthesis performance can be optimized by combining different learning objectives beneficially.
Uncertainty Estimation in Contrast-Enhanced MR Image Translation with Multi-Axis Fusion
Nov 20, 2023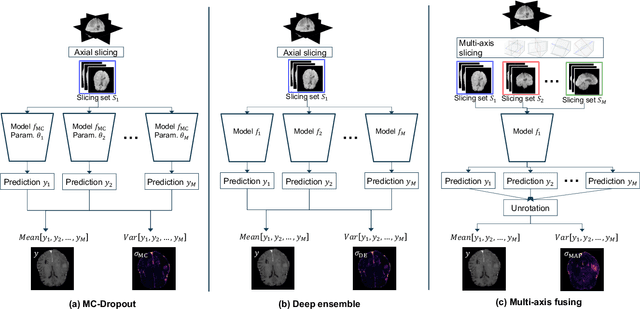
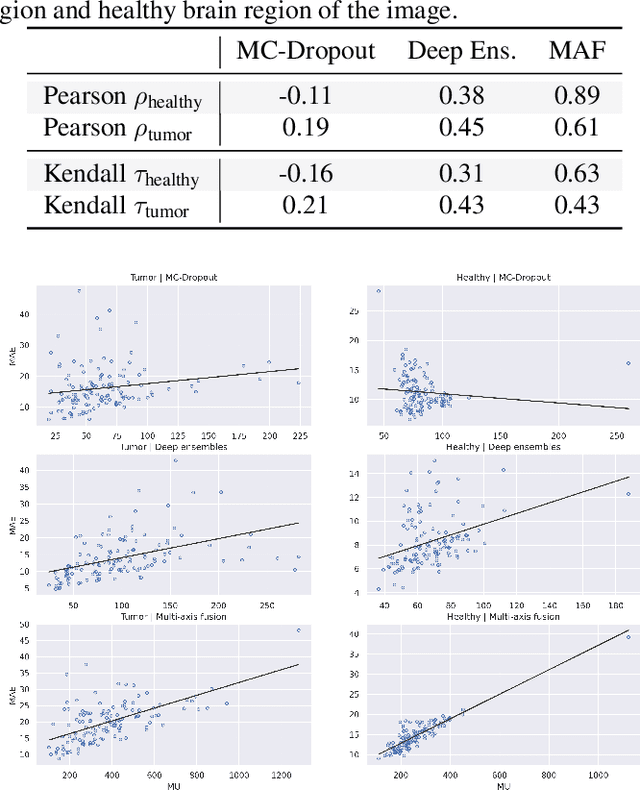
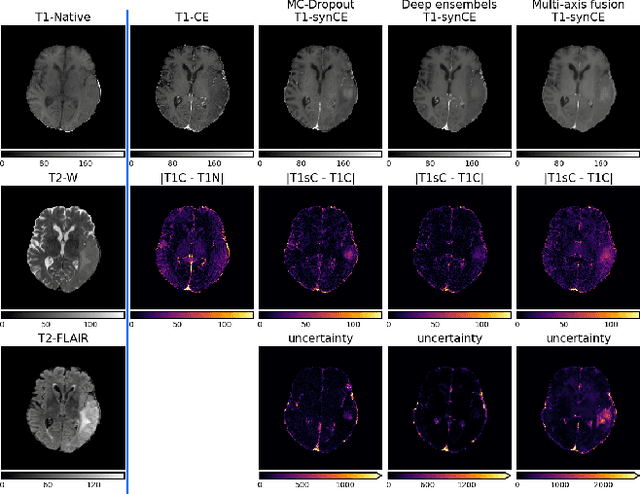
In recent years, deep learning has been applied to a wide range of medical imaging and image processing tasks. In this work, we focus on the estimation of epistemic uncertainty for 3D medical image-to-image translation. We propose a novel model uncertainty quantification method, Multi-Axis Fusion (MAF), which relies on the integration of complementary information derived from multiple views on volumetric image data. The proposed approach is applied to the task of synthesizing contrast enhanced T1-weighted images based on native T1, T2 and T2-FLAIR scans. The quantitative findings indicate a strong correlation ($\rho_{\text healthy} = 0.89$) between the mean absolute image synthetization error and the mean uncertainty score for our MAF method. Hence, we consider MAF as a promising approach to solve the highly relevant task of detecting synthetization failures at inference time.
On using the UA-Speech and TORGO databases to validate automatic dysarthric speech classification approaches
Nov 16, 2022Although the UA-Speech and TORGO databases of control and dysarthric speech are invaluable resources made available to the research community with the objective of developing robust automatic speech recognition systems, they have also been used to validate a considerable number of automatic dysarthric speech classification approaches. Such approaches typically rely on the underlying assumption that recordings from control and dysarthric speakers are collected in the same noiseless environment using the same recording setup. In this paper, we show that this assumption is violated for the UA-Speech and TORGO databases. Using voice activity detection to extract speech and non-speech segments, we show that the majority of state-of-the-art dysarthria classification approaches achieve the same or a considerably better performance when using the non-speech segments of these databases than when using the speech segments. These results demonstrate that such approaches trained and validated on the UA-Speech and TORGO databases are potentially learning characteristics of the recording environment or setup rather than dysarthric speech characteristics. We hope that these results raise awareness in the research community about the importance of the quality of recordings when developing and evaluating automatic dysarthria classification approaches.
Experimental investigation on STFT phase representations for deep learning-based dysarthric speech detection
Oct 07, 2021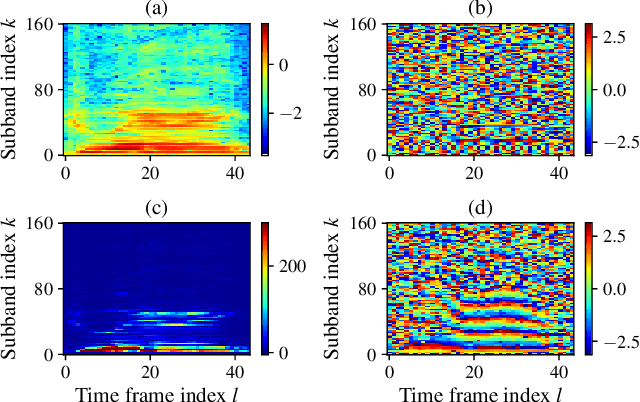

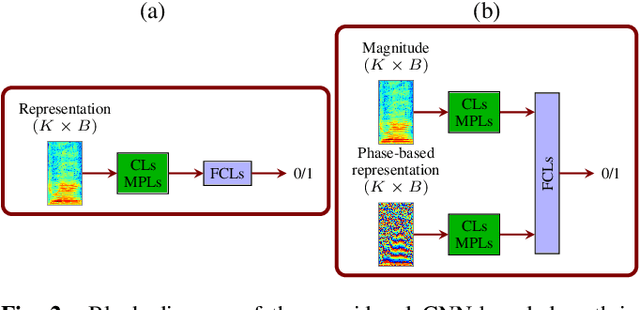
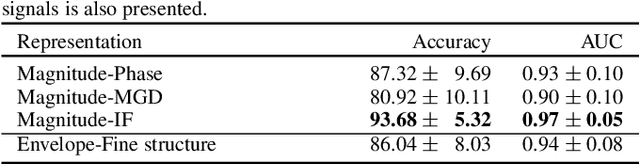
Mainstream deep learning-based dysarthric speech detection approaches typically rely on processing the magnitude spectrum of the short-time Fourier transform of input signals, while ignoring the phase spectrum. Although considerable insight about the structure of a signal can be obtained from the magnitude spectrum, the phase spectrum also contains inherent structures which are not immediately apparent due to phase discontinuity. To reveal meaningful phase structures, alternative phase representations such as the modified group delay (MGD) spectrum and the instantaneous frequency (IF) spectrum have been investigated in several applications. The objective of this paper is to investigate the applicability of the unprocessed phase, MGD, and IF spectra for dysarthric speech detection. Experimental results show that dysarthric cues are present in all considered phase representations. Further, it is shown that using phase representations as complementary features to the magnitude spectrum is very beneficial for deep learning-based dysarthric speech detection, with the combination of magnitude and IF spectra yielding a very high performance. The presented results should raise awareness in the research community about the potential of the phase spectrum for dysarthric speech detection and motivate further research into novel architectures that optimally exploit magnitude and phase information.
Supervised Speech Representation Learning for Parkinson's Disease Classification
Jun 01, 2021


Recently proposed automatic pathological speech classification techniques use unsupervised auto-encoders to obtain a high-level abstract representation of speech. Since these representations are learned based on reconstructing the input, there is no guarantee that they are robust to pathology-unrelated cues such as speaker identity information. Further, these representations are not necessarily discriminative for pathology detection. In this paper, we exploit supervised auto-encoders to extract robust and discriminative speech representations for Parkinson's disease classification. To reduce the influence of speaker variabilities unrelated to pathology, we propose to obtain speaker identity-invariant representations by adversarial training of an auto-encoder and a speaker identification task. To obtain a discriminative representation, we propose to jointly train an auto-encoder and a pathological speech classifier. Experimental results on a Spanish database show that the proposed supervised representation learning methods yield more robust and discriminative representations for automatically classifying Parkinson's disease speech, outperforming the baseline unsupervised representation learning system.