 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFive Pitfalls When Assessing Synthetic Medical Images with Reference Metrics
Aug 12, 2024Reference metrics have been developed to objectively and quantitatively compare two images. Especially for evaluating the quality of reconstructed or compressed images, these metrics have shown very useful. Extensive tests of such metrics on benchmarks of artificially distorted natural images have revealed which metric best correlate with human perception of quality. Direct transfer of these metrics to the evaluation of generative models in medical imaging, however, can easily lead to pitfalls, because assumptions about image content, image data format and image interpretation are often very different. Also, the correlation of reference metrics and human perception of quality can vary strongly for different kinds of distortions and commonly used metrics, such as SSIM, PSNR and MAE are not the best choice for all situations. We selected five pitfalls that showcase unexpected and probably undesired reference metric scores and discuss strategies to avoid them.
Similarity Metrics for MR Image-To-Image Translation
May 15, 2024Image-to-image translation can create large impact in medical imaging, i.e. if images of a patient can be translated to another modality, type or sequence for better diagnosis. However, these methods must be validated by human reader studies, which are costly and restricted to small samples. Automatic evaluation of large samples to pre-evaluate and continuously improve methods before human validation is needed. In this study, we give an overview of reference and non-reference metrics for image synthesis assessment and investigate the ability of nine metrics, that need a reference (SSIM, MS-SSIM, PSNR, MSE, NMSE, MAE, LPIPS, NMI and PCC) and three non-reference metrics (BLUR, MSN, MNG) to detect 11 kinds of distortions in MR images from the BraSyn dataset. In addition we test a downstream segmentation metric and the effect of three normalization methods (Minmax, cMinMax and Zscore). Although PSNR and SSIM are frequently used to evaluate generative models for image-to-image-translation tasks in the medical domain, they show very specific shortcomings. SSIM ignores blurring but is very sensitive to intensity shifts in unnormalized MR images. PSNR is even more sensitive to different normalization methods and hardly measures the degree of distortions. Further metrics, such as LPIPS, NMI and DICE can be very useful to evaluate other similarity aspects. If the images to be compared are misaligned, most metrics are flawed. By carefully selecting and reasonably combining image similarity metrics, the training and selection of generative models for MR image synthesis can be improved. Many aspects of their output can be validated before final and costly evaluation by trained radiologists is conducted.
Uncertainty Estimation in Contrast-Enhanced MR Image Translation with Multi-Axis Fusion
Nov 20, 2023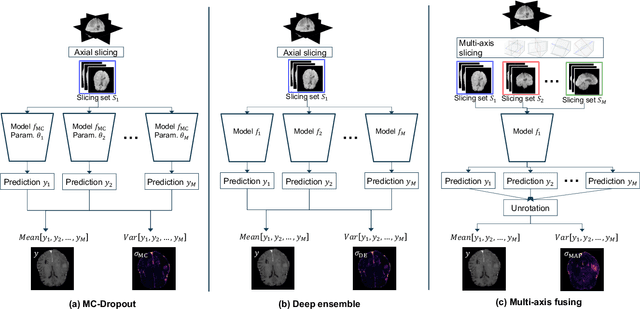
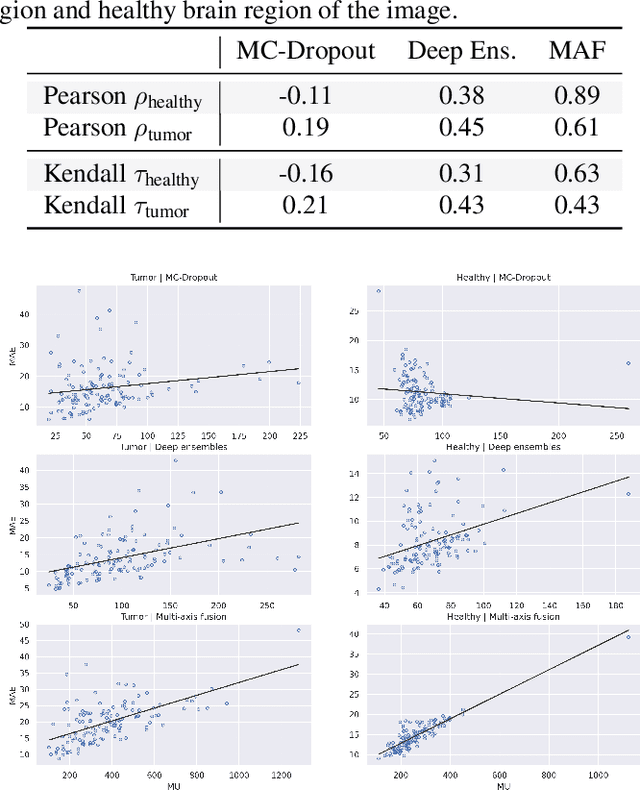
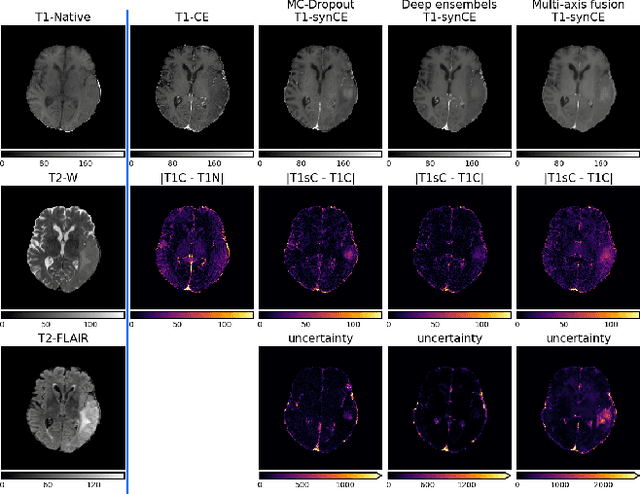
In recent years, deep learning has been applied to a wide range of medical imaging and image processing tasks. In this work, we focus on the estimation of epistemic uncertainty for 3D medical image-to-image translation. We propose a novel model uncertainty quantification method, Multi-Axis Fusion (MAF), which relies on the integration of complementary information derived from multiple views on volumetric image data. The proposed approach is applied to the task of synthesizing contrast enhanced T1-weighted images based on native T1, T2 and T2-FLAIR scans. The quantitative findings indicate a strong correlation ($\rho_{\text healthy} = 0.89$) between the mean absolute image synthetization error and the mean uncertainty score for our MAF method. Hence, we consider MAF as a promising approach to solve the highly relevant task of detecting synthetization failures at inference time.
fRegGAN with K-space Loss Regularization for Medical Image Translation
Mar 28, 2023



Generative adversarial networks (GANs) have shown remarkable success in generating realistic images and are increasingly used in medical imaging for image-to-image translation tasks. However, GANs tend to suffer from a frequency bias towards low frequencies, which can lead to the removal of important structures in the generated images. To address this issue, we propose a novel frequency-aware image-to-image translation framework based on the supervised RegGAN approach, which we call fRegGAN. The framework employs a K-space loss to regularize the frequency content of the generated images and incorporates well-known properties of MRI K-space geometry to guide the network training process. By combine our method with the RegGAN approach, we can mitigate the effect of training with misaligned data and frequency bias at the same time. We evaluate our method on the public BraTS dataset and outperform the baseline methods in terms of both quantitative and qualitative metrics when synthesizing T2-weighted from T1-weighted MR images. Detailed ablation studies are provided to understand the effect of each modification on the final performance. The proposed method is a step towards improving the performance of image-to-image translation and synthesis in the medical domain and shows promise for other applications in the field of image processing and generation.
How Shift Equivariance Impacts Metric Learning for Instance Segmentation
Jan 14, 2021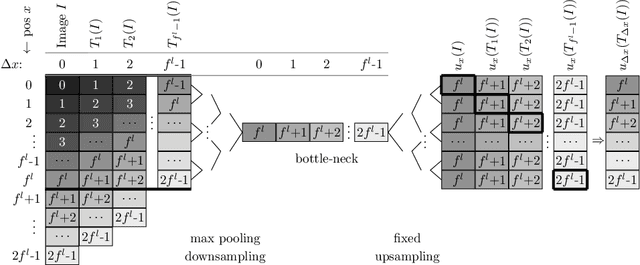

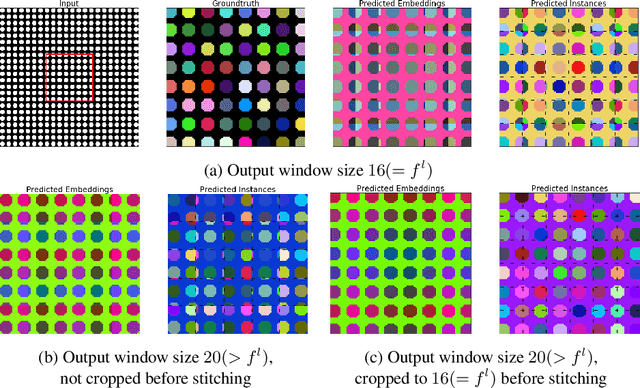

Metric learning has received conflicting assessments concerning its suitability for solving instance segmentation tasks. It has been dismissed as theoretically flawed due to the shift equivariance of the employed CNNs and their respective inability to distinguish same-looking objects. Yet it has been shown to yield state of the art results for a variety of tasks, and practical issues have mainly been reported in the context of tile-and-stitch approaches, where discontinuities at tile boundaries have been observed. To date, neither of the reported issues have undergone thorough formal analysis. In our work, we contribute a comprehensive formal analysis of the shift equivariance properties of encoder-decoder-style CNNs, which yields a clear picture of what can and cannot be achieved with metric learning in the face of same-looking objects. In particular, we prove that a standard encoder-decoder network that takes $d$-dimensional images as input, with $l$ pooling layers and pooling factor $f$, has the capacity to distinguish at most $f^{dl}$ same-looking objects, and we show that this upper limit can be reached. Furthermore, we show that to avoid discontinuities in a tile-and-stitch approach, assuming standard batch size 1, it is necessary to employ valid convolutions in combination with a training output window size strictly greater than $f^l$, while at test-time it is necessary to crop tiles to size $n\cdot f^l$ before stitching, with $n\geq 1$. We complement these theoretical findings by discussing a number of insightful special cases for which we show empirical results on synthetic data.