 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter than Average: Spatially-Aware Aggregation of Segmentation Uncertainty Improves Downstream Performance
Mar 31, 2026Uncertainty Quantification (UQ) is crucial for ensuring the reliability of automated image segmentations in safety-critical domains like biomedical image analysis or autonomous driving. In segmentation, UQ generates pixel-wise uncertainty scores that must be aggregated into image-level scores for downstream tasks like Out-of-Distribution (OoD) or failure detection. Despite routine use of aggregation strategies, their properties and impact on downstream task performance have not yet been comprehensively studied. Global Average is the default choice, yet it does not account for spatial and structural features of segmentation uncertainty. Alternatives like patch-, class- and threshold-based strategies exist, but lack systematic comparison, leading to inconsistent reporting and unclear best practices. We address this gap by (1) formally analyzing properties, limitations, and pitfalls of common strategies; (2) proposing novel strategies that incorporate spatial uncertainty structure and (3) benchmarking their performance on OoD and failure detection across ten datasets that vary in image geometry and structure. We find that aggregators leveraging spatial structure yield stronger performance in both downstream tasks studied. However, the performance of individual aggregators depends heavily on dataset characteristics, so we (4) propose a meta-aggregator that integrates multiple aggregators and performs robustly across datasets.
FISBe: A real-world benchmark dataset for instance segmentation of long-range thin filamentous structures
Mar 29, 2024



Instance segmentation of neurons in volumetric light microscopy images of nervous systems enables groundbreaking research in neuroscience by facilitating joint functional and morphological analyses of neural circuits at cellular resolution. Yet said multi-neuron light microscopy data exhibits extremely challenging properties for the task of instance segmentation: Individual neurons have long-ranging, thin filamentous and widely branching morphologies, multiple neurons are tightly inter-weaved, and partial volume effects, uneven illumination and noise inherent to light microscopy severely impede local disentangling as well as long-range tracing of individual neurons. These properties reflect a current key challenge in machine learning research, namely to effectively capture long-range dependencies in the data. While respective methodological research is buzzing, to date methods are typically benchmarked on synthetic datasets. To address this gap, we release the FlyLight Instance Segmentation Benchmark (FISBe) dataset, the first publicly available multi-neuron light microscopy dataset with pixel-wise annotations. In addition, we define a set of instance segmentation metrics for benchmarking that we designed to be meaningful with regard to downstream analyses. Lastly, we provide three baselines to kick off a competition that we envision to both advance the field of machine learning regarding methodology for capturing long-range data dependencies, and facilitate scientific discovery in basic neuroscience.
CoNIC Challenge: Pushing the Frontiers of Nuclear Detection, Segmentation, Classification and Counting
Mar 14, 2023



Nuclear detection, segmentation and morphometric profiling are essential in helping us further understand the relationship between histology and patient outcome. To drive innovation in this area, we setup a community-wide challenge using the largest available dataset of its kind to assess nuclear segmentation and cellular composition. Our challenge, named CoNIC, stimulated the development of reproducible algorithms for cellular recognition with real-time result inspection on public leaderboards. We conducted an extensive post-challenge analysis based on the top-performing models using 1,658 whole-slide images of colon tissue. With around 700 million detected nuclei per model, associated features were used for dysplasia grading and survival analysis, where we demonstrated that the challenge's improvement over the previous state-of-the-art led to significant boosts in downstream performance. Our findings also suggest that eosinophils and neutrophils play an important role in the tumour microevironment. We release challenge models and WSI-level results to foster the development of further methods for biomarker discovery.
Panoptic segmentation with highly imbalanced semantic labels
Apr 02, 2022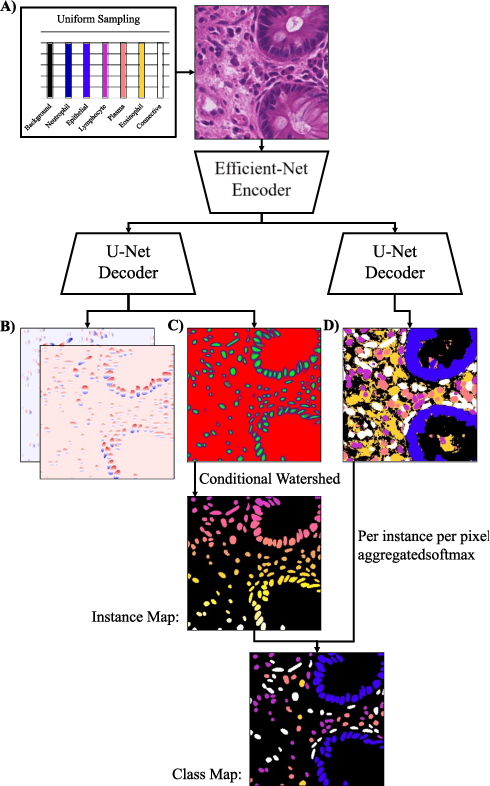
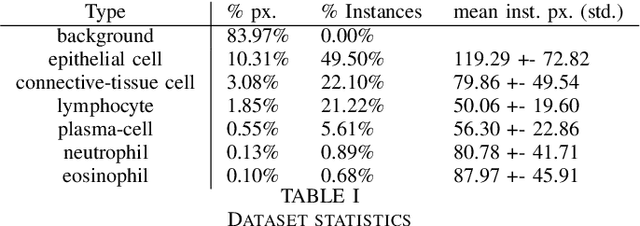
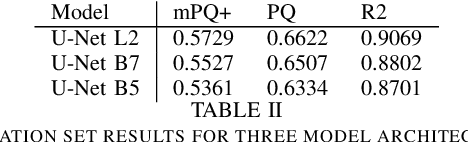
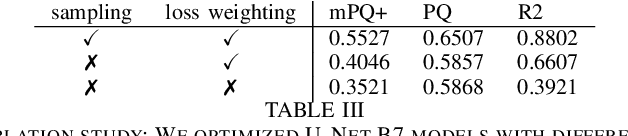
This manuscript describes the panoptic segmentation method we devised for our submission to the CONIC challenge at ISBI 2022. Key features of our method are a weighted loss that we specifically engineered for semantic segmentation of highly imbalanced cell types, and an existing state-of-the art nuclei instance segmentation model, which we combine in a Hovernet-like architecture.
How Shift Equivariance Impacts Metric Learning for Instance Segmentation
Jan 14, 2021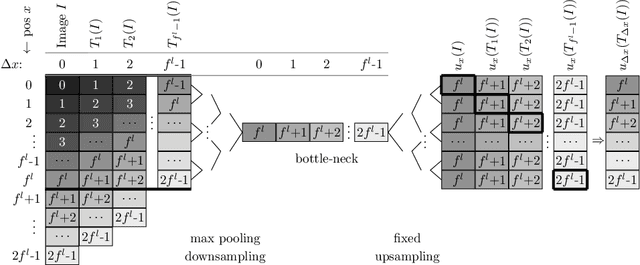

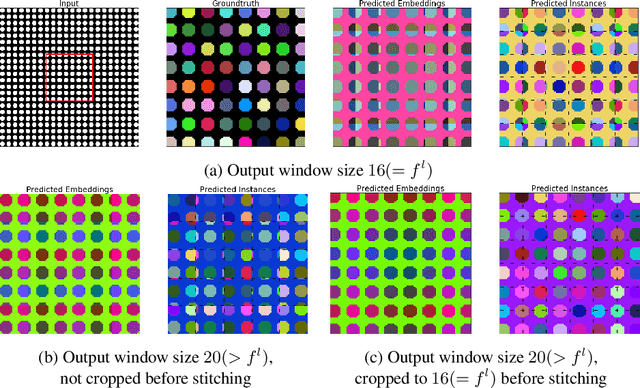

Metric learning has received conflicting assessments concerning its suitability for solving instance segmentation tasks. It has been dismissed as theoretically flawed due to the shift equivariance of the employed CNNs and their respective inability to distinguish same-looking objects. Yet it has been shown to yield state of the art results for a variety of tasks, and practical issues have mainly been reported in the context of tile-and-stitch approaches, where discontinuities at tile boundaries have been observed. To date, neither of the reported issues have undergone thorough formal analysis. In our work, we contribute a comprehensive formal analysis of the shift equivariance properties of encoder-decoder-style CNNs, which yields a clear picture of what can and cannot be achieved with metric learning in the face of same-looking objects. In particular, we prove that a standard encoder-decoder network that takes $d$-dimensional images as input, with $l$ pooling layers and pooling factor $f$, has the capacity to distinguish at most $f^{dl}$ same-looking objects, and we show that this upper limit can be reached. Furthermore, we show that to avoid discontinuities in a tile-and-stitch approach, assuming standard batch size 1, it is necessary to employ valid convolutions in combination with a training output window size strictly greater than $f^l$, while at test-time it is necessary to crop tiles to size $n\cdot f^l$ before stitching, with $n\geq 1$. We complement these theoretical findings by discussing a number of insightful special cases for which we show empirical results on synthetic data.
Probabilistic Deep Learning for Instance Segmentation
Aug 24, 2020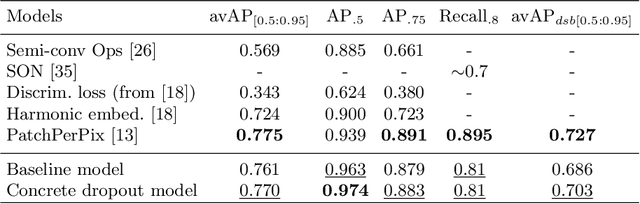

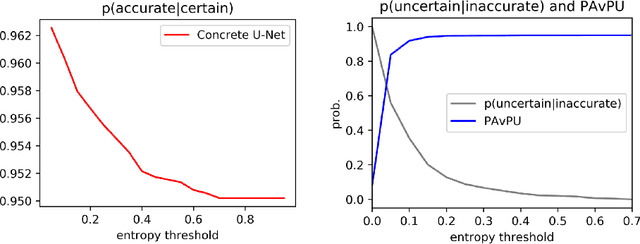
Probabilistic convolutional neural networks, which predict distributions of predictions instead of point estimates, led to recent advances in many areas of computer vision, from image reconstruction to semantic segmentation. Besides state of the art benchmark results, these networks made it possible to quantify local uncertainties in the predictions. These were used in active learning frameworks to target the labeling efforts of specialist annotators or to assess the quality of a prediction in a safety-critical environment. However, for instance segmentation problems these methods are not frequently used so far. We seek to close this gap by proposing a generic method to obtain model-inherent uncertainty estimates within proposal-free instance segmentation models. Furthermore, we analyze the quality of the uncertainty estimates with a metric adapted from semantic segmentation. We evaluate our method on the BBBC010 C.\ elegans dataset, where it yields competitive performance while also predicting uncertainty estimates that carry information about object-level inaccuracies like false splits and false merges. We perform a simulation to show the potential use of such uncertainty estimates in guided proofreading.
State of the Art in Fair ML: From Moral Philosophy and Legislation to Fair Classifiers
Nov 20, 2018
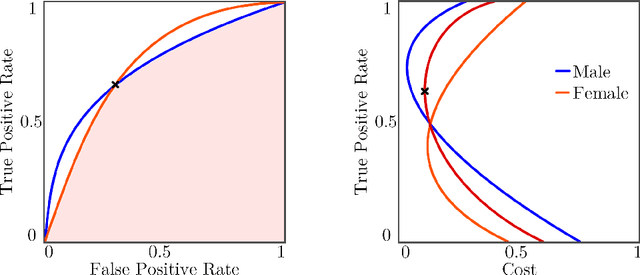
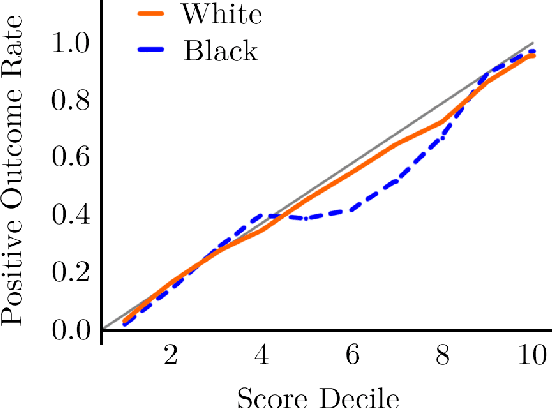
Machine learning is becoming an ever present part in our lives as many decisions, e.g. to lend a credit, are no longer made by humans but by machine learning algorithms. However those decisions are often unfair and discriminating individuals belonging to protected groups based on race or gender. With the recent General Data Protection Regulation (GDPR) coming into effect, new awareness has been raised for such issues and with computer scientists having such a large impact on peoples lives it is necessary that actions are taken to discover and prevent discrimination. This work aims to give an introduction into discrimination, legislative foundations to counter it and strategies to detect and prevent machine learning algorithms from showing such behavior.