 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Unsupervised Annotation of C. Elegans
Mar 10, 2025In this work we present a novel approach for unsupervised multi-graph matching, which applies to problems for which a Gaussian distribution of keypoint features can be assumed. We leverage cycle consistency as loss for self-supervised learning, and determine Gaussian parameters through Bayesian Optimization, yielding a highly efficient approach that scales to large datasets. Our fully unsupervised approach enables us to reach the accuracy of state-of-the-art supervised methodology for the use case of annotating cell nuclei in 3D microscopy images of the worm C. elegans. To this end, our approach yields the first unsupervised atlas of C. elegans, i.e. a model of the joint distribution of all of its cell nuclei, without the need for any ground truth cell annotation. This advancement enables highly efficient annotation of cell nuclei in large microscopy datasets of C. elegans. Beyond C. elegans, our approach offers fully unsupervised construction of cell-level atlases for any model organism with a stereotyped cell lineage, and thus bears the potential to catalyze respective comparative developmental studies in a range of further species.
Arctique: An artificial histopathological dataset unifying realism and controllability for uncertainty quantification
Nov 11, 2024



Uncertainty Quantification (UQ) is crucial for reliable image segmentation. Yet, while the field sees continual development of novel methods, a lack of agreed-upon benchmarks limits their systematic comparison and evaluation: Current UQ methods are typically tested either on overly simplistic toy datasets or on complex real-world datasets that do not allow to discern true uncertainty. To unify both controllability and complexity, we introduce Arctique, a procedurally generated dataset modeled after histopathological colon images. We chose histopathological images for two reasons: 1) their complexity in terms of intricate object structures and highly variable appearance, which yields challenging segmentation problems, and 2) their broad prevalence for medical diagnosis and respective relevance of high-quality UQ. To generate Arctique, we established a Blender-based framework for 3D scene creation with intrinsic noise manipulation. Arctique contains 50,000 rendered images with precise masks as well as noisy label simulations. We show that by independently controlling the uncertainty in both images and labels, we can effectively study the performance of several commonly used UQ methods. Hence, Arctique serves as a critical resource for benchmarking and advancing UQ techniques and other methodologies in complex, multi-object environments, bridging the gap between realism and controllability. All code is publicly available, allowing re-creation and controlled manipulations of our shipped images as well as creation and rendering of new scenes.
Model Guidance via Explanations Turns Image Classifiers into Segmentation Models
Jul 03, 2024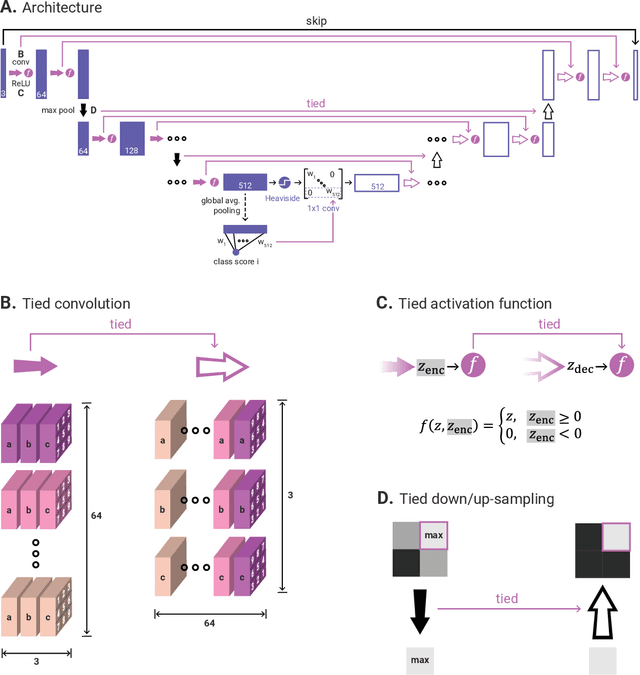
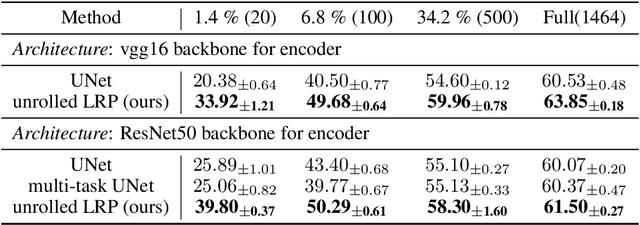

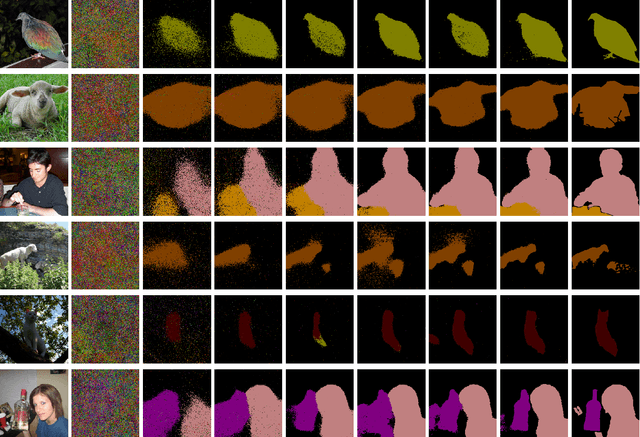
Heatmaps generated on inputs of image classification networks via explainable AI methods like Grad-CAM and LRP have been observed to resemble segmentations of input images in many cases. Consequently, heatmaps have also been leveraged for achieving weakly supervised segmentation with image-level supervision. On the other hand, losses can be imposed on differentiable heatmaps, which has been shown to serve for (1)~improving heatmaps to be more human-interpretable, (2)~regularization of networks towards better generalization, (3)~training diverse ensembles of networks, and (4)~for explicitly ignoring confounding input features. Due to the latter use case, the paradigm of imposing losses on heatmaps is often referred to as "Right for the right reasons". We unify these two lines of research by investigating semi-supervised segmentation as a novel use case for the Right for the Right Reasons paradigm. First, we show formal parallels between differentiable heatmap architectures and standard encoder-decoder architectures for image segmentation. Second, we show that such differentiable heatmap architectures yield competitive results when trained with standard segmentation losses. Third, we show that such architectures allow for training with weak supervision in the form of image-level labels and small numbers of pixel-level labels, outperforming comparable encoder-decoder models. Code is available at \url{https://github.com/Kainmueller-Lab/TW-autoencoder}.
FISBe: A real-world benchmark dataset for instance segmentation of long-range thin filamentous structures
Mar 29, 2024



Instance segmentation of neurons in volumetric light microscopy images of nervous systems enables groundbreaking research in neuroscience by facilitating joint functional and morphological analyses of neural circuits at cellular resolution. Yet said multi-neuron light microscopy data exhibits extremely challenging properties for the task of instance segmentation: Individual neurons have long-ranging, thin filamentous and widely branching morphologies, multiple neurons are tightly inter-weaved, and partial volume effects, uneven illumination and noise inherent to light microscopy severely impede local disentangling as well as long-range tracing of individual neurons. These properties reflect a current key challenge in machine learning research, namely to effectively capture long-range dependencies in the data. While respective methodological research is buzzing, to date methods are typically benchmarked on synthetic datasets. To address this gap, we release the FlyLight Instance Segmentation Benchmark (FISBe) dataset, the first publicly available multi-neuron light microscopy dataset with pixel-wise annotations. In addition, we define a set of instance segmentation metrics for benchmarking that we designed to be meaningful with regard to downstream analyses. Lastly, we provide three baselines to kick off a competition that we envision to both advance the field of machine learning regarding methodology for capturing long-range data dependencies, and facilitate scientific discovery in basic neuroscience.
Towards Hierarchical Regional Transformer-based Multiple Instance Learning
Aug 24, 2023



The classification of gigapixel histopathology images with deep multiple instance learning models has become a critical task in digital pathology and precision medicine. In this work, we propose a Transformer-based multiple instance learning approach that replaces the traditional learned attention mechanism with a regional, Vision Transformer inspired self-attention mechanism. We present a method that fuses regional patch information to derive slide-level predictions and show how this regional aggregation can be stacked to hierarchically process features on different distance levels. To increase predictive accuracy, especially for datasets with small, local morphological features, we introduce a method to focus the image processing on high attention regions during inference. Our approach is able to significantly improve performance over the baseline on two histopathology datasets and points towards promising directions for further research.
CoNIC Challenge: Pushing the Frontiers of Nuclear Detection, Segmentation, Classification and Counting
Mar 14, 2023



Nuclear detection, segmentation and morphometric profiling are essential in helping us further understand the relationship between histology and patient outcome. To drive innovation in this area, we setup a community-wide challenge using the largest available dataset of its kind to assess nuclear segmentation and cellular composition. Our challenge, named CoNIC, stimulated the development of reproducible algorithms for cellular recognition with real-time result inspection on public leaderboards. We conducted an extensive post-challenge analysis based on the top-performing models using 1,658 whole-slide images of colon tissue. With around 700 million detected nuclei per model, associated features were used for dysplasia grading and survival analysis, where we demonstrated that the challenge's improvement over the previous state-of-the-art led to significant boosts in downstream performance. Our findings also suggest that eosinophils and neutrophils play an important role in the tumour microevironment. We release challenge models and WSI-level results to foster the development of further methods for biomarker discovery.
Understanding metric-related pitfalls in image analysis validation
Feb 09, 2023Validation metrics are key for the reliable tracking of scientific progress and for bridging the current chasm between artificial intelligence (AI) research and its translation into practice. However, increasing evidence shows that particularly in image analysis, metrics are often chosen inadequately in relation to the underlying research problem. This could be attributed to a lack of accessibility of metric-related knowledge: While taking into account the individual strengths, weaknesses, and limitations of validation metrics is a critical prerequisite to making educated choices, the relevant knowledge is currently scattered and poorly accessible to individual researchers. Based on a multi-stage Delphi process conducted by a multidisciplinary expert consortium as well as extensive community feedback, the present work provides the first reliable and comprehensive common point of access to information on pitfalls related to validation metrics in image analysis. Focusing on biomedical image analysis but with the potential of transfer to other fields, the addressed pitfalls generalize across application domains and are categorized according to a newly created, domain-agnostic taxonomy. To facilitate comprehension, illustrations and specific examples accompany each pitfall. As a structured body of information accessible to researchers of all levels of expertise, this work enhances global comprehension of a key topic in image analysis validation.
Tracking by weakly-supervised learning and graph optimization for whole-embryo C. elegans lineages
Aug 24, 2022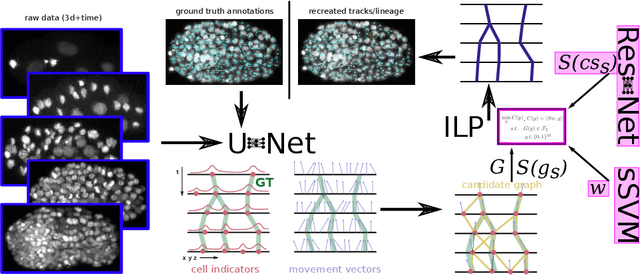
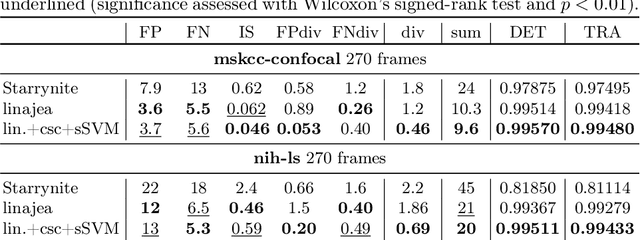
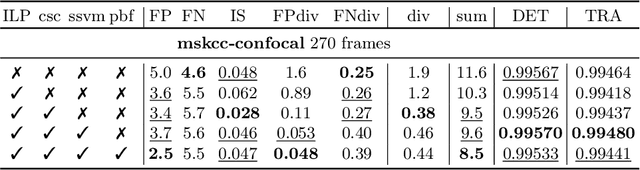
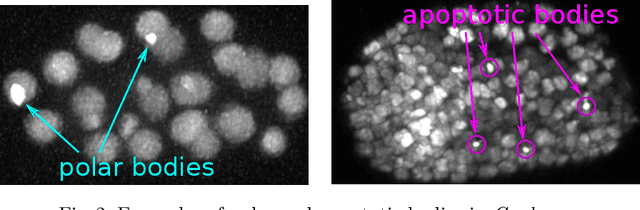
Tracking all nuclei of an embryo in noisy and dense fluorescence microscopy data is a challenging task. We build upon a recent method for nuclei tracking that combines weakly-supervised learning from a small set of nuclei center point annotations with an integer linear program (ILP) for optimal cell lineage extraction. Our work specifically addresses the following challenging properties of C. elegans embryo recordings: (1) Many cell divisions as compared to benchmark recordings of other organisms, and (2) the presence of polar bodies that are easily mistaken as cell nuclei. To cope with (1), we devise and incorporate a learnt cell division detector. To cope with (2), we employ a learnt polar body detector. We further propose automated ILP weights tuning via a structured SVM, alleviating the need for tedious manual set-up of a respective grid search. Our method outperforms the previous leader of the cell tracking challenge on the Fluo-N3DH-CE embryo dataset. We report a further extensive quantitative evaluation on two more C. elegans datasets. We will make these datasets public to serve as an extended benchmark for future method development. Our results suggest considerable improvements yielded by our method, especially in terms of the correctness of division event detection and the number and length of fully correct track segments. Code: https://github.com/funkelab/linajea
Panoptic segmentation with highly imbalanced semantic labels
Apr 02, 2022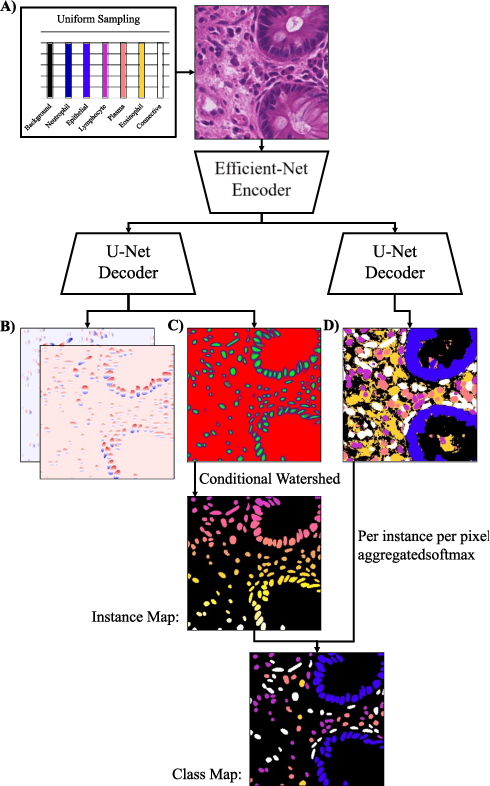
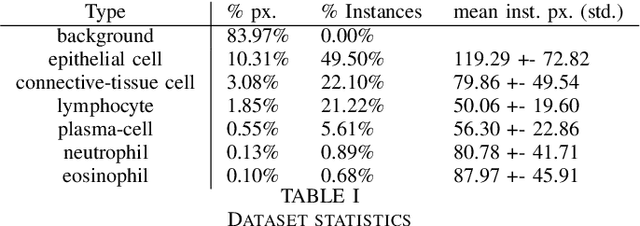
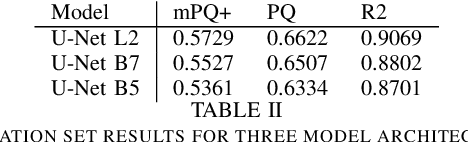
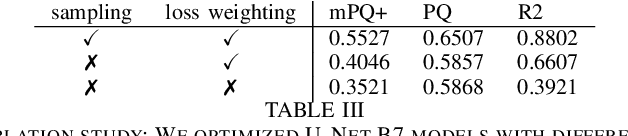
This manuscript describes the panoptic segmentation method we devised for our submission to the CONIC challenge at ISBI 2022. Key features of our method are a weighted loss that we specifically engineered for semantic segmentation of highly imbalanced cell types, and an existing state-of-the art nuclei instance segmentation model, which we combine in a Hovernet-like architecture.
How Shift Equivariance Impacts Metric Learning for Instance Segmentation
Jan 14, 2021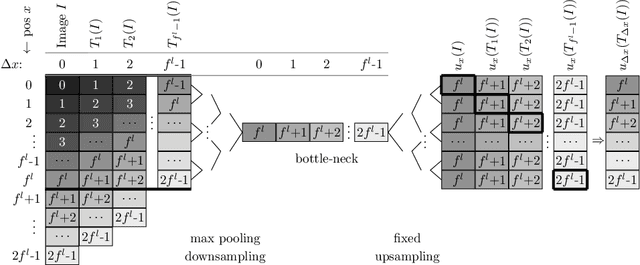

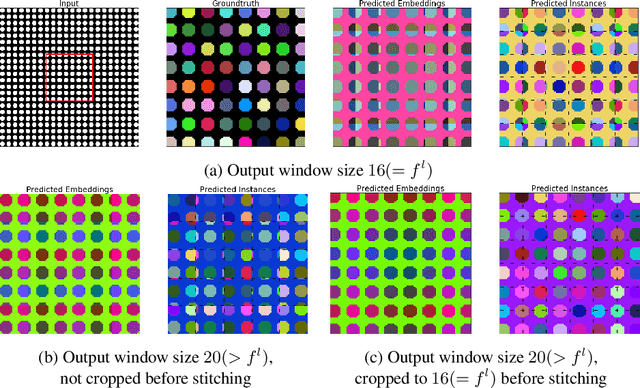

Metric learning has received conflicting assessments concerning its suitability for solving instance segmentation tasks. It has been dismissed as theoretically flawed due to the shift equivariance of the employed CNNs and their respective inability to distinguish same-looking objects. Yet it has been shown to yield state of the art results for a variety of tasks, and practical issues have mainly been reported in the context of tile-and-stitch approaches, where discontinuities at tile boundaries have been observed. To date, neither of the reported issues have undergone thorough formal analysis. In our work, we contribute a comprehensive formal analysis of the shift equivariance properties of encoder-decoder-style CNNs, which yields a clear picture of what can and cannot be achieved with metric learning in the face of same-looking objects. In particular, we prove that a standard encoder-decoder network that takes $d$-dimensional images as input, with $l$ pooling layers and pooling factor $f$, has the capacity to distinguish at most $f^{dl}$ same-looking objects, and we show that this upper limit can be reached. Furthermore, we show that to avoid discontinuities in a tile-and-stitch approach, assuming standard batch size 1, it is necessary to employ valid convolutions in combination with a training output window size strictly greater than $f^l$, while at test-time it is necessary to crop tiles to size $n\cdot f^l$ before stitching, with $n\geq 1$. We complement these theoretical findings by discussing a number of insightful special cases for which we show empirical results on synthetic data.