 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
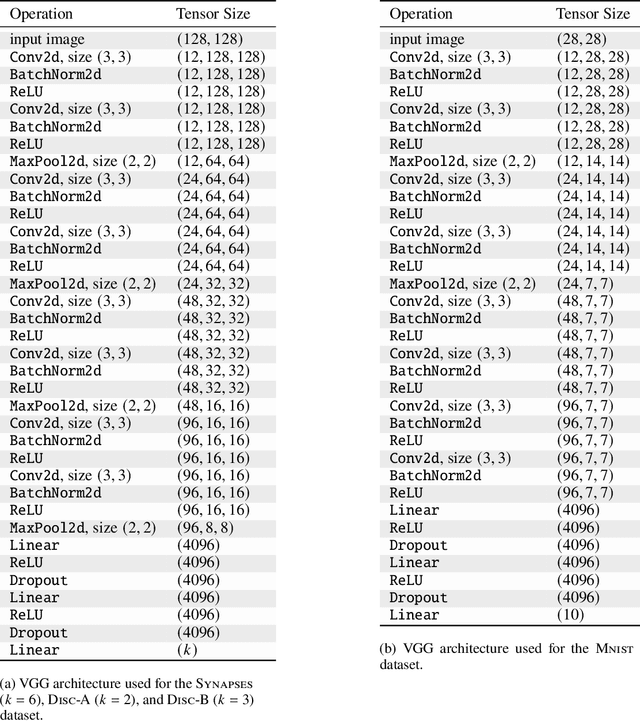
Add to EdgeDaCapo: a modular deep learning framework for scalable 3D image segmentation
Aug 05, 2024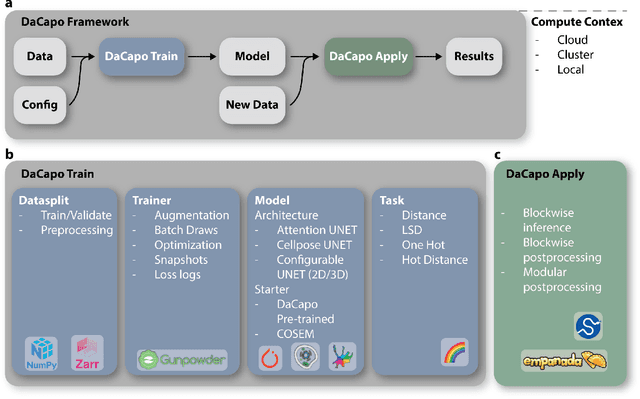
DaCapo is a specialized deep learning library tailored to expedite the training and application of existing machine learning approaches on large, near-isotropic image data. In this correspondence, we introduce DaCapo's unique features optimized for this specific domain, highlighting its modular structure, efficient experiment management tools, and scalable deployment capabilities. We discuss its potential to improve access to large-scale, isotropic image segmentation and invite the community to explore and contribute to this open-source initiative.
Unsupervised Learning of Object-Centric Embeddings for Cell Instance Segmentation in Microscopy Images
Oct 12, 2023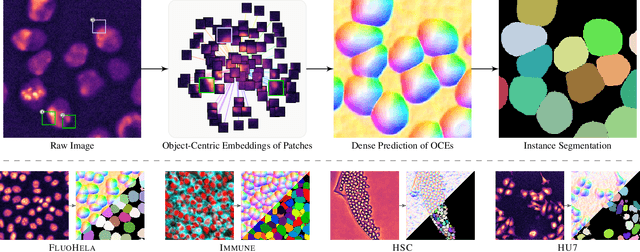
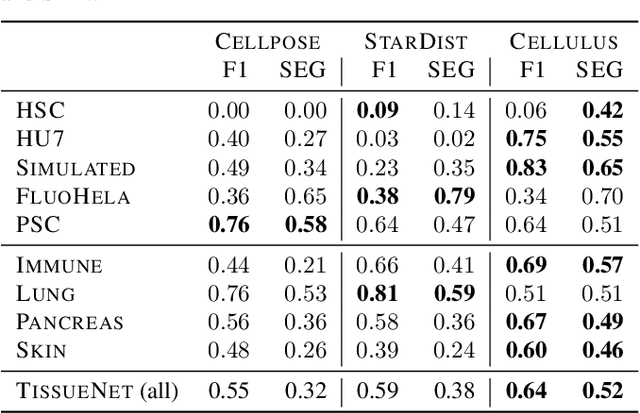
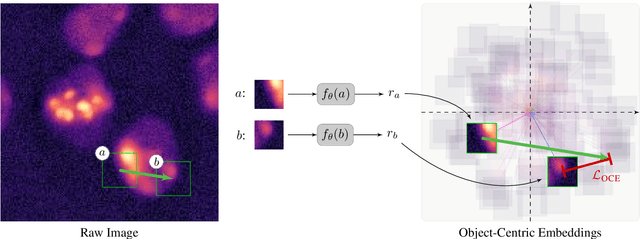
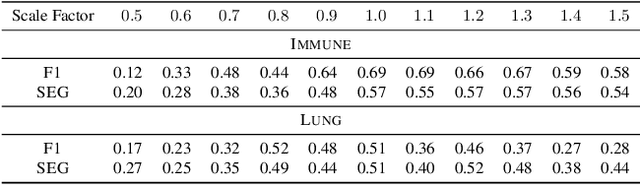
Segmentation of objects in microscopy images is required for many biomedical applications. We introduce object-centric embeddings (OCEs), which embed image patches such that the spatial offsets between patches cropped from the same object are preserved. Those learnt embeddings can be used to delineate individual objects and thus obtain instance segmentations. Here, we show theoretically that, under assumptions commonly found in microscopy images, OCEs can be learnt through a self-supervised task that predicts the spatial offset between image patches. Together, this forms an unsupervised cell instance segmentation method which we evaluate on nine diverse large-scale microscopy datasets. Segmentations obtained with our method lead to substantially improved results, compared to state-of-the-art baselines on six out of nine datasets, and perform on par on the remaining three datasets. If ground-truth annotations are available, our method serves as an excellent starting point for supervised training, reducing the required amount of ground-truth needed by one order of magnitude, thus substantially increasing the practical applicability of our method. Source code is available at https://github.com/funkelab/cellulus.
Tracking by weakly-supervised learning and graph optimization for whole-embryo C. elegans lineages
Aug 24, 2022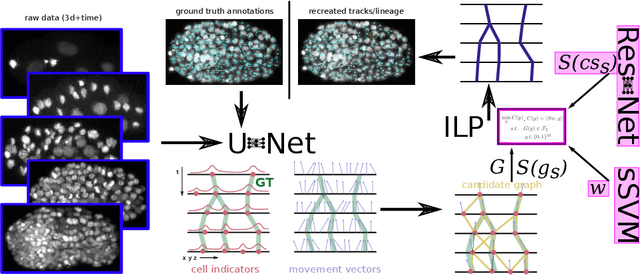
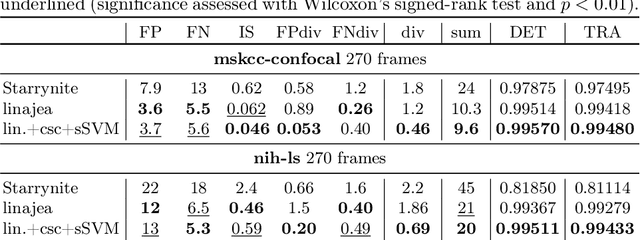
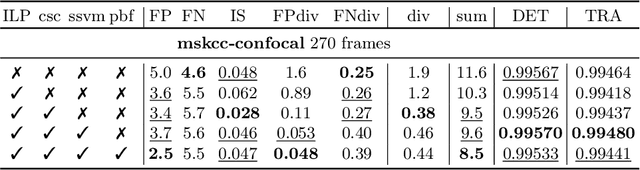
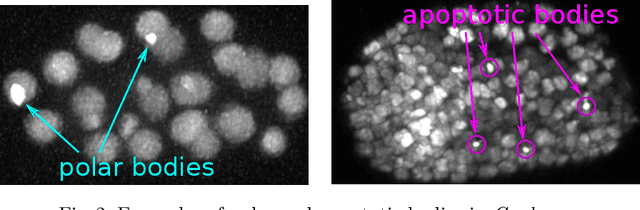
Tracking all nuclei of an embryo in noisy and dense fluorescence microscopy data is a challenging task. We build upon a recent method for nuclei tracking that combines weakly-supervised learning from a small set of nuclei center point annotations with an integer linear program (ILP) for optimal cell lineage extraction. Our work specifically addresses the following challenging properties of C. elegans embryo recordings: (1) Many cell divisions as compared to benchmark recordings of other organisms, and (2) the presence of polar bodies that are easily mistaken as cell nuclei. To cope with (1), we devise and incorporate a learnt cell division detector. To cope with (2), we employ a learnt polar body detector. We further propose automated ILP weights tuning via a structured SVM, alleviating the need for tedious manual set-up of a respective grid search. Our method outperforms the previous leader of the cell tracking challenge on the Fluo-N3DH-CE embryo dataset. We report a further extensive quantitative evaluation on two more C. elegans datasets. We will make these datasets public to serve as an extended benchmark for future method development. Our results suggest considerable improvements yielded by our method, especially in terms of the correctness of division event detection and the number and length of fully correct track segments. Code: https://github.com/funkelab/linajea
Discriminative Attribution from Counterfactuals
Sep 28, 2021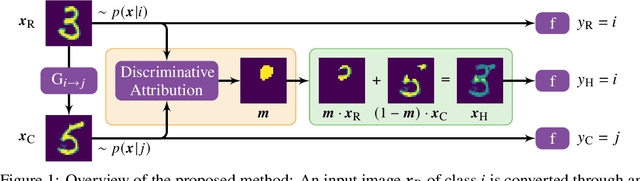
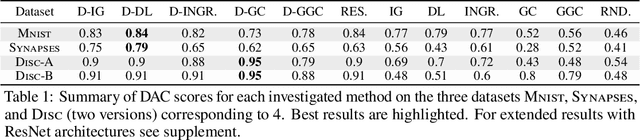
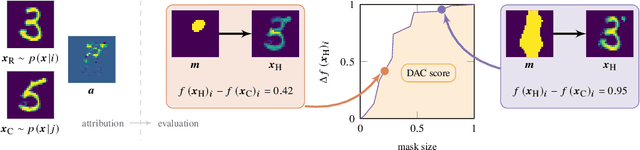
We present a method for neural network interpretability by combining feature attribution with counterfactual explanations to generate attribution maps that highlight the most discriminative features between pairs of classes. We show that this method can be used to quantitatively evaluate the performance of feature attribution methods in an objective manner, thus preventing potential observer bias. We evaluate the proposed method on three diverse datasets, including a challenging artificial dataset and real-world biological data. We show quantitatively and qualitatively that the highlighted features are substantially more discriminative than those extracted using conventional attribution methods and argue that this type of explanation is better suited for understanding fine grained class differences as learned by a deep neural network.
How Shift Equivariance Impacts Metric Learning for Instance Segmentation
Jan 14, 2021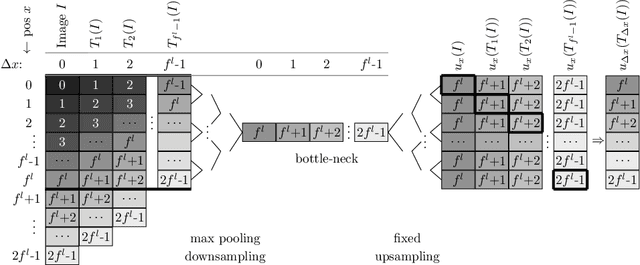

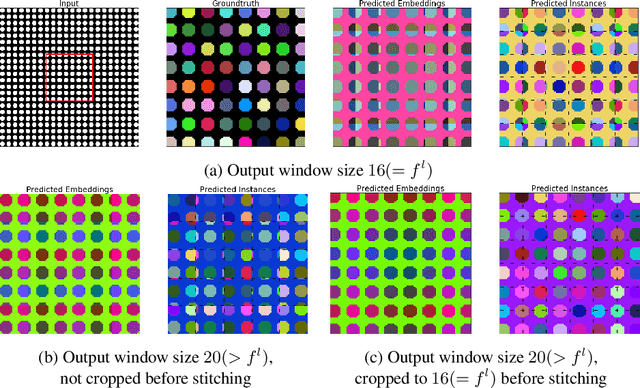

Metric learning has received conflicting assessments concerning its suitability for solving instance segmentation tasks. It has been dismissed as theoretically flawed due to the shift equivariance of the employed CNNs and their respective inability to distinguish same-looking objects. Yet it has been shown to yield state of the art results for a variety of tasks, and practical issues have mainly been reported in the context of tile-and-stitch approaches, where discontinuities at tile boundaries have been observed. To date, neither of the reported issues have undergone thorough formal analysis. In our work, we contribute a comprehensive formal analysis of the shift equivariance properties of encoder-decoder-style CNNs, which yields a clear picture of what can and cannot be achieved with metric learning in the face of same-looking objects. In particular, we prove that a standard encoder-decoder network that takes $d$-dimensional images as input, with $l$ pooling layers and pooling factor $f$, has the capacity to distinguish at most $f^{dl}$ same-looking objects, and we show that this upper limit can be reached. Furthermore, we show that to avoid discontinuities in a tile-and-stitch approach, assuming standard batch size 1, it is necessary to employ valid convolutions in combination with a training output window size strictly greater than $f^l$, while at test-time it is necessary to crop tiles to size $n\cdot f^l$ before stitching, with $n\geq 1$. We complement these theoretical findings by discussing a number of insightful special cases for which we show empirical results on synthetic data.
Microtubule Tracking in Electron Microscopy Volumes
Sep 17, 2020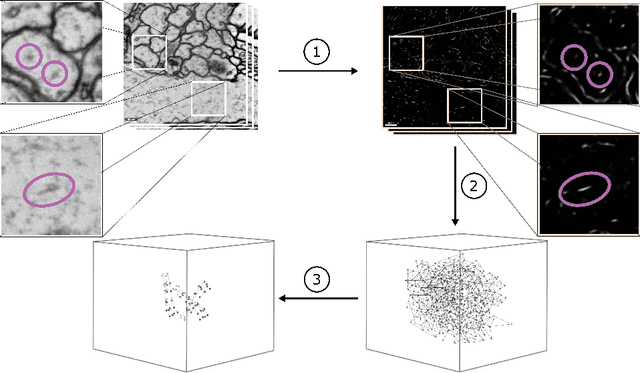
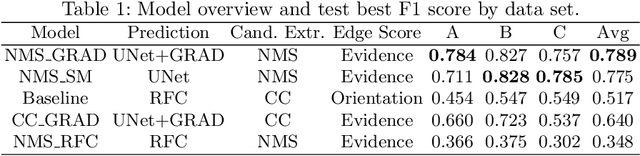
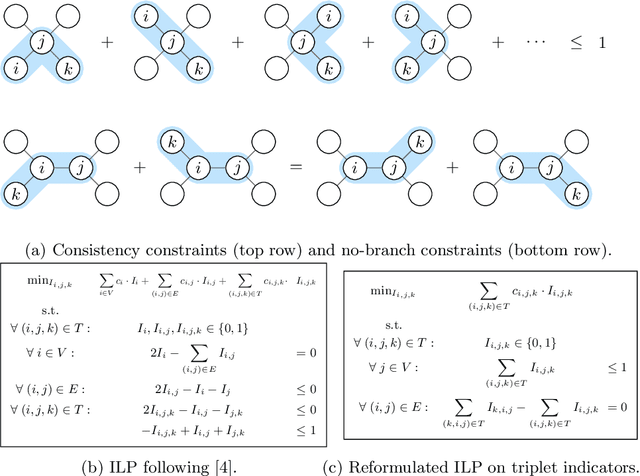
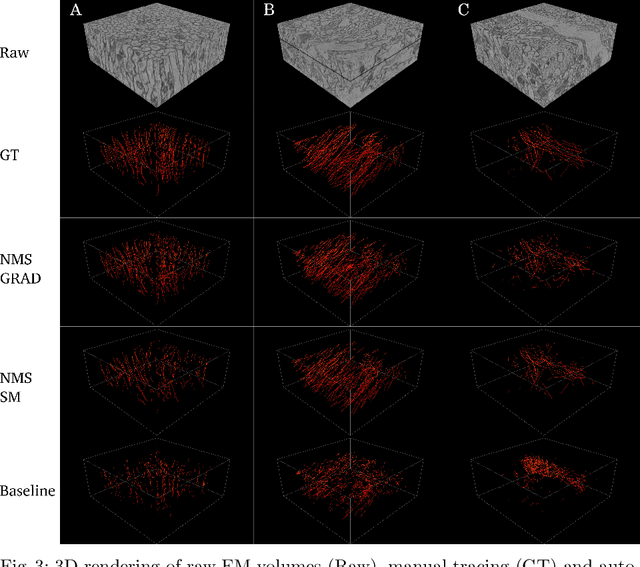
We present a method for microtubule tracking in electron microscopy volumes. Our method first identifies a sparse set of voxels that likely belong to microtubules. Similar to prior work, we then enumerate potential edges between these voxels, which we represent in a candidate graph. Tracks of microtubules are found by selecting nodes and edges in the candidate graph by solving a constrained optimization problem incorporating biological priors on microtubule structure. For this, we present a novel integer linear programming formulation, which results in speed-ups of three orders of magnitude and an increase of 53% in accuracy compared to prior art (evaluated on three 1.2 x 4 x 4$\mu$m volumes of Drosophila neural tissue). We also propose a scheme to solve the optimization problem in a block-wise fashion, which allows distributed tracking and is necessary to process very large electron microscopy volumes. Finally, we release a benchmark dataset for microtubule tracking, here used for training, testing and validation, consisting of eight 30 x 1000 x 1000 voxel blocks (1.2 x 4 x 4$\mu$m) of densely annotated microtubules in the CREMI data set (https://github.com/nilsec/micron).
Instance Separation Emerges from Inpainting
Feb 28, 2020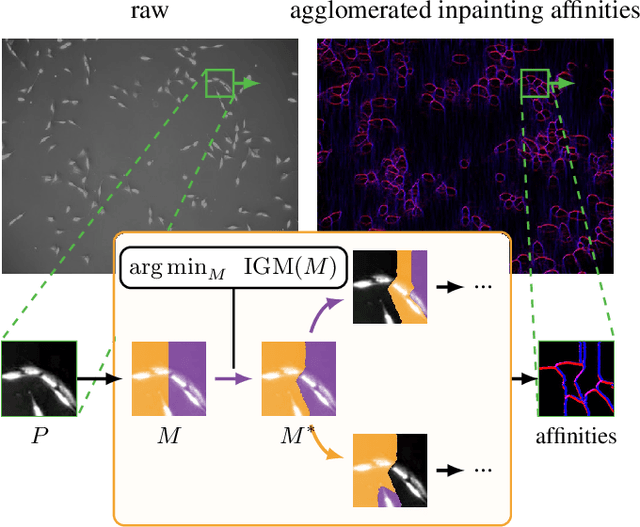

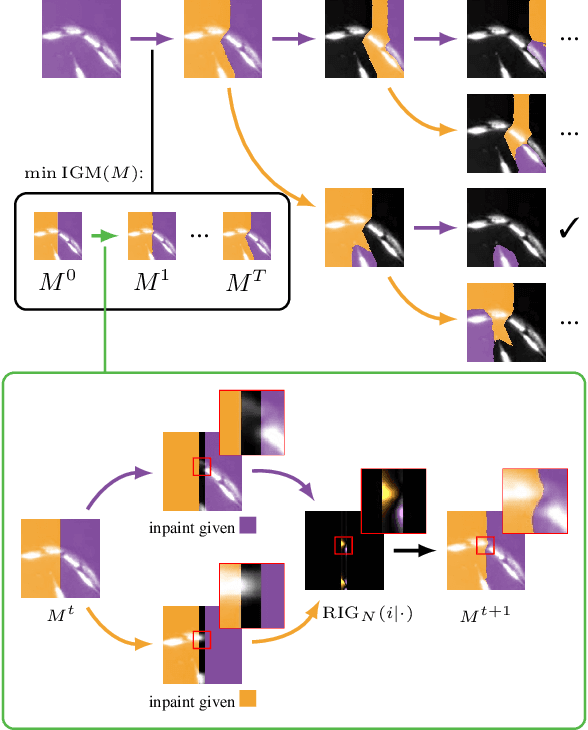

Deep neural networks trained to inpaint partially occluded images show a deep understanding of image composition and have even been shown to remove objects from images convincingly. In this work, we investigate how this implicit knowledge of image composition can be leveraged for fully self-supervised instance separation. We propose a measure for the independence of two image regions given a fully self-supervised inpainting network and separate objects by maximizing this independence. We evaluate our method on two microscopy image datasets and show that it reaches similar segmentation performance to fully supervised methods.
Synaptic partner prediction from point annotations in insect brains
Jul 16, 2018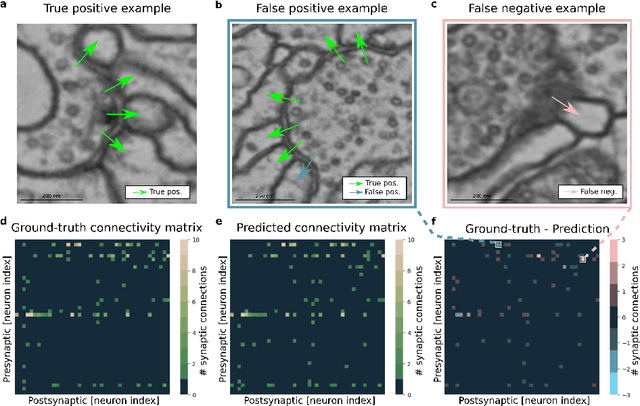
High-throughput electron microscopy allows recording of lar- ge stacks of neural tissue with sufficient resolution to extract the wiring diagram of the underlying neural network. Current efforts to automate this process focus mainly on the segmentation of neurons. However, in order to recover a wiring diagram, synaptic partners need to be identi- fied as well. This is especially challenging in insect brains like Drosophila melanogaster, where one presynaptic site is associated with multiple post- synaptic elements. Here we propose a 3D U-Net architecture to directly identify pairs of voxels that are pre- and postsynaptic to each other. To that end, we formulate the problem of synaptic partner identification as a classification problem on long-range edges between voxels to encode both the presence of a synaptic pair and its direction. This formulation allows us to directly learn from synaptic point annotations instead of more ex- pensive voxel-based synaptic cleft or vesicle annotations. We evaluate our method on the MICCAI 2016 CREMI challenge and improve over the current state of the art, producing 3% fewer errors than the next best method.
Synaptic Cleft Segmentation in Non-Isotropic Volume Electron Microscopy of the Complete Drosophila Brain
May 07, 2018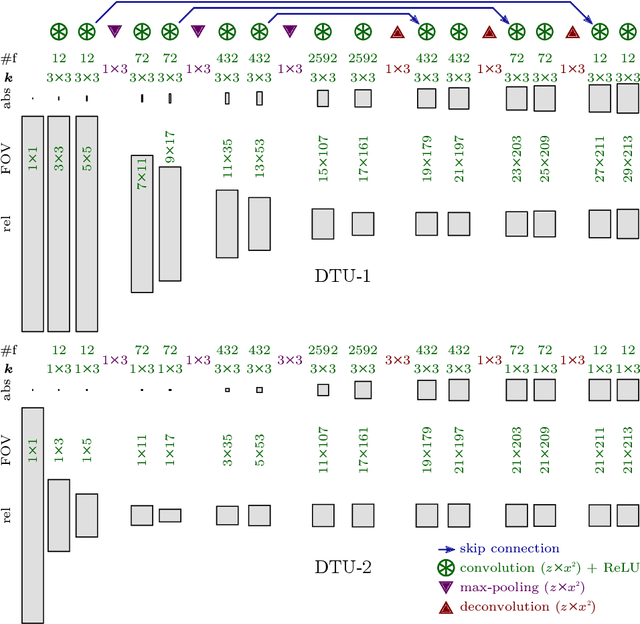
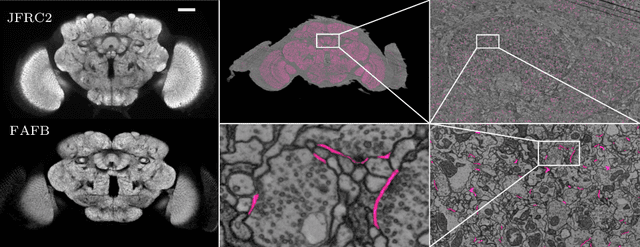
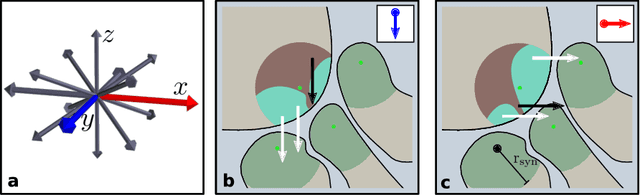
Neural circuit reconstruction at single synapse resolution is increasingly recognized as crucially important to decipher the function of biological nervous systems. Volume electron microscopy in serial transmission or scanning mode has been demonstrated to provide the necessary resolution to segment or trace all neurites and to annotate all synaptic connections. Automatic annotation of synaptic connections has been done successfully in near isotropic electron microscopy of vertebrate model organisms. Results on non-isotropic data in insect models, however, are not yet on par with human annotation. We designed a new 3D-U-Net architecture to optimally represent isotropic fields of view in non-isotropic data. We used regression on a signed distance transform of manually annotated synaptic clefts of the CREMI challenge dataset to train this model and observed significant improvement over the state of the art. We developed open source software for optimized parallel prediction on very large volumetric datasets and applied our model to predict synaptic clefts in a 50 tera-voxels dataset of the complete Drosophila brain. Our model generalizes well to areas far away from where training data was available.
A Deep Structured Learning Approach Towards Automating Connectome Reconstruction from 3D Electron Micrographs
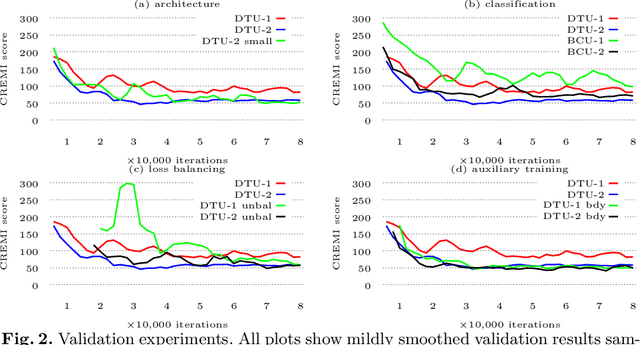
Sep 24, 2017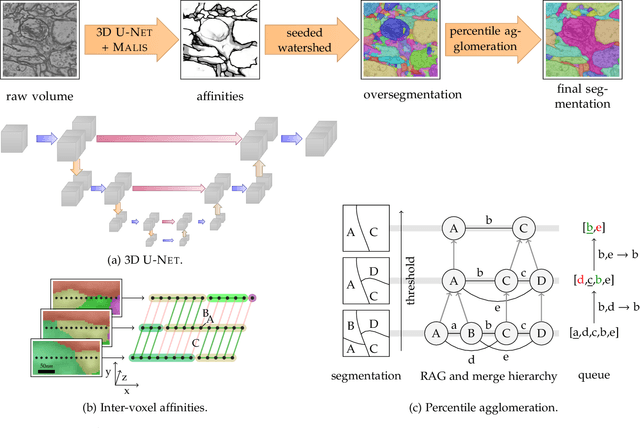

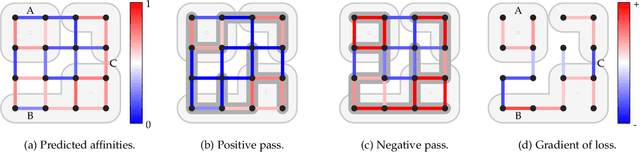

We present a deep structured learning method for neuron segmentation from 3D electron microscopy (EM) which improves significantly upon the state of the art in terms of accuracy and scalability. Our method consists of a 3D U-Net classifier predicting affinity graphs on voxels, followed by iterative region agglomeration. We train the U-Net using a new structured loss based on MALIS that encourages topological correctness. Our extension consists of two parts: First, an $O(n\log(n))$ method to compute the loss gradient, improving over the originally proposed $O(n^2)$ algorithm. Second, we compute the gradient in two separate passes to avoid spurious contributions in early training stages. Our affinity predictions are accurate enough that simple agglomeration outperforms more involved methods used earlier on inferior predictions. We present results on three datasets (CREMI, FIB, and SegEM) of different imaging techniques and animals and achieve improvements over previous results of 27%, 15%, and 250%. Our findings suggest that a single 3D segmentation strategy can be applied to both isotropic and anisotropic EM data. The runtime of our method scales with $O(n)$ in the size of the volume and achieves a throughput of about 2.6 seconds per megavoxel, allowing processing of very large datasets.