 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioimageAIpub: a toolbox for AI-ready bioimaging data publishing
Dec 17, 2025Modern bioimage analysis approaches are data hungry, making it necessary for researchers to scavenge data beyond those collected within their (bio)imaging facilities. In addition to scale, bioimaging datasets must be accompanied with suitable, high-quality annotations and metadata. Although established data repositories such as the Image Data Resource (IDR) and BioImage Archive offer rich metadata, their contents typically cannot be directly consumed by image analysis tools without substantial data wrangling. Such a tedious assembly and conversion of (meta)data can account for a dedicated amount of time investment for researchers, hindering the development of more powerful analysis tools. Here, we introduce BioimageAIpub, a workflow that streamlines bioimaging data conversion, enabling a seamless upload to HuggingFace, a widely used platform for sharing machine learning datasets and models.
Tiling artifacts and trade-offs of feature normalization in the segmentation of large biological images
Mar 25, 2025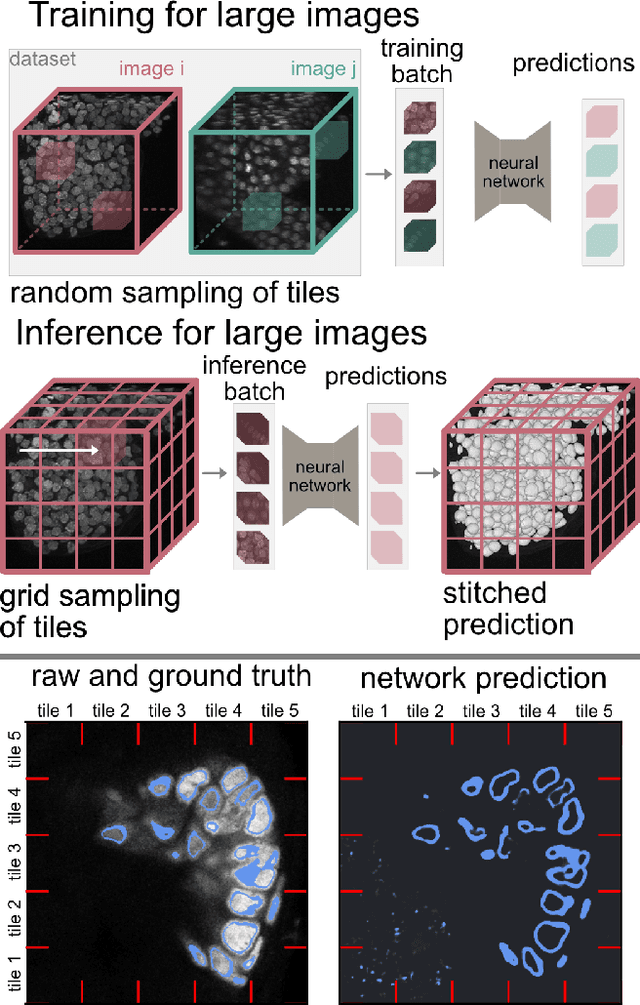
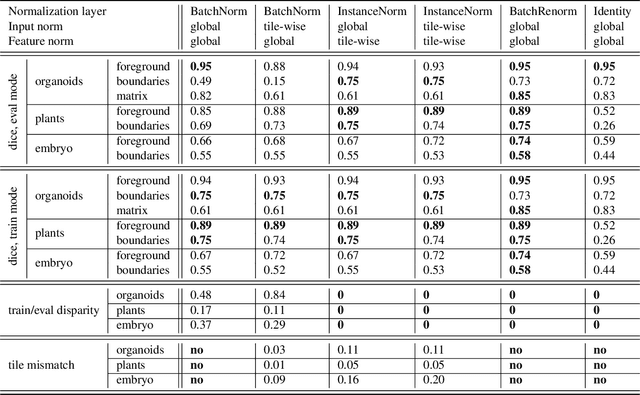
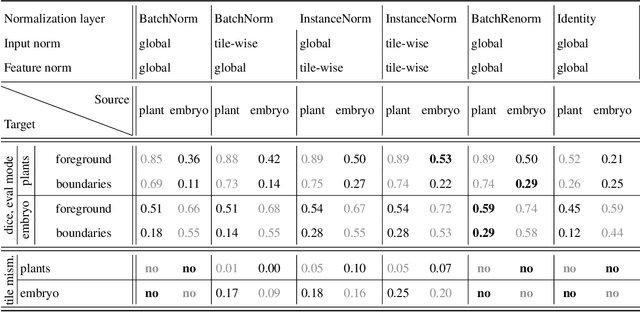
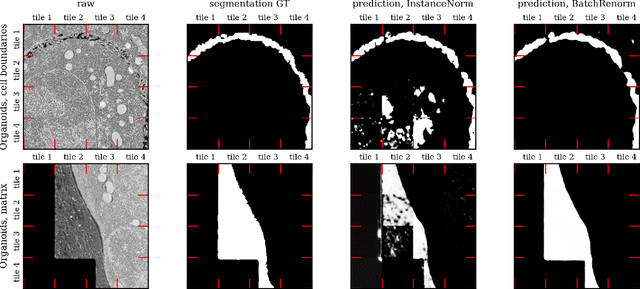
Segmentation of very large images is a common problem in microscopy, medical imaging or remote sensing. The problem is usually addressed by sliding window inference, which can theoretically lead to seamlessly stitched predictions. However, in practice many of the popular pipelines still suffer from tiling artifacts. We investigate the root cause of these issues and show that they stem from the normalization layers within the neural networks. We propose indicators to detect normalization issues and further explore the trade-offs between artifact-free and high-quality predictions, using three diverse microscopy datasets as examples. Finally, we propose to use BatchRenorm as the most suitable normalization strategy, which effectively removes tiling artifacts and enhances transfer performance, thereby improving the reusability of trained networks for new datasets.
MedicoSAM: Towards foundation models for medical image segmentation
Jan 20, 2025Medical image segmentation is an important analysis task in clinical practice and research. Deep learning has massively advanced the field, but current approaches are mostly based on models trained for a specific task. Training such models or adapting them to a new condition is costly due to the need for (manually) labeled data. The emergence of vision foundation models, especially Segment Anything, offers a path to universal segmentation for medical images, overcoming these issues. Here, we study how to improve Segment Anything for medical images by comparing different finetuning strategies on a large and diverse dataset. We evaluate the finetuned models on a wide range of interactive and (automatic) semantic segmentation tasks. We find that the performance can be clearly improved for interactive segmentation. However, semantic segmentation does not benefit from pretraining on medical images. Our best model, MedicoSAM, is publicly available at https://github.com/computational-cell-analytics/medico-sam. We show that it is compatible with existing tools for data annotation and believe that it will be of great practical value.
ViM-UNet: Vision Mamba for Biomedical Segmentation
Apr 11, 2024CNNs, most notably the UNet, are the default architecture for biomedical segmentation. Transformer-based approaches, such as UNETR, have been proposed to replace them, benefiting from a global field of view, but suffering from larger runtimes and higher parameter counts. The recent Vision Mamba architecture offers a compelling alternative to transformers, also providing a global field of view, but at higher efficiency. Here, we introduce ViM-UNet, a novel segmentation architecture based on it and compare it to UNet and UNETR for two challenging microscopy instance segmentation tasks. We find that it performs similarly or better than UNet, depending on the task, and outperforms UNETR while being more efficient. Our code is open source and documented at https://github.com/constantinpape/torch-em/blob/main/vimunet.md.
Probabilistic Domain Adaptation for Biomedical Image Segmentation
Mar 21, 2023Segmentation is a key analysis tasks in biomedical imaging. Given the many different experimental settings in this field, the lack of generalization limits the use of deep learning in practice. Domain adaptation is a promising remedy: it trains a model for a given task on a source dataset with labels and adapts it to a target dataset without additional labels. We introduce a probabilistic domain adaptation method, building on self-training approaches and the Probabilistic UNet. We use the latter to sample multiple segmentation hypothesis to implement better pseudo-label filtering. We further study joint and separate source-target training strategies and evaluate our method on three challenging domain adaptation tasks for biomedical segmentation.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Stateless actor-critic for instance segmentation with high-level priors
Jul 06, 2021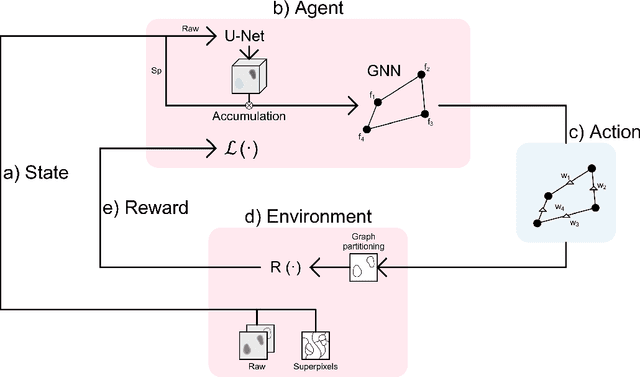


Instance segmentation is an important computer vision problem which remains challenging despite impressive recent advances due to deep learning-based methods. Given sufficient training data, fully supervised methods can yield excellent performance, but annotation of ground-truth data remains a major bottleneck, especially for biomedical applications where it has to be performed by domain experts. The amount of labels required can be drastically reduced by using rules derived from prior knowledge to guide the segmentation. However, these rules are in general not differentiable and thus cannot be used with existing methods. Here, we relax this requirement by using stateless actor critic reinforcement learning, which enables non-differentiable rewards. We formulate the instance segmentation problem as graph partitioning and the actor critic predicts the edge weights driven by the rewards, which are based on the conformity of segmented instances to high-level priors on object shape, position or size. The experiments on toy and real datasets demonstrate that we can achieve excellent performance without any direct supervision based only on a rich set of priors.
Sparse Object-level Supervision for Instance Segmentation with Pixel Embeddings
Mar 26, 2021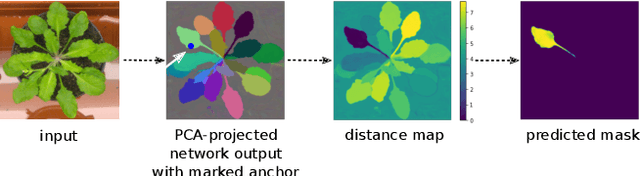

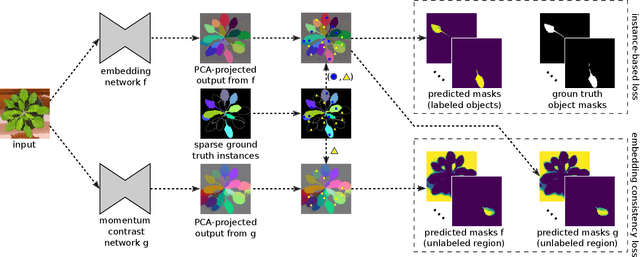

Most state-of-the-art instance segmentation methods have to be trained on densely annotated images. While difficult in general, this requirement is especially daunting for biomedical images, where domain expertise is often required for annotation. We propose to address the dense annotation bottleneck by introducing a proposal-free segmentation approach based on non-spatial embeddings, which exploits the structure of the learned embedding space to extract individual instances in a differentiable way. The segmentation loss can then be applied directly on the instances and the overall method can be trained on ground truth images where only a few objects are annotated, from scratch or in a semi-supervised transfer learning setting. In addition to the segmentation loss, our setup allows to apply self-supervised consistency losses on the unlabeled parts of the training data. We evaluate the proposed method on challenging 2D and 3D segmentation problems in different microscopy modalities as well as on the popular CVPPP instance segmentation benchmark where we achieve state-of-the-art results. The code is available at: https://github.com/kreshuklab/spoco
Proposal-Free Volumetric Instance Segmentation from Latent Single-Instance Masks
Sep 10, 2020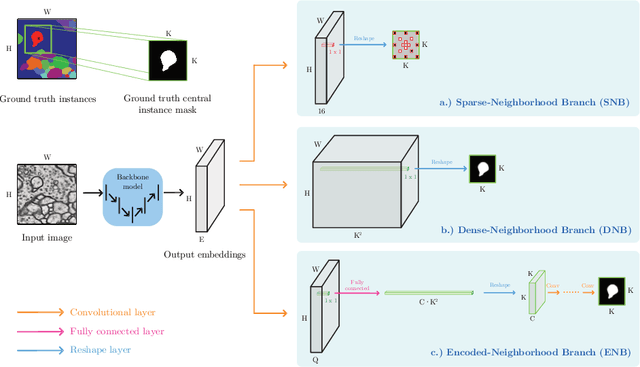
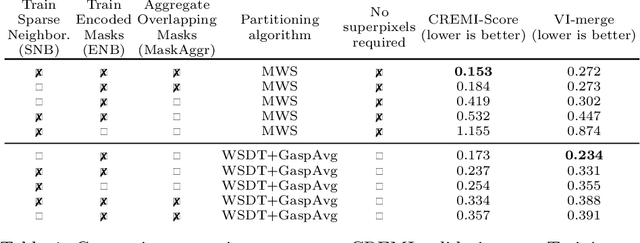

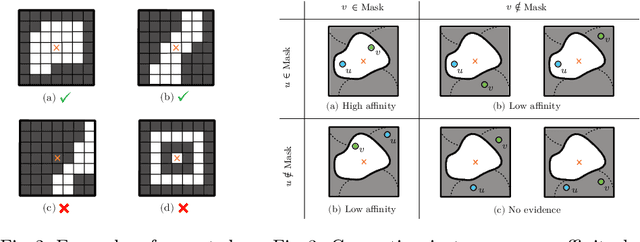
This work introduces a new proposal-free instance segmentation method that builds on single-instance segmentation masks predicted across the entire image in a sliding window style. In contrast to related approaches, our method concurrently predicts all masks, one for each pixel, and thus resolves any conflict jointly across the entire image. Specifically, predictions from overlapping masks are combined into edge weights of a signed graph that is subsequently partitioned to obtain all final instances concurrently. The result is a parameter-free method that is strongly robust to noise and prioritizes predictions with the highest consensus across overlapping masks. All masks are decoded from a low dimensional latent representation, which results in great memory savings strictly required for applications to large volumetric images. We test our method on the challenging CREMI 2016 neuron segmentation benchmark where it achieves competitive scores.
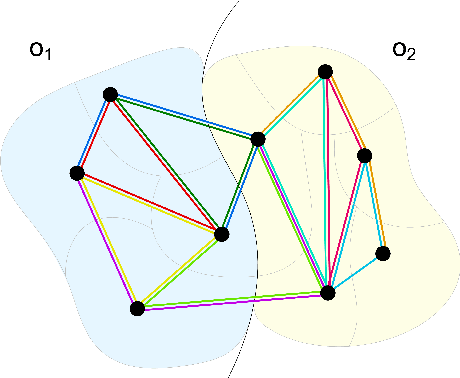
The Semantic Mutex Watershed for Efficient Bottom-Up Semantic Instance Segmentation
Dec 29, 2019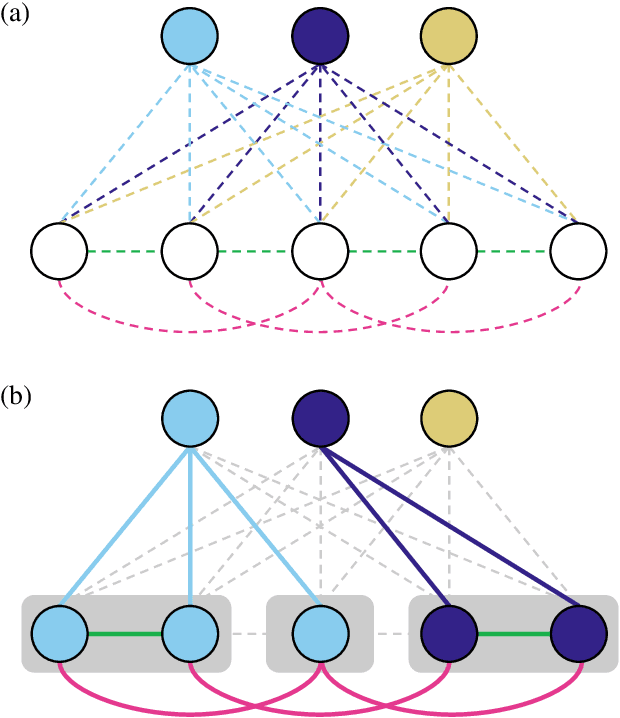


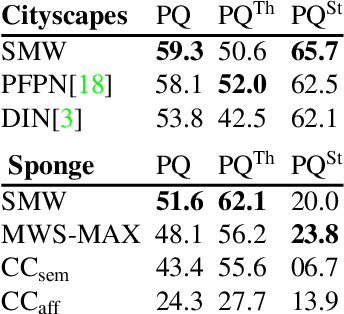
Semantic instance segmentation is the task of simultaneously partitioning an image into distinct segments while associating each pixel with a class label. In commonly used pipelines, segmentation and label assignment are solved separately since joint optimization is computationally expensive. We propose a greedy algorithm for joint graph partitioning and labeling derived from the efficient Mutex Watershed partitioning algorithm. It optimizes an objective function closely related to the Symmetric Multiway Cut objective and empirically shows efficient scaling behavior. Due to the algorithm's efficiency it can operate directly on pixels without prior over-segmentation of the image into superpixels. We evaluate the performance on the Cityscapes dataset (2D urban scenes) and on a 3D microscopy volume. In urban scenes, the proposed algorithm combined with current deep neural networks outperforms the strong baseline of `Panoptic Feature Pyramid Networks' by Kirillov et al. (2019). In the 3D electron microscopy images, we show explicitly that our joint formulation outperforms a separate optimization of the partitioning and labeling problems.