 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRL-ScanIQA: Reinforcement-Learned Scanpaths for Blind 360°Image Quality Assessment
Mar 15, 2026Blind 360°image quality assessment (IQA) aims to predict perceptual quality for panoramic images without a pristine reference. Unlike conventional planar images, 360°content in immersive environments restricts viewers to a limited viewport at any moment, making viewing behaviors critical to quality perception. Although existing scanpath-based approaches have attempted to model viewing behaviors by approximating the human view-then-rate paradigm, they treat scanpath generation and quality assessment as separate steps, preventing end-to-end optimization and task-aligned exploration. To address this limitation, we propose RL-ScanIQA, a reinforcement-learned framework for blind 360°IQA. RL-ScanIQA optimize a PPO-trained scanpath policy and a quality assessor, where the policy receives quality-driven feedback to learn task-relevant viewing strategies. To improve training stability and prevent mode collapse, we design multi-level rewards, including scanpath diversity and equator-biased priors. We further boost cross-dataset robustness using distortion-space augmentation together with rank-consistent losses that preserve intra-image and inter-image quality orderings. Extensive experiments on three benchmarks show that RL-ScanIQA achieves superior in-dataset performance and cross-dataset generalization. Codes are available at https://github.com/wangyuji1/RLScanIQA.git.
Advanced Intelligent Optimization Algorithms for Multi-Objective Optimal Power Flow in Future Power Systems: A Review
Apr 14, 2024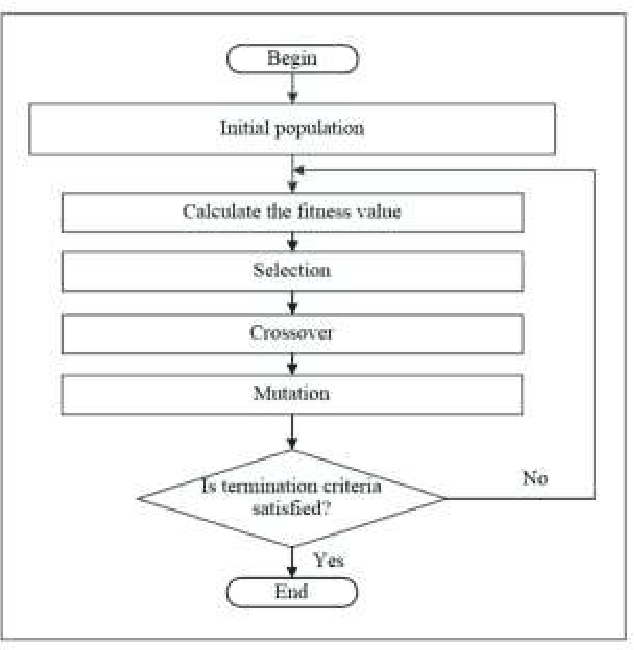
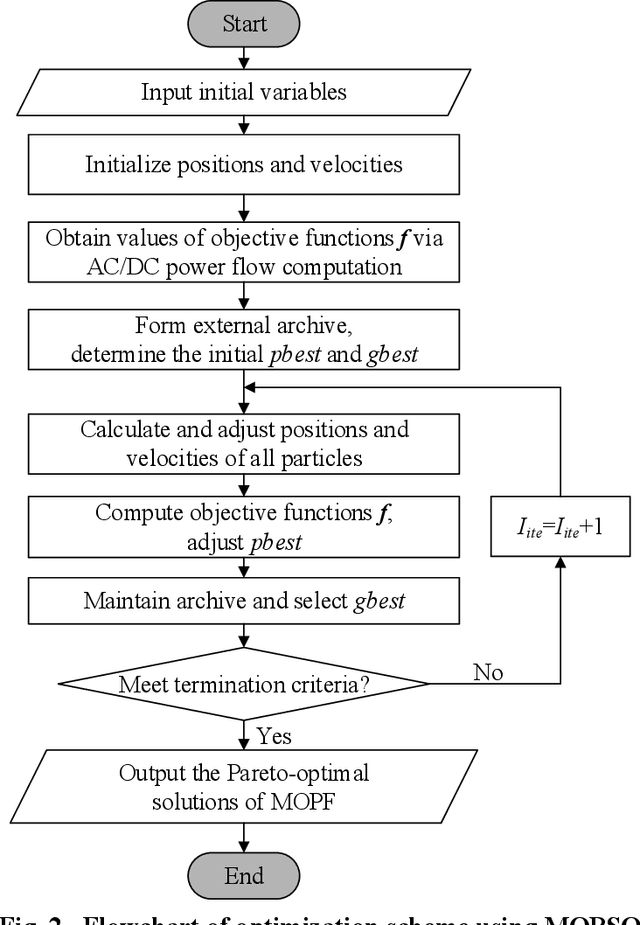
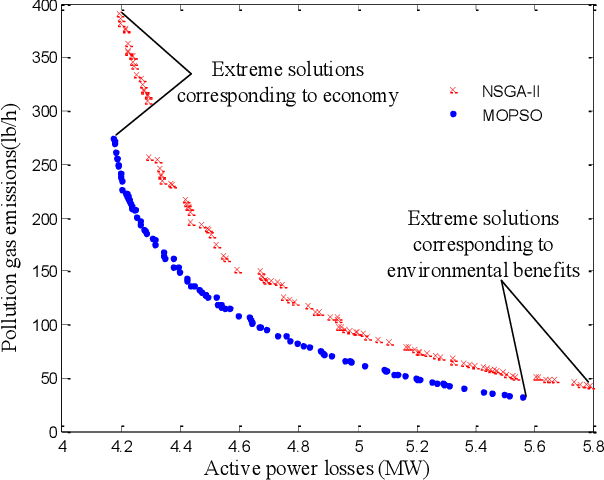
This review explores the application of intelligent optimization algorithms to Multi-Objective Optimal Power Flow (MOPF) in enhancing modern power systems. It delves into the challenges posed by the integration of renewables, smart grids, and increasing energy demands, focusing on evolutionary algorithms, swarm intelligence, and deep reinforcement learning. The effectiveness, scalability, and application of these algorithms are analyzed, with findings suggesting that algorithm selection is contingent on the specific MOPF problem at hand, and hybrid approaches offer significant promise. The importance of standard test systems for verifying solutions and the role of software tools in facilitating analysis are emphasized. Future research is directed towards exploiting machine learning for dynamic optimization, embracing decentralized energy systems, and adapting to evolving policy frameworks to improve power system efficiency and sustainability. This review aims to advance MOPF research by highlighting state-of-the-art methodologies and encouraging the development of innovative solutions for future energy challenges.
Degradation Estimation Recurrent Neural Network with Local and Non-Local Priors for Compressive Spectral Imaging
Nov 15, 2023



In coded aperture snapshot spectral imaging (CASSI) systems, a core problem is to recover the 3D hyperspectral image (HSI) from the 2D measurement. Current deep unfolding networks (DUNs) for the HSI reconstruction mainly suffered from three issues. Firstly, in previous DUNs, the DNNs across different stages were unable to share the feature representations learned from different stages, leading to parameter sparsity, which in turn limited their reconstruction potential. Secondly, previous DUNs fail to estimate degradation-related parameters within a unified framework, including the degradation matrix in the data subproblem and the noise level in the prior subproblem. Consequently, either the accuracy of solving the data or the prior subproblem is compromised. Thirdly, exploiting both local and non-local priors for the HSI reconstruction is crucial, and it remains a key issue to be addressed. In this paper, we first transform the DUN into a Recurrent Neural Network (RNN) by sharing parameters across stages, which allows the DNN in each stage could learn feature representation from different stages, enhancing the representativeness of the DUN. Secondly, we incorporate the Degradation Estimation Network into the RNN (DERNN), which simultaneously estimates the degradation matrix and the noise level by residual learning with reference to the sensing matrix. Thirdly, we propose a Local and Non-Local Transformer (LNLT) to effectively exploit both local and non-local priors in HSIs. By integrating the LNLT into the DERNN for solving the prior subproblem, we propose the DERNN-LNLT, which achieves state-of-the-art performance.
The State of the Art in transformer fault diagnosis with artificial intelligence and Dissolved Gas Analysis: A Review of the Literature
Apr 24, 2023Transformer fault diagnosis (TFD) is a critical aspect of power system maintenance and management. This review paper provides a comprehensive overview of the current state of the art in TFD using artificial intelligence (AI) and dissolved gas analysis (DGA). The paper presents an analysis of recent advancements in this field, including the use of deep learning algorithms and advanced data analytics techniques, and their potential impact on TFD and the power industry as a whole. The review also highlights the benefits and limitations of different approaches to transformer fault diagnosis, including rule-based systems, expert systems, neural networks, and machine learning algorithms. Overall, this review aims to provide valuable insights into the importance of TFD and the role of AI in ensuring the reliable operation of power systems.
Residual Degradation Learning Unfolding Framework with Mixing Priors across Spectral and Spatial for Compressive Spectral Imaging
Nov 13, 2022



To acquire a snapshot spectral image, coded aperture snapshot spectral imaging (CASSI) is proposed. A core problem of the CASSI system is to recover the reliable and fine underlying 3D spectral cube from the 2D measurement. By alternately solving a data subproblem and a prior subproblem, deep unfolding methods achieve good performance. However, in the data subproblem, the used sensing matrix is ill-suited for the real degradation process due to the device errors caused by phase aberration, distortion; in the prior subproblem, it is important to design a suitable model to jointly exploit both spatial and spectral priors. In this paper, we propose a Residual Degradation Learning Unfolding Framework (RDLUF), which bridges the gap between the sensing matrix and the degradation process. Moreover, a Mix$S^2$ Transformer is designed via mixing priors across spectral and spatial to strengthen the spectral-spatial representation capability. Finally, plugging the Mix$S^2$ Transformer into the RDLUF leads to an end-to-end trainable and interpretable neural network RDLUF-Mix$S^2$. Experimental results establish the superior performance of the proposed method over existing ones.
Multi-scale Network with Attentional Multi-resolution Fusion for Point Cloud Semantic Segmentation
Jun 27, 2022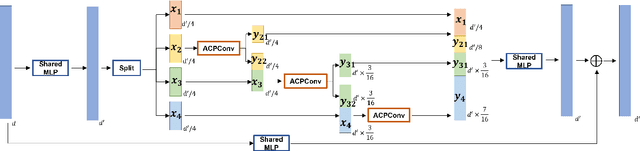
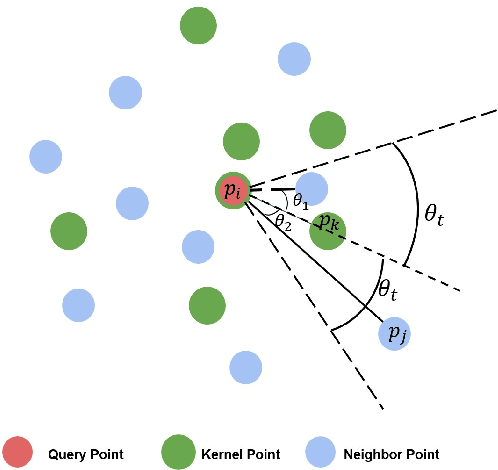
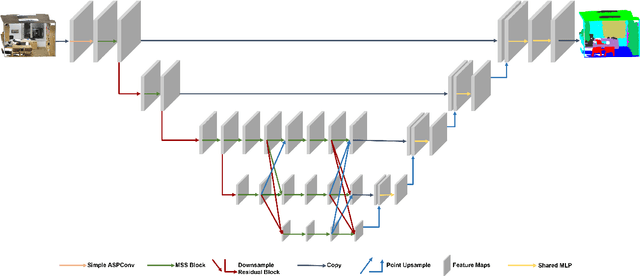
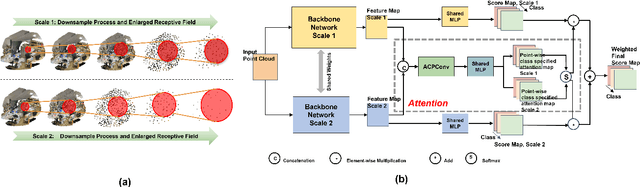
In this paper, we present a comprehensive point cloud semantic segmentation network that aggregates both local and global multi-scale information. First, we propose an Angle Correlation Point Convolution (ACPConv) module to effectively learn the local shapes of points. Second, based upon ACPConv, we introduce a local multi-scale split (MSS) block that hierarchically connects features within one single block and gradually enlarges the receptive field which is beneficial for exploiting the local context. Third, inspired by HRNet which has excellent performance on 2D image vision tasks, we build an HRNet customized for point cloud to learn global multi-scale context. Lastly, we introduce a point-wise attention fusion approach that fuses multi-resolution predictions and further improves point cloud semantic segmentation performance. Our experimental results and ablations on several benchmark datasets show that our proposed method is effective and able to achieve state-of-the-art performances compared to existing methods.
OmniFusion: 360 Monocular Depth Estimation via Geometry-Aware Fusion
Mar 29, 2022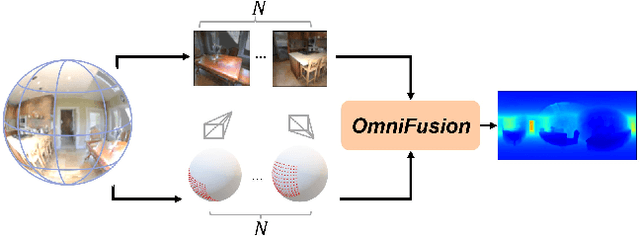
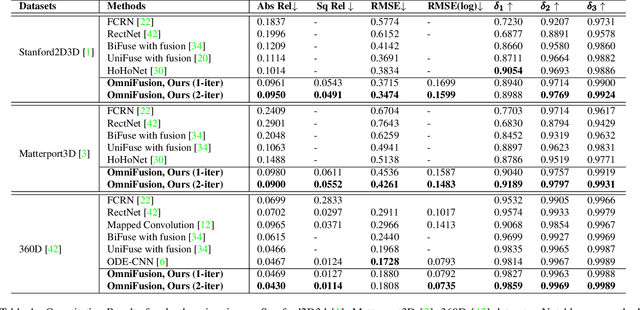
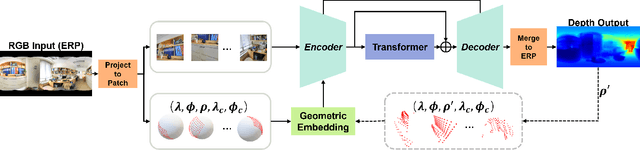

A well-known challenge in applying deep-learning methods to omnidirectional images is spherical distortion. In dense regression tasks such as depth estimation, where structural details are required, using a vanilla CNN layer on the distorted 360 image results in undesired information loss. In this paper, we propose a 360 monocular depth estimation pipeline, OmniFusion, to tackle the spherical distortion issue. Our pipeline transforms a 360 image into less-distorted perspective patches (i.e. tangent images) to obtain patch-wise predictions via CNN, and then merge the patch-wise results for final output. To handle the discrepancy between patch-wise predictions which is a major issue affecting the merging quality, we propose a new framework with the following key components. First, we propose a geometry-aware feature fusion mechanism that combines 3D geometric features with 2D image features to compensate for the patch-wise discrepancy. Second, we employ the self-attention-based transformer architecture to conduct a global aggregation of patch-wise information, which further improves the consistency. Last, we introduce an iterative depth refinement mechanism, to further refine the estimated depth based on the more accurate geometric features. Experiments show that our method greatly mitigates the distortion issue, and achieves state-of-the-art performances on several 360 monocular depth estimation benchmark datasets.
PanoDepth: A Two-Stage Approach for Monocular Omnidirectional Depth Estimation
Feb 02, 2022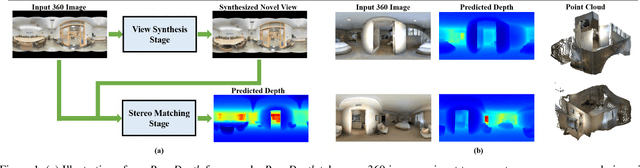
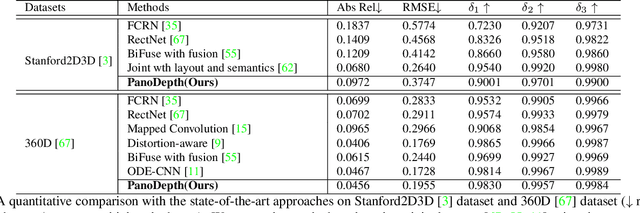
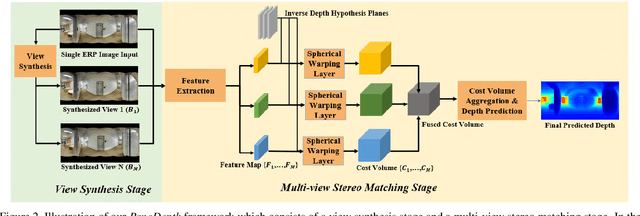

Omnidirectional 3D information is essential for a wide range of applications such as Virtual Reality, Autonomous Driving, Robotics, etc. In this paper, we propose a novel, model-agnostic, two-stage pipeline for omnidirectional monocular depth estimation. Our proposed framework PanoDepth takes one 360 image as input, produces one or more synthesized views in the first stage, and feeds the original image and the synthesized images into the subsequent stereo matching stage. In the second stage, we propose a differentiable Spherical Warping Layer to handle omnidirectional stereo geometry efficiently and effectively. By utilizing the explicit stereo-based geometric constraints in the stereo matching stage, PanoDepth can generate dense high-quality depth. We conducted extensive experiments and ablation studies to evaluate PanoDepth with both the full pipeline as well as the individual modules in each stage. Our results show that PanoDepth outperforms the state-of-the-art approaches by a large margin for 360 monocular depth estimation.
Fast Point Voxel Convolution Neural Network with Selective Feature Fusion for Point Cloud Semantic Segmentation
Sep 23, 2021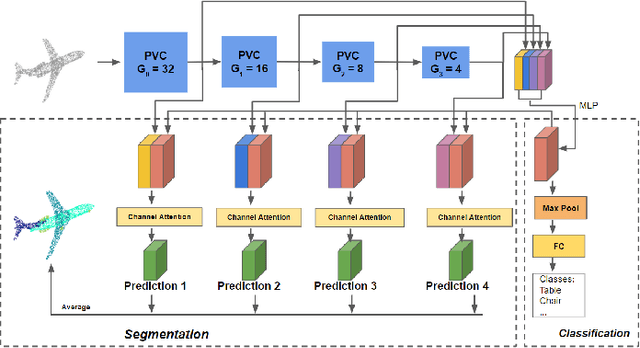
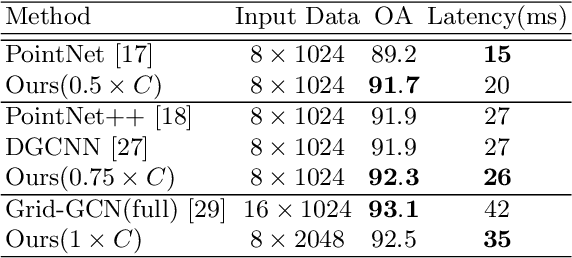
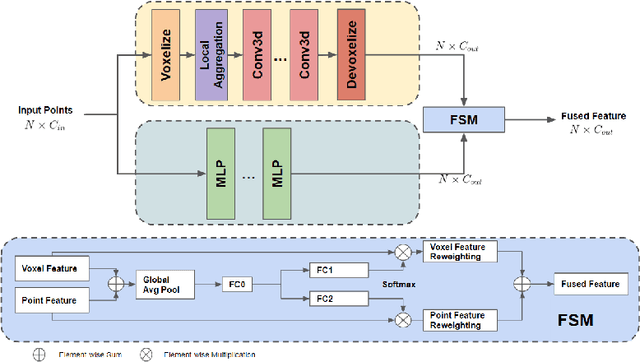
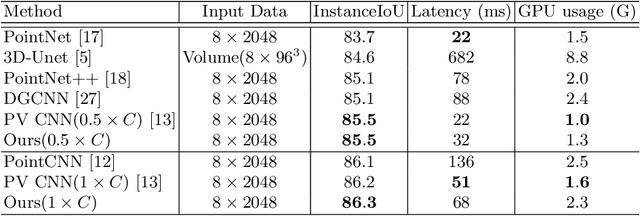
We present a novel lightweight convolutional neural network for point cloud analysis. In contrast to many current CNNs which increase receptive field by downsampling point cloud, our method directly operates on the entire point sets without sampling and achieves good performances efficiently. Our network consists of point voxel convolution (PVC) layer as building block. Each layer has two parallel branches, namely the voxel branch and the point branch. For the voxel branch specifically, we aggregate local features on non-empty voxel centers to reduce geometric information loss caused by voxelization, then apply volumetric convolutions to enhance local neighborhood geometry encoding. For the point branch, we use Multi-Layer Perceptron (MLP) to extract fine-detailed point-wise features. Outputs from these two branches are adaptively fused via a feature selection module. Moreover, we supervise the output from every PVC layer to learn different levels of semantic information. The final prediction is made by averaging all intermediate predictions. We demonstrate empirically that our method is able to achieve comparable results while being fast and memory efficient. We evaluate our method on popular point cloud datasets for object classification and semantic segmentation tasks.
SPNet: Multi-Shell Kernel Convolution for Point Cloud Semantic Segmentation
Sep 23, 2021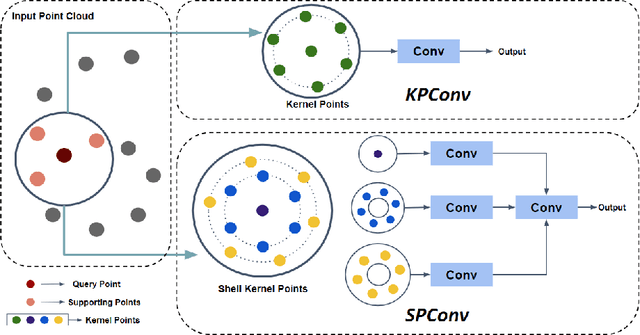
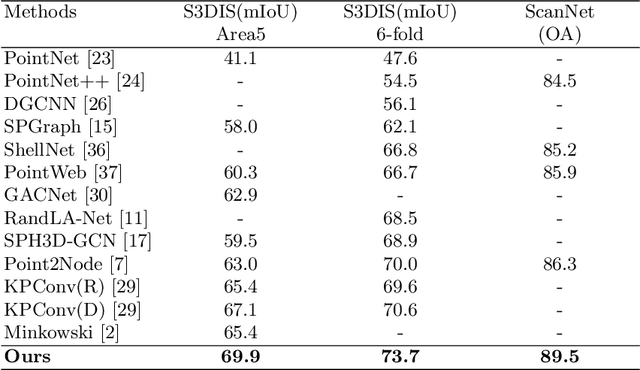
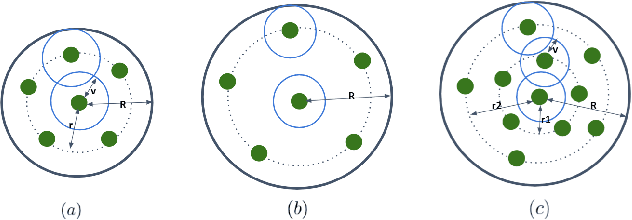

Feature encoding is essential for point cloud analysis. In this paper, we propose a novel point convolution operator named Shell Point Convolution (SPConv) for shape encoding and local context learning. Specifically, SPConv splits 3D neighborhood space into shells, aggregates local features on manually designed kernel points, and performs convolution on the shells. Moreover, SPConv incorporates a simple yet effective attention module that enhances local feature aggregation. Based upon SPConv, a deep neural network named SPNet is constructed to process large-scale point clouds. Poisson disk sampling and feature propagation are incorporated in SPNet for better efficiency and accuracy. We provided details of the shell design and conducted extensive experiments on challenging large-scale point cloud datasets. Experimental results show that SPConv is effective in local shape encoding, and our SPNet is able to achieve top-ranking performances in semantic segmentation tasks.