 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimally Bridging Semantics and Data: Generative Semantic Communication via Schrödinger Bridge
Apr 20, 2026Generative Semantic Communication (GSC) is a promising solution for image transmission over narrow-band and high-noise channels. However, existing GSC methods rely on long, indirect transport trajectories from a Gaussian to an image distribution guided by semantics, causing severe hallucination and high computational cost. To address this, we propose a general framework named Schrödinger Bridge-based GSC (SBGSC). By leveraging the Schrödinger Bridge (SB) to construct optimal transport trajectories between arbitrary distributions, SBGSC breaks Gaussian limitations and enables direct generative decoding from semantics to images. Within this framework, we design Diffusion SB-based GSC (DSBGSC). DSBGSC reconstructs the nonlinear drift term of diffusion models using Schrödinger potentials, achieving direct optimal distribution transport to reduce hallucinations and computational overhead. To further accelerate generation, we propose a self-consistency-based objective guiding the model to learn a nonlinear velocity field pointing directly toward the image, bypassing Markovian noise prediction to significantly reduce sampling steps. Simulation results demonstrate that DSBGSC outperforms state-of-the-art GSC methods, improving FID by at least 38% and SSIM by 49.3%, while accelerating inference speed by over 8 times.
NOC4SC: A Bandwidth-Efficient Multi-User Semantic Communication Framework for Interference-Resilient Transmission
Dec 10, 2025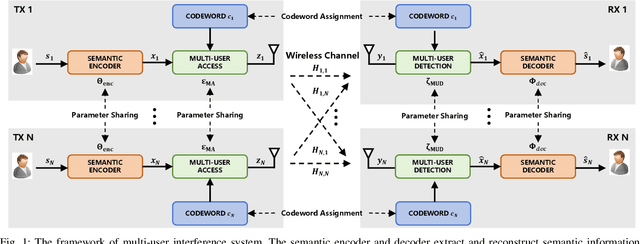
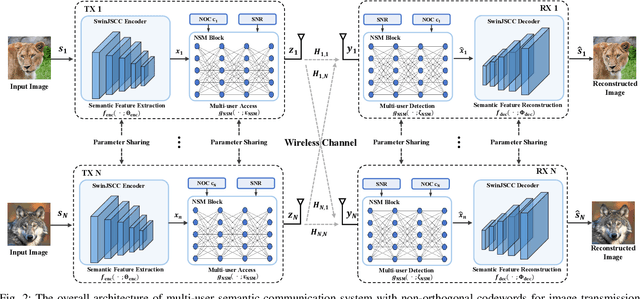
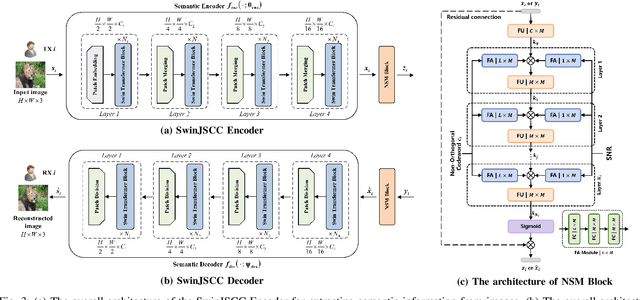
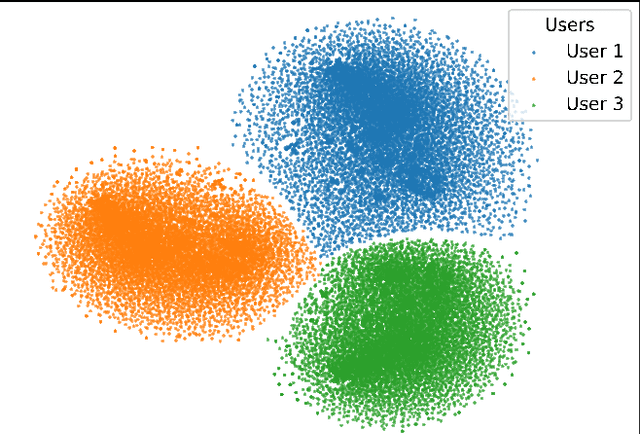
With the explosive growth of connected devices and emerging applications, current wireless networks are encountering unprecedented demands for massive user access, where the inter-user interference has become a critical challenge to maintaining high quality of service (QoS) in multi-user communication systems. To tackle this issue, we propose a bandwidth-efficient semantic communication paradigm termed Non-Orthogonal Codewords for Semantic Communication (NOC4SC), which enables simultaneous same-frequency transmission without spectrum spreading. By leveraging the Swin Transformer, the proposed NOC4SC framework enables each user to independently extract semantic features through a unified encoder-decoder architecture with shared network parameters across all users, which ensures that the user's data remains protected from unauthorized decoding. Furthermore, we introduce an adaptive NOC and SNR Modulation (NSM) block, which employs deep learning to dynamically regulate SNR and generate approximately orthogonal semantic features within distinct feature subspaces, thereby effectively mitigating inter-user interference. Extensive experiments demonstrate the proposed NOC4SC achieves comparable performance to the DeepJSCC-PNOMA and outperforms other multi-user SemCom baseline methods.
PACE: A Pragmatic Agent for Enhancing Communication Efficiency Using Large Language Models
Jan 30, 2024Current communication technologies face limitations in terms of theoretical capacity, spectrum availability, and power resources. Pragmatic communication, leveraging terminal intelligence for selective data transmission, offers resource conservation. Existing research lacks universal intention resolution tools, limiting applicability to specific tasks. This paper proposes an image pragmatic communication framework based on a Pragmatic Agent for Communication Efficiency (PACE) using Large Language Models (LLM). In this framework, PACE sequentially performs semantic perception, intention resolution, and intention-oriented coding. To ensure the effective utilization of LLM in communication, a knowledge base is designed to supplement the necessary knowledge, dedicated prompts are introduced to facilitate understanding of pragmatic communication scenarios and task requirements, and a chain of thought is designed to assist in making reasonable trade-offs between transmission efficiency and cost. For experimental validation, this paper constructs an image pragmatic communication dataset along with corresponding evaluation standards. Simulation results indicate that the proposed method outperforms traditional and non-LLM-based pragmatic communication in terms of transmission efficiency.
Degradation Estimation Recurrent Neural Network with Local and Non-Local Priors for Compressive Spectral Imaging
Nov 15, 2023



In coded aperture snapshot spectral imaging (CASSI) systems, a core problem is to recover the 3D hyperspectral image (HSI) from the 2D measurement. Current deep unfolding networks (DUNs) for the HSI reconstruction mainly suffered from three issues. Firstly, in previous DUNs, the DNNs across different stages were unable to share the feature representations learned from different stages, leading to parameter sparsity, which in turn limited their reconstruction potential. Secondly, previous DUNs fail to estimate degradation-related parameters within a unified framework, including the degradation matrix in the data subproblem and the noise level in the prior subproblem. Consequently, either the accuracy of solving the data or the prior subproblem is compromised. Thirdly, exploiting both local and non-local priors for the HSI reconstruction is crucial, and it remains a key issue to be addressed. In this paper, we first transform the DUN into a Recurrent Neural Network (RNN) by sharing parameters across stages, which allows the DNN in each stage could learn feature representation from different stages, enhancing the representativeness of the DUN. Secondly, we incorporate the Degradation Estimation Network into the RNN (DERNN), which simultaneously estimates the degradation matrix and the noise level by residual learning with reference to the sensing matrix. Thirdly, we propose a Local and Non-Local Transformer (LNLT) to effectively exploit both local and non-local priors in HSIs. By integrating the LNLT into the DERNN for solving the prior subproblem, we propose the DERNN-LNLT, which achieves state-of-the-art performance.
Mathematical Characterization of Signal Semantics and Rethinking of the Mathematical Theory of Information
Mar 26, 2023



Shannon information theory is established based on probability and bits, and the communication technology based on this theory realizes the information age. The original goal of Shannon's information theory is to describe and transmit information content. However, due to information is related to cognition, and cognition is considered to be subjective, Shannon information theory is to describe and transmit information-bearing signals. With the development of the information age to the intelligent age, the traditional signal-oriented processing needs to be upgraded to content-oriented processing. For example, chat generative pre-trained transformer (ChatGPT) has initially realized the content processing capability based on massive data. For many years, researchers have been searching for the answer to what the information content in the signal is, because only when the information content is mathematically and accurately described can information-based machines be truly intelligent. This paper starts from rethinking the essence of the basic concepts of the information, such as semantics, meaning, information and knowledge, presents the mathematical characterization of the information content, investigate the relationship between them, studies the transformation from Shannon's signal information theory to semantic information theory, and therefore proposes a content-oriented semantic communication framework. Furthermore, we propose semantic decomposition and composition scheme to achieve conversion between complex and simple semantics. Finally, we verify the proposed characterization of information-related concepts by implementing evolvable knowledge-based semantic recognition.
Features Disentangled Semantic Broadcast Communication Networks
Mar 03, 2023



Single-user semantic communications have attracted extensive research recently, but multi-user semantic broadcast communication (BC) is still in its infancy. In this paper, we propose a practical robust features-disentangled multi-user semantic BC framework, where the transmitter includes a feature selection module and each user has a feature completion module. Instead of broadcasting all extracted features, the semantic encoder extracts the disentangled semantic features, and then only the users' intended semantic features are selected for broadcasting, which can further improve the transmission efficiency. Within this framework, we further investigate two information-theoretic metrics, including the ultimate compression rate under both the distortion and perception constraints, and the achievable rate region of the semantic BC. Furthermore, to realize the proposed semantic BC framework, we design a lightweight robust semantic BC network by exploiting a supervised autoencoder (AE), which can controllably disentangle sematic features. Moreover, we design the first hardware proof-of-concept prototype of the semantic BC network, where the proposed semantic BC network can be implemented in real time. Simulations and experiments demonstrate that the proposed robust semantic BC network can significantly improve transmission efficiency.
Task-oriented Explainable Semantic Communications
Feb 27, 2023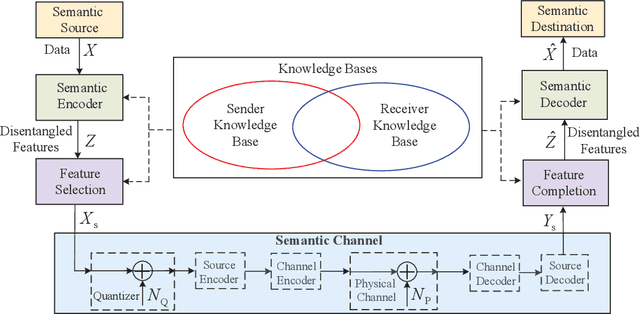
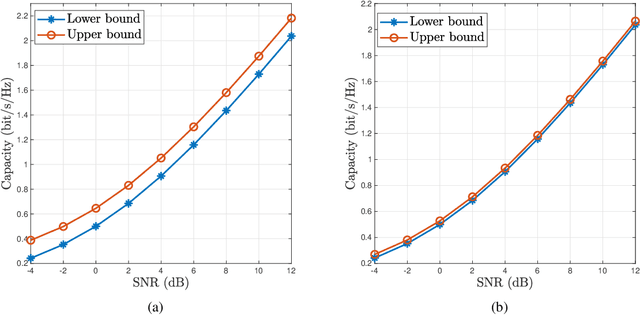
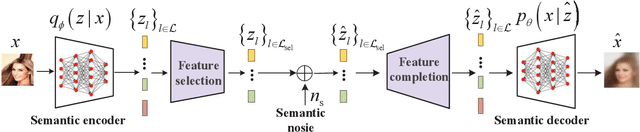
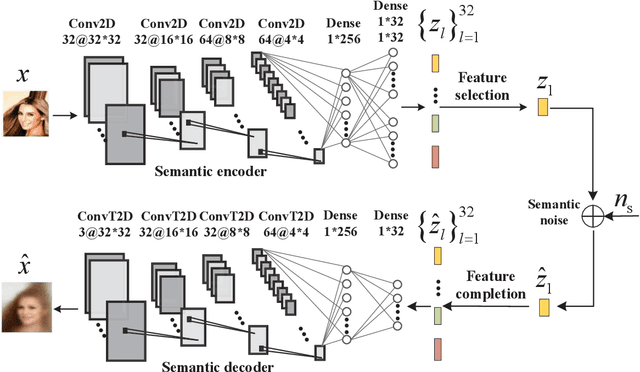
Semantic communications utilize the transceiver computing resources to alleviate scarce transmission resources, such as bandwidth and energy. Although the conventional deep learning (DL) based designs may achieve certain transmission efficiency, the uninterpretability issue of extracted features is the major challenge in the development of semantic communications. In this paper, we propose an explainable and robust semantic communication framework by incorporating the well-established bit-level communication system, which not only extracts and disentangles features into independent and semantically interpretable features, but also only selects task-relevant features for transmission, instead of all extracted features. Based on this framework, we derive the optimal input for rate-distortion-perception theory, and derive both lower and upper bounds on the semantic channel capacity. Furthermore, based on the $\beta $-variational autoencoder ($\beta $-VAE), we propose a practical explainable semantic communication system design, which simultaneously achieves semantic features selection and is robust against semantic channel noise. We further design a real-time wireless mobile semantic communication proof-of-concept prototype. Our simulations and experiments demonstrate that our proposed explainable semantic communications system can significantly improve transmission efficiency, and also verify the effectiveness of our proposed robust semantic transmission scheme.
Residual Degradation Learning Unfolding Framework with Mixing Priors across Spectral and Spatial for Compressive Spectral Imaging
Nov 13, 2022



To acquire a snapshot spectral image, coded aperture snapshot spectral imaging (CASSI) is proposed. A core problem of the CASSI system is to recover the reliable and fine underlying 3D spectral cube from the 2D measurement. By alternately solving a data subproblem and a prior subproblem, deep unfolding methods achieve good performance. However, in the data subproblem, the used sensing matrix is ill-suited for the real degradation process due to the device errors caused by phase aberration, distortion; in the prior subproblem, it is important to design a suitable model to jointly exploit both spatial and spectral priors. In this paper, we propose a Residual Degradation Learning Unfolding Framework (RDLUF), which bridges the gap between the sensing matrix and the degradation process. Moreover, a Mix$S^2$ Transformer is designed via mixing priors across spectral and spatial to strengthen the spectral-spatial representation capability. Finally, plugging the Mix$S^2$ Transformer into the RDLUF leads to an end-to-end trainable and interpretable neural network RDLUF-Mix$S^2$. Experimental results establish the superior performance of the proposed method over existing ones.
Knowledge-guided Semantic Computing Network
Sep 29, 2018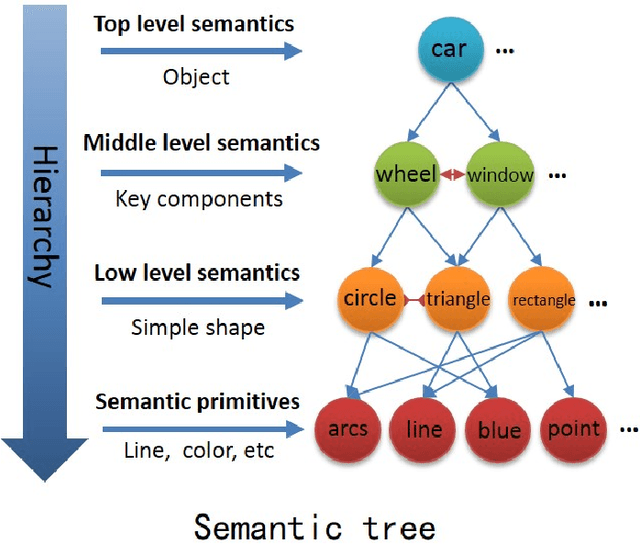
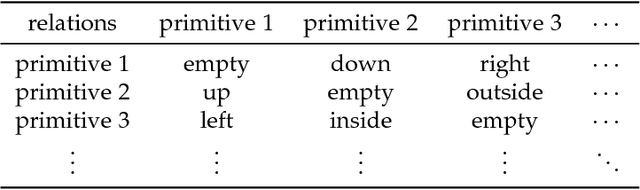
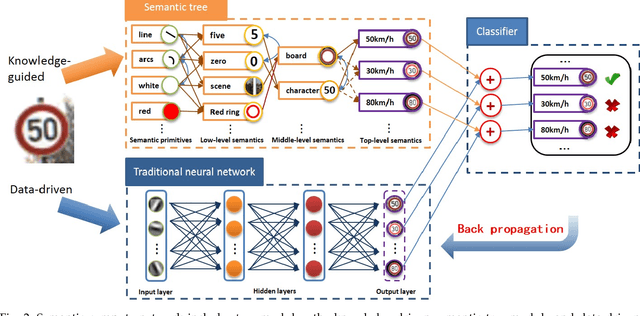

It is very useful to integrate human knowledge and experience into traditional neural networks for faster learning speed, fewer training samples and better interpretability. However, due to the obscured and indescribable black box model of neural networks, it is very difficult to design its architecture, interpret its features and predict its performance. Inspired by human visual cognition process, we propose a knowledge-guided semantic computing network which includes two modules: a knowledge-guided semantic tree and a data-driven neural network. The semantic tree is pre-defined to describe the spatial structural relations of different semantics, which just corresponds to the tree-like description of objects based on human knowledge. The object recognition process through the semantic tree only needs simple forward computing without training. Besides, to enhance the recognition ability of the semantic tree in aspects of the diversity, randomicity and variability, we use the traditional neural network to aid the semantic tree to learn some indescribable features. Only in this case, the training process is needed. The experimental results on MNIST and GTSRB datasets show that compared with the traditional data-driven network, our proposed semantic computing network can achieve better performance with fewer training samples and lower computational complexity. Especially, Our model also has better adversarial robustness than traditional neural network with the help of human knowledge.