 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParse Graph-Based Visual-Language Interaction for Human Pose Estimation
Sep 09, 2025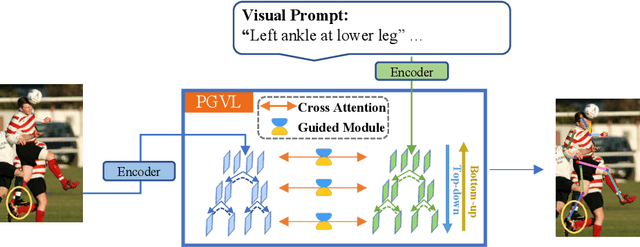

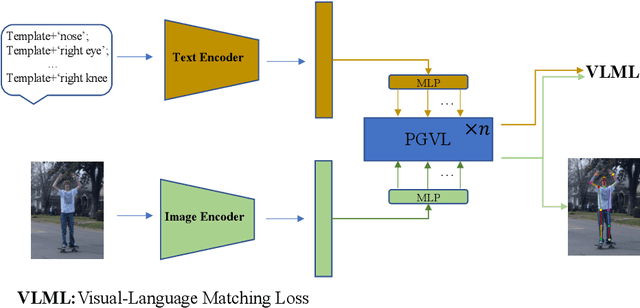

Parse graphs boost human pose estimation (HPE) by integrating context and hierarchies, yet prior work mostly focuses on single modality modeling, ignoring the potential of multimodal fusion. Notably, language offers rich HPE priors like spatial relations for occluded scenes, but existing visual-language fusion via global feature integration weakens occluded region responses and causes alignment and location failures. To address this issue, we propose Parse Graph-based Visual-Language interaction (PGVL) with a core novel Guided Module (GM). In PGVL, low-level nodes focus on local features, maximizing the maintenance of responses in occluded areas and high-level nodes integrate global features to infer occluded or invisible parts. GM enables high semantic nodes to guide the feature update of low semantic nodes that have undergone cross attention. It ensuring effective fusion of diverse information. PGVL includes top-down decomposition and bottom-up composition. In the first stage, modality specific parse graphs are constructed. Next stage. recursive bidirectional cross-attention is used, purified by GM. We also design network based on PGVL. The PGVL and our network is validated on major pose estimation datasets. We will release the code soon.
KB-DMGen: Knowledge-Based Global Guidance and Dynamic Pose Masking for Human Image Generation
Jul 26, 2025Recent methods using diffusion models have made significant progress in human image generation with various control signals such as pose priors. In portrait generation, both the accuracy of human pose and the overall visual quality are crucial for realistic synthesis. Most existing methods focus on controlling the accuracy of generated poses, but ignore the quality assurance of the entire image. In order to ensure the global image quality and pose accuracy, we propose Knowledge-Based Global Guidance and Dynamic pose Masking for human image Generation (KB-DMGen). The Knowledge Base (KB) is designed not only to enhance pose accuracy but also to leverage image feature information to maintain overall image quality. Dynamic Masking (DM) dynamically adjusts the importance of pose-related regions. Experiments demonstrate the effectiveness of our model, achieving new state-of-the-art results in terms of AP and CAP on the HumanArt dataset. The code will be made publicly available.
Visual Environment-Interactive Planning for Embodied Complex-Question Answering
Apr 01, 2025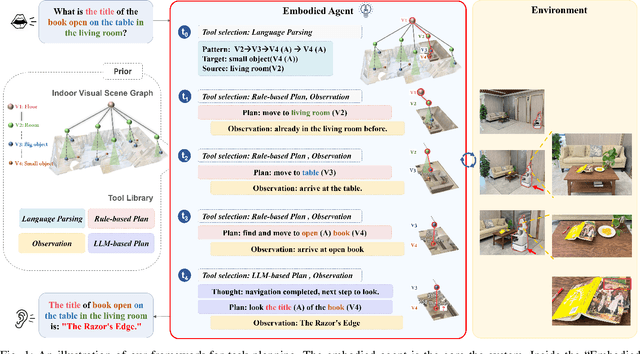
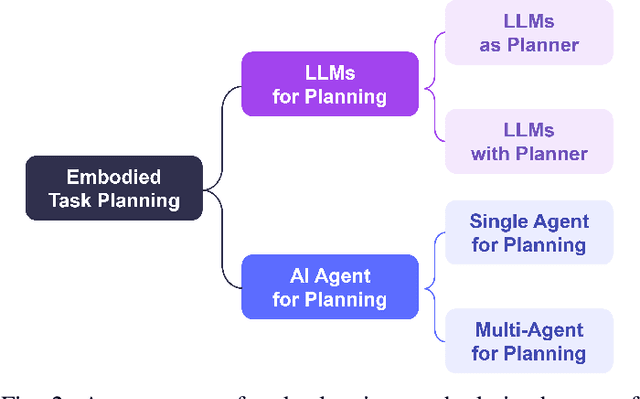
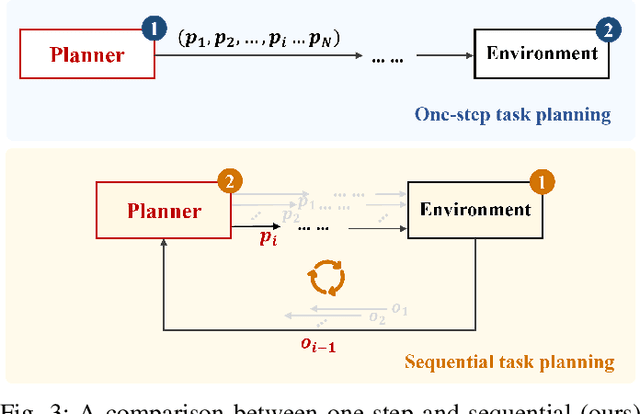
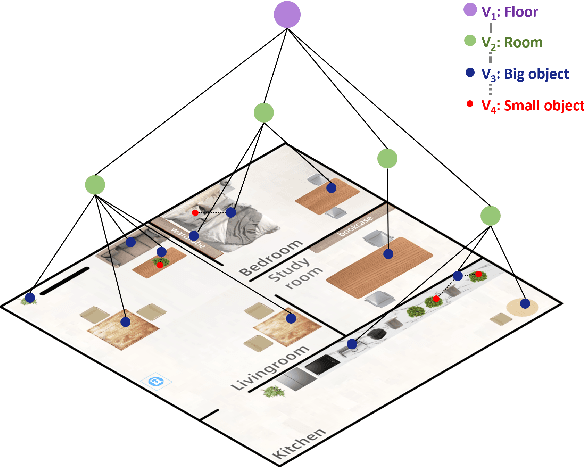
This study focuses on Embodied Complex-Question Answering task, which means the embodied robot need to understand human questions with intricate structures and abstract semantics. The core of this task lies in making appropriate plans based on the perception of the visual environment. Existing methods often generate plans in a once-for-all manner, i.e., one-step planning. Such approach rely on large models, without sufficient understanding of the environment. Considering multi-step planning, the framework for formulating plans in a sequential manner is proposed in this paper. To ensure the ability of our framework to tackle complex questions, we create a structured semantic space, where hierarchical visual perception and chain expression of the question essence can achieve iterative interaction. This space makes sequential task planning possible. Within the framework, we first parse human natural language based on a visual hierarchical scene graph, which can clarify the intention of the question. Then, we incorporate external rules to make a plan for current step, weakening the reliance on large models. Every plan is generated based on feedback from visual perception, with multiple rounds of interaction until an answer is obtained. This approach enables continuous feedback and adjustment, allowing the robot to optimize its action strategy. To test our framework, we contribute a new dataset with more complex questions. Experimental results demonstrate that our approach performs excellently and stably on complex tasks. And also, the feasibility of our approach in real-world scenarios has been established, indicating its practical applicability.
ACMo: Attribute Controllable Motion Generation
Mar 14, 2025Attributes such as style, fine-grained text, and trajectory are specific conditions for describing motion. However, existing methods often lack precise user control over motion attributes and suffer from limited generalizability to unseen motions. This work introduces an Attribute Controllable Motion generation architecture, to address these challenges via decouple any conditions and control them separately. Firstly, we explored the Attribute Diffusion Model to imporve text-to-motion performance via decouple text and motion learning, as the controllable model relies heavily on the pre-trained model. Then, we introduce Motion Adpater to quickly finetune previously unseen motion patterns. Its motion prompts inputs achieve multimodal text-to-motion generation that captures user-specified styles. Finally, we propose a LLM Planner to bridge the gap between unseen attributes and dataset-specific texts via local knowledage for user-friendly interaction. Our approach introduces the capability for motion prompts for stylize generation, enabling fine-grained and user-friendly attribute control while providing performance comparable to state-of-the-art methods. Project page: https://mjwei3d.github.io/ACMo/
Refinement Module based on Parse Graph of Feature Map for Human Pose Estimation
Jan 19, 2025



Parse graphs of the human body can be obtained in the human brain to help humans complete the human pose estimation (HPE). It contains a hierarchical structure, like a tree structure, and context relations among nodes. Many researchers pre-design the parse graph of body structure, and then design framework for HPE. However, these frameworks are difficulty adapting when encountering situations that differ from the preset human structure. Different from them, we regard the feature map as a whole, similarly to human body, so the feature map can be optimized based on parse graphs and each node feature is learned implicitly instead of explicitly, which means it can flexibly respond to different human body structure. In this paper, we design the Refinement Module based on the Parse Graph of feature map (RMPG), which includes two stages: top-down decomposition and bottom-up combination. In the top-down decomposition stage, the feature map is decomposed into multiple sub-feature maps along the channel and their context relations are calculated to obtain their respective context information. In the bottom-up combination stage, the sub-feature maps and their context information are combined to obtain refined sub-feature maps, and then these refined sub-feature maps are concatenated to obtain the refined feature map. Additionally ,we design a top-down framework by using multiple RMPG modules for HPE, some of which are supervised to obtain context relations among body parts. Our framework achieves excellent results on the COCO keypoint detection, CrowdPose and MPII human pose datasets. More importantly, our experiments also demonstrate the effectiveness of RMPG on different methods, including SimpleBaselines, Hourglass, and ViTPose.
Mathematical Characterization of Signal Semantics and Rethinking of the Mathematical Theory of Information
Mar 26, 2023



Shannon information theory is established based on probability and bits, and the communication technology based on this theory realizes the information age. The original goal of Shannon's information theory is to describe and transmit information content. However, due to information is related to cognition, and cognition is considered to be subjective, Shannon information theory is to describe and transmit information-bearing signals. With the development of the information age to the intelligent age, the traditional signal-oriented processing needs to be upgraded to content-oriented processing. For example, chat generative pre-trained transformer (ChatGPT) has initially realized the content processing capability based on massive data. For many years, researchers have been searching for the answer to what the information content in the signal is, because only when the information content is mathematically and accurately described can information-based machines be truly intelligent. This paper starts from rethinking the essence of the basic concepts of the information, such as semantics, meaning, information and knowledge, presents the mathematical characterization of the information content, investigate the relationship between them, studies the transformation from Shannon's signal information theory to semantic information theory, and therefore proposes a content-oriented semantic communication framework. Furthermore, we propose semantic decomposition and composition scheme to achieve conversion between complex and simple semantics. Finally, we verify the proposed characterization of information-related concepts by implementing evolvable knowledge-based semantic recognition.
Temporal Graph Modeling for Skeleton-based Action Recognition
Dec 16, 2020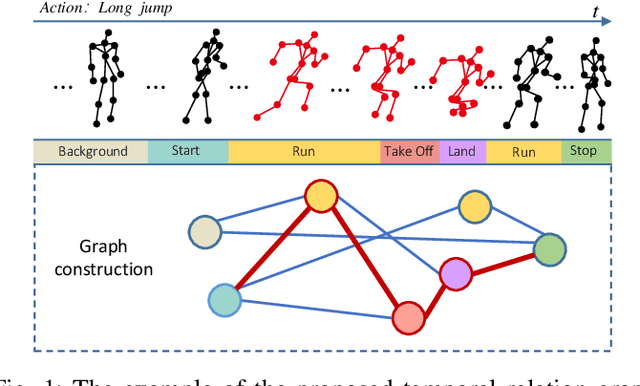
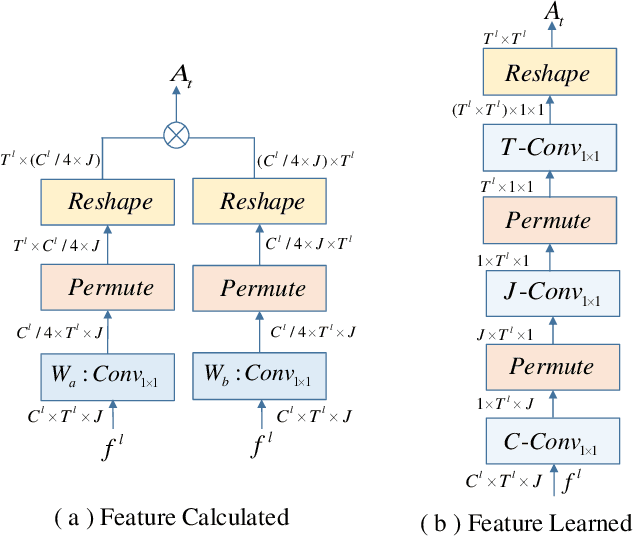
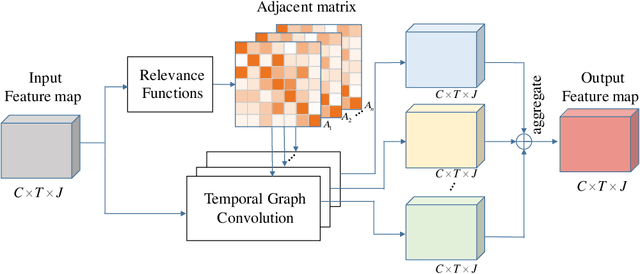
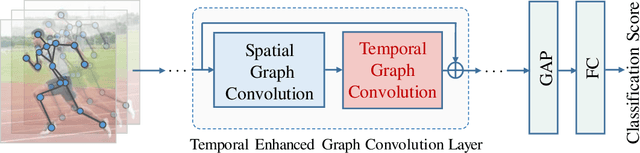
Graph Convolutional Networks (GCNs), which model skeleton data as graphs, have obtained remarkable performance for skeleton-based action recognition. Particularly, the temporal dynamic of skeleton sequence conveys significant information in the recognition task. For temporal dynamic modeling, GCN-based methods only stack multi-layer 1D local convolutions to extract temporal relations between adjacent time steps. With the repeat of a lot of local convolutions, the key temporal information with non-adjacent temporal distance may be ignored due to the information dilution. Therefore, these methods still remain unclear how to fully explore temporal dynamic of skeleton sequence. In this paper, we propose a Temporal Enhanced Graph Convolutional Network (TE-GCN) to tackle this limitation. The proposed TE-GCN constructs temporal relation graph to capture complex temporal dynamic. Specifically, the constructed temporal relation graph explicitly builds connections between semantically related temporal features to model temporal relations between both adjacent and non-adjacent time steps. Meanwhile, to further explore the sufficient temporal dynamic, multi-head mechanism is designed to investigate multi-kinds of temporal relations. Extensive experiments are performed on two widely used large-scale datasets, NTU-60 RGB+D and NTU-120 RGB+D. And experimental results show that the proposed model achieves the state-of-the-art performance by making contribution to temporal modeling for action recognition.
Knowledge-guided Semantic Computing Network
Sep 29, 2018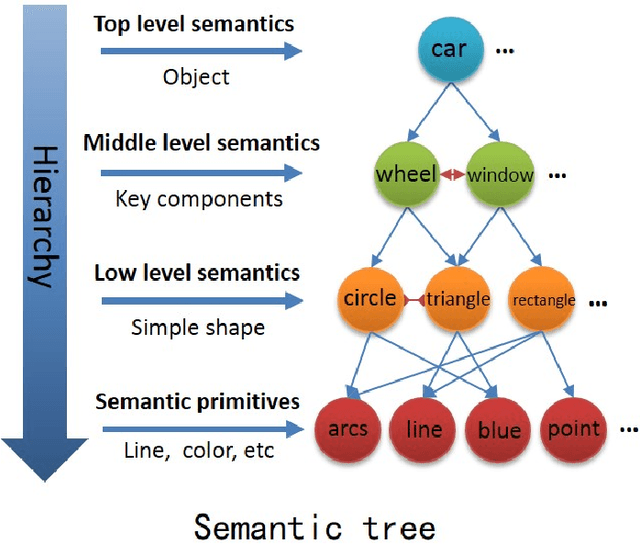
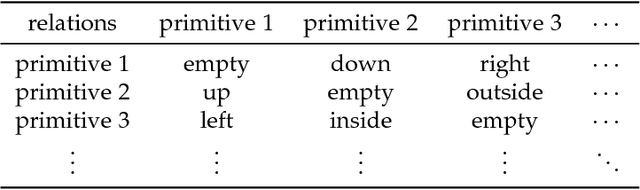
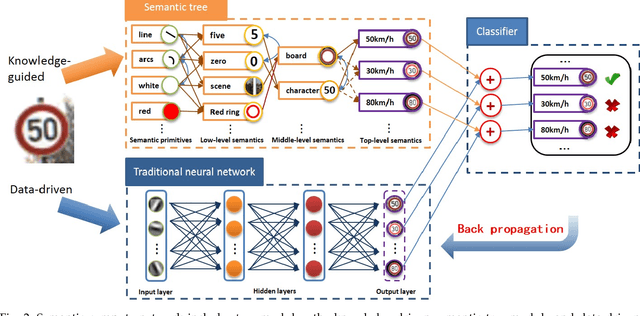

It is very useful to integrate human knowledge and experience into traditional neural networks for faster learning speed, fewer training samples and better interpretability. However, due to the obscured and indescribable black box model of neural networks, it is very difficult to design its architecture, interpret its features and predict its performance. Inspired by human visual cognition process, we propose a knowledge-guided semantic computing network which includes two modules: a knowledge-guided semantic tree and a data-driven neural network. The semantic tree is pre-defined to describe the spatial structural relations of different semantics, which just corresponds to the tree-like description of objects based on human knowledge. The object recognition process through the semantic tree only needs simple forward computing without training. Besides, to enhance the recognition ability of the semantic tree in aspects of the diversity, randomicity and variability, we use the traditional neural network to aid the semantic tree to learn some indescribable features. Only in this case, the training process is needed. The experimental results on MNIST and GTSRB datasets show that compared with the traditional data-driven network, our proposed semantic computing network can achieve better performance with fewer training samples and lower computational complexity. Especially, Our model also has better adversarial robustness than traditional neural network with the help of human knowledge.
Perceptual Compressive Sensing
Aug 27, 2018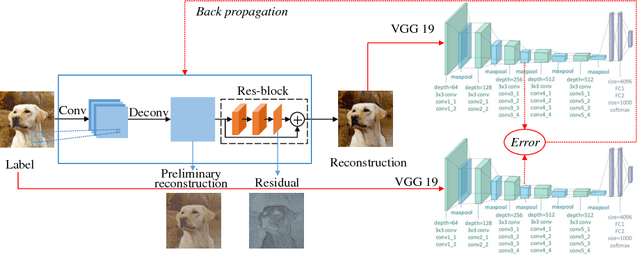
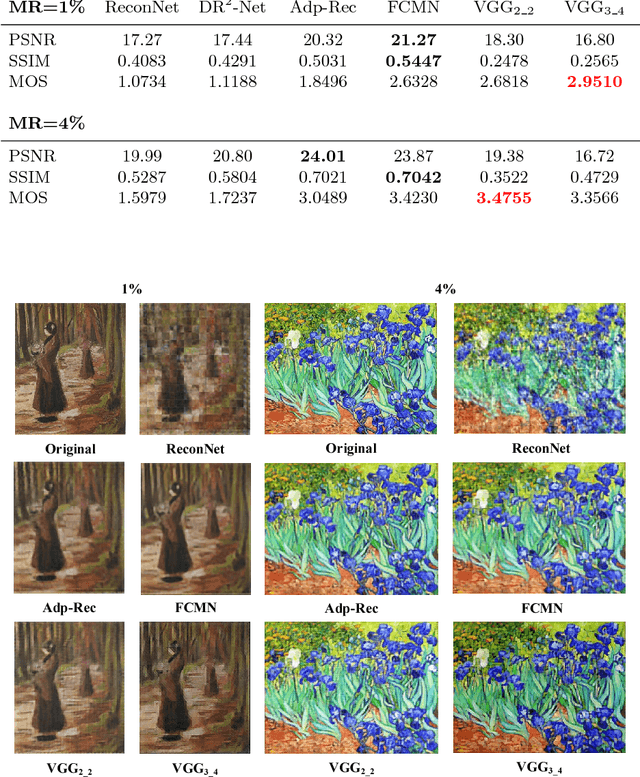


Compressive sensing (CS) works to acquire measurements at sub-Nyquist rate and recover the scene images. Existing CS methods always recover the scene images in pixel level. This causes the smoothness of recovered images and lack of structure information, especially at a low measurement rate. To overcome this drawback, in this paper, we propose perceptual CS to obtain high-level structured recovery. Our task no longer focuses on pixel level. Instead, we work to make a better visual effect. In detail, we employ perceptual loss, defined on feature level, to enhance the structure information of the recovered images. Experiments show that our method achieves better visual results with stronger structure information than existing CS methods at the same measurement rate.
Fully Convolutional Measurement Network for Compressive Sensing Image Reconstruction
May 29, 2018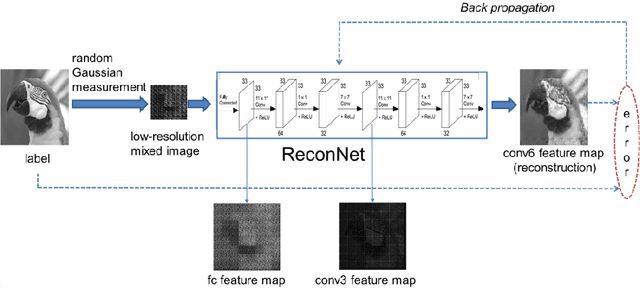
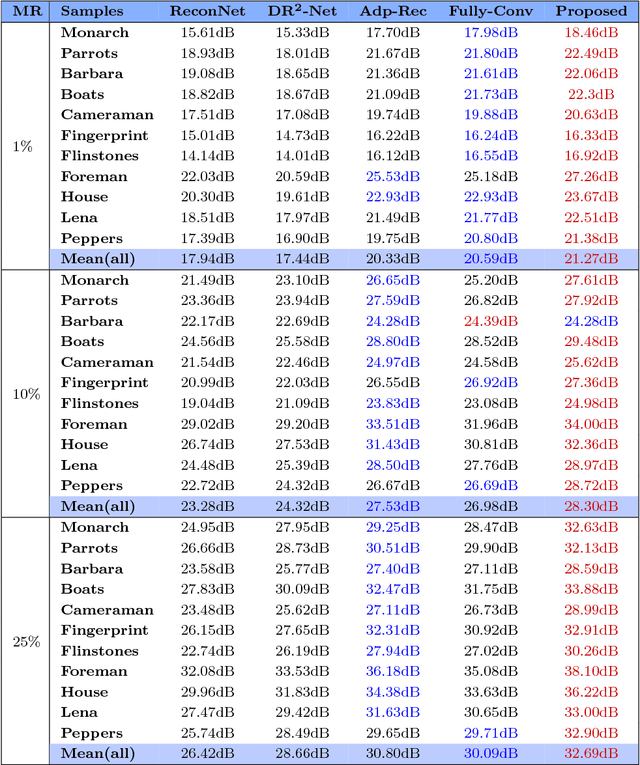
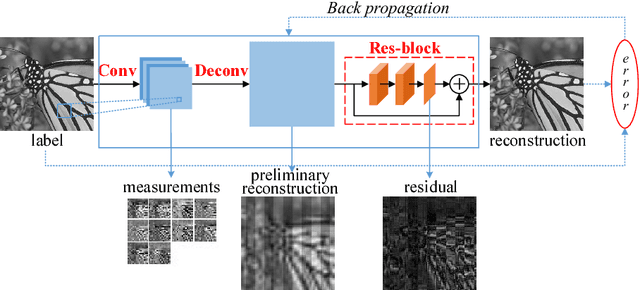

Recently, deep learning methods have made a significant improvement in compressive sensing image reconstruction task. In the existing methods, the scene is measured block by block due to the high computational complexity. This results in block-effect of the recovered images. In this paper, we propose a fully convolutional measurement network, where the scene is measured as a whole. The proposed method powerfully removes the block-effect since the structure information of scene images is preserved. To make the measure more flexible, the measurement and the recovery parts are jointly trained. From the experiments, it is shown that the results by the proposed method outperforms those by the existing methods in PSNR, SSIM, and visual effect.