 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsat Core Prediction through Polarity-Aware Representation Learning over Clause-Literal Hypergraphs
May 06, 2026Graph neural networks have been widely used in Boolean satisfiability (SAT) tasks to learn structural information from SAT formulas. The goal of these studies is to solve SAT instances or to enhance SAT solvers, including tasks such as unsat-core prediction. However, most existing approaches model a SAT formula as a bipartite graph or a directed acyclic graph, which are less expressive in capturing higher-order interactions among literals and clauses. Moreover, these approaches are limited in modeling intrinsic polarity-related properties of SAT, such as the complementary relationship between the positive and negative literals of a variable. To address these limitations, we propose a polarity-aware representation learning framework over clause-literal hypergraphs. We model SAT formulas as clause-literal hypergraphs augmented with a clause incidence graph to capture higher-order structural interactions. We then introduce a polarity-aware decomposed mechanism that separates variable representations into polarity invariant and equivariant components, explicitly modeling the relationship between positive and negative literals, with the resulting literal representations propagated along the hypergraph structure. We further incorporate a polarity-inversion consistency regularization to reinforce polarity-consistent representations during training. Experimental results on multiple SAT datasets demonstrate the effectiveness of the proposed approach.
Optimally Bridging Semantics and Data: Generative Semantic Communication via Schrödinger Bridge
Apr 20, 2026Generative Semantic Communication (GSC) is a promising solution for image transmission over narrow-band and high-noise channels. However, existing GSC methods rely on long, indirect transport trajectories from a Gaussian to an image distribution guided by semantics, causing severe hallucination and high computational cost. To address this, we propose a general framework named Schrödinger Bridge-based GSC (SBGSC). By leveraging the Schrödinger Bridge (SB) to construct optimal transport trajectories between arbitrary distributions, SBGSC breaks Gaussian limitations and enables direct generative decoding from semantics to images. Within this framework, we design Diffusion SB-based GSC (DSBGSC). DSBGSC reconstructs the nonlinear drift term of diffusion models using Schrödinger potentials, achieving direct optimal distribution transport to reduce hallucinations and computational overhead. To further accelerate generation, we propose a self-consistency-based objective guiding the model to learn a nonlinear velocity field pointing directly toward the image, bypassing Markovian noise prediction to significantly reduce sampling steps. Simulation results demonstrate that DSBGSC outperforms state-of-the-art GSC methods, improving FID by at least 38% and SSIM by 49.3%, while accelerating inference speed by over 8 times.
Knowledge-Refined Dual Context-Aware Network for Partially Relevant Video Retrieval
Mar 25, 2026Retrieving partially relevant segments from untrimmed videos remains difficult due to two persistent challenges: the mismatch in information density between text and video segments, and limited attention mechanisms that overlook semantic focus and event correlations. We present KDC-Net, a Knowledge-Refined Dual Context-Aware Network that tackles these issues from both textual and visual perspectives. On the text side, a Hierarchical Semantic Aggregation module captures and adaptively fuses multi-scale phrase cues to enrich query semantics. On the video side, a Dynamic Temporal Attention mechanism employs relative positional encoding and adaptive temporal windows to highlight key events with local temporal coherence. Additionally, a dynamic CLIP-based distillation strategy, enhanced with temporal-continuity-aware refinement, ensures segment-aware and objective-aligned knowledge transfer. Experiments on PRVR benchmarks show that KDC-Net consistently outperforms state-of-the-art methods, especially under low moment-to-video ratios.
Heterogeneous Agent Collaborative Reinforcement Learning
Mar 03, 2026We introduce Heterogeneous Agent Collaborative Reinforcement Learning (HACRL), a new learning paradigm that addresses the inefficiencies of isolated on-policy optimization. HACRL enables collaborative optimization with independent execution: heterogeneous agents share verified rollouts during training to mutually improve, while operating independently at inference time. Unlike LLM-based multi-agent reinforcement learning (MARL), HACRL does not require coordinated deployment, and unlike on-/off-policy distillation, it enables bidirectional mutual learning among heterogeneous agents rather than one-directional teacher-to-student transfer. Building on this paradigm, we propose HACPO, a collaborative RL algorithm that enables principled rollout sharing to maximize sample utilization and cross-agent knowledge transfer. To mitigate capability discrepancies and policy distribution shifts, HACPO introduces four tailored mechanisms with theoretical guarantees on unbiased advantage estimation and optimization correctness. Extensive experiments across diverse heterogeneous model combinations and reasoning benchmarks show that HACPO consistently improves all participating agents, outperforming GSPO by an average of 3.3\% while using only half the rollout cost.
Adaptive Prompt Elicitation for Text-to-Image Generation
Feb 04, 2026Aligning text-to-image generation with user intent remains challenging, for users who provide ambiguous inputs and struggle with model idiosyncrasies. We propose Adaptive Prompt Elicitation (APE), a technique that adaptively asks visual queries to help users refine prompts without extensive writing. Our technical contribution is a formulation of interactive intent inference under an information-theoretic framework. APE represents latent intent as interpretable feature requirements using language model priors, adaptively generates visual queries, and compiles elicited requirements into effective prompts. Evaluation on IDEA-Bench and DesignBench shows that APE achieves stronger alignment with improved efficiency. A user study with challenging user-defined tasks demonstrates 19.8% higher alignment without workload overhead. Our work contributes a principled approach to prompting that, for general users, offers an effective and efficient complement to the prevailing prompt-based interaction paradigm with text-to-image models.
Your Group-Relative Advantage Is Biased
Jan 13, 2026Reinforcement Learning from Verifier Rewards (RLVR) has emerged as a widely used approach for post-training large language models on reasoning tasks, with group-based methods such as GRPO and its variants gaining broad adoption. These methods rely on group-relative advantage estimation to avoid learned critics, yet its theoretical properties remain poorly understood. In this work, we uncover a fundamental issue of group-based RL: the group-relative advantage estimator is inherently biased relative to the true (expected) advantage. We provide the first theoretical analysis showing that it systematically underestimates advantages for hard prompts and overestimates them for easy prompts, leading to imbalanced exploration and exploitation. To address this issue, we propose History-Aware Adaptive Difficulty Weighting (HA-DW), an adaptive reweighting scheme that adjusts advantage estimates based on an evolving difficulty anchor and training dynamics. Both theoretical analysis and experiments on five mathematical reasoning benchmarks demonstrate that HA-DW consistently improves performance when integrated into GRPO and its variants. Our results suggest that correcting biased advantage estimation is critical for robust and efficient RLVR training.
EvolSQL: Structure-Aware Evolution for Scalable Text-to-SQL Data Synthesis
Jan 08, 2026Training effective Text-to-SQL models remains challenging due to the scarcity of high-quality, diverse, and structurally complex datasets. Existing methods either rely on limited human-annotated corpora, or synthesize datasets directly by simply prompting LLMs without explicit control over SQL structures, often resulting in limited structural diversity and complexity. To address this, we introduce EvolSQL, a structure-aware data synthesis framework that evolves SQL queries from seed data into richer and more semantically diverse forms. EvolSQL starts with an exploratory Query-SQL expansion to broaden question diversity and improve schema coverage, and then applies an adaptive directional evolution strategy using six atomic transformation operators derived from the SQL Abstract Syntax Tree to progressively increase query complexity across relational, predicate, aggregation, and nesting dimensions. An execution-grounded SQL refinement module and schema-aware deduplication further ensure the creation of high-quality, structurally diverse mapping pairs. Experimental results show that a 7B model fine-tuned on our data outperforms one trained on the much larger SynSQL dataset using only 1/18 of the data.
AIR: Post-training Data Selection for Reasoning via Attention Head Influence
Dec 15, 2025LLMs achieve remarkable multi-step reasoning capabilities, yet effectively transferring these skills via post-training distillation remains challenging. Existing data selection methods, ranging from manual curation to heuristics based on length, entropy, or overall loss, fail to capture the causal importance of individual reasoning steps, limiting distillation efficiency. To address this, we propose Attention Influence for Reasoning (AIR), a principled, unsupervised and training-free framework that leverages mechanistic insights of the retrieval head to select high-value post-training data. AIR first identifies reasoning-critical attention heads of an off-the-shelf model, then constructs a weakened reference model with disabled head influence, and finally quantifies the resulting loss divergence as the Attention Influence Score. This score enables fine-grained assessment at both the step and sample levels, supporting step-level weighted fine-tuning and global sample selection. Experiments across multiple reasoning benchmarks show that AIR consistently improves reasoning accuracy, surpassing heuristic baselines and effectively isolating the most critical steps and samples. Our work establishes a mechanism-driven, data-efficient approach for reasoning distillation in LLMs.
NOC4SC: A Bandwidth-Efficient Multi-User Semantic Communication Framework for Interference-Resilient Transmission
Dec 10, 2025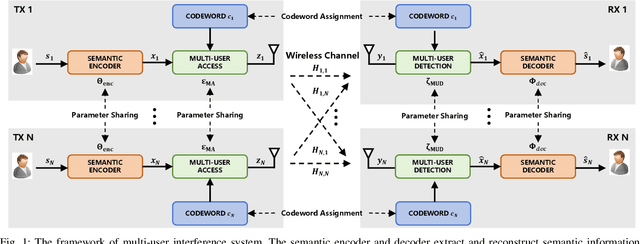
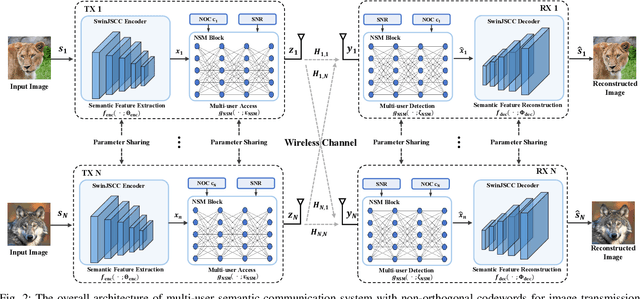
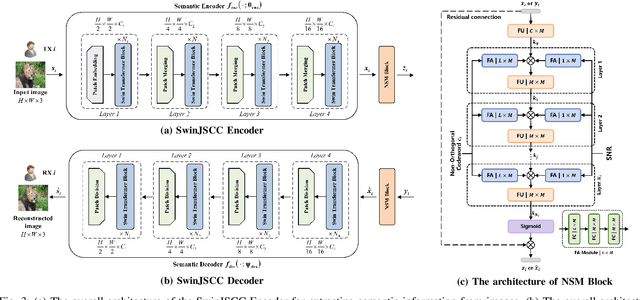
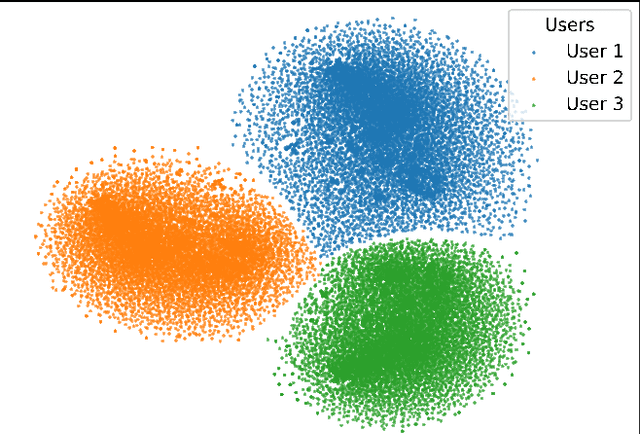
With the explosive growth of connected devices and emerging applications, current wireless networks are encountering unprecedented demands for massive user access, where the inter-user interference has become a critical challenge to maintaining high quality of service (QoS) in multi-user communication systems. To tackle this issue, we propose a bandwidth-efficient semantic communication paradigm termed Non-Orthogonal Codewords for Semantic Communication (NOC4SC), which enables simultaneous same-frequency transmission without spectrum spreading. By leveraging the Swin Transformer, the proposed NOC4SC framework enables each user to independently extract semantic features through a unified encoder-decoder architecture with shared network parameters across all users, which ensures that the user's data remains protected from unauthorized decoding. Furthermore, we introduce an adaptive NOC and SNR Modulation (NSM) block, which employs deep learning to dynamically regulate SNR and generate approximately orthogonal semantic features within distinct feature subspaces, thereby effectively mitigating inter-user interference. Extensive experiments demonstrate the proposed NOC4SC achieves comparable performance to the DeepJSCC-PNOMA and outperforms other multi-user SemCom baseline methods.
SITP: A High-Reliability Semantic Information Transport Protocol Without Retransmission for Semantic Communication
Dec 10, 2025With the evolution of 6G networks, modern communication systems are facing unprecedented demands for high reliability and low latency. However, conventional transport protocols are designed for bit-level reliability, failing to meet the semantic robustness requirements. To address this limitation, this paper proposes a novel Semantic Information Transport Protocol (SITP), which achieves TCP-level reliability and UDP level latency by verifying only packet headers while retaining potentially corrupted payloads for semantic decoding. Building upon SITP, a cross-layer analytical model is established to quantify packet-loss probability across the physical, data-link, network, transport, and application layers. The model provides a unified probabilistic formulation linking signal noise rate (SNR) and packet-loss rate, offering theoretical foundation into end-to-end semantic transmission. Furthermore, a cross-image feature interleaving mechanism is developed to mitigate consecutive burst losses by redistributing semantic features across multiple correlated images, thereby enhancing robustness in burst-fade channels. Extensive experiments show that SITP offers lower latency than TCP with comparable reliability at low SNRs, while matching UDP-level latency and delivering superior reconstruction quality. In addition, the proposed cross-image semantic interleaving mechanism further demonstrates its effectiveness in mitigating degradation caused by bursty packet losses.