 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMRModel: A Large Language Model for Extracting Medical Consultation Dialogues into Structured Medical Records
Apr 23, 2025Medical consultation dialogues contain critical clinical information, yet their unstructured nature hinders effective utilization in diagnosis and treatment. Traditional methods, relying on rule-based or shallow machine learning techniques, struggle to capture deep and implicit semantics. Recently, large pre-trained language models and Low-Rank Adaptation (LoRA), a lightweight fine-tuning method, have shown promise for structured information extraction. We propose EMRModel, a novel approach that integrates LoRA-based fine-tuning with code-style prompt design, aiming to efficiently convert medical consultation dialogues into structured electronic medical records (EMRs). Additionally, we construct a high-quality, realistically grounded dataset of medical consultation dialogues with detailed annotations. Furthermore, we introduce a fine-grained evaluation benchmark for medical consultation information extraction and provide a systematic evaluation methodology, advancing the optimization of medical natural language processing (NLP) models. Experimental results show EMRModel achieves an F1 score of 88.1%, improving by49.5% over standard pre-trained models. Compared to traditional LoRA fine-tuning methods, our model shows superior performance, highlighting its effectiveness in structured medical record extraction tasks.
Leveraging Labelled Data Knowledge: A Cooperative Rectification Learning Network for Semi-supervised 3D Medical Image Segmentation
Feb 17, 2025Semi-supervised 3D medical image segmentation aims to achieve accurate segmentation using few labelled data and numerous unlabelled data. The main challenge in the design of semi-supervised learning methods consists in the effective use of the unlabelled data for training. A promising solution consists of ensuring consistent predictions across different views of the data, where the efficacy of this strategy depends on the accuracy of the pseudo-labels generated by the model for this consistency learning strategy. In this paper, we introduce a new methodology to produce high-quality pseudo-labels for a consistency learning strategy to address semi-supervised 3D medical image segmentation. The methodology has three important contributions. The first contribution is the Cooperative Rectification Learning Network (CRLN) that learns multiple prototypes per class to be used as external knowledge priors to adaptively rectify pseudo-labels at the voxel level. The second contribution consists of the Dynamic Interaction Module (DIM) to facilitate pairwise and cross-class interactions between prototypes and multi-resolution image features, enabling the production of accurate voxel-level clues for pseudo-label rectification. The third contribution is the Cooperative Positive Supervision (CPS), which optimises uncertain representations to align with unassertive representations of their class distributions, improving the model's accuracy in classifying uncertain regions. Extensive experiments on three public 3D medical segmentation datasets demonstrate the effectiveness and superiority of our semi-supervised learning method.
Improving Multi-Label Contrastive Learning by Leveraging Label Distribution
Jan 31, 2025



In multi-label learning, leveraging contrastive learning to learn better representations faces a key challenge: selecting positive and negative samples and effectively utilizing label information. Previous studies selected positive and negative samples based on the overlap between labels and used them for label-wise loss balancing. However, these methods suffer from a complex selection process and fail to account for the varying importance of different labels. To address these problems, we propose a novel method that improves multi-label contrastive learning through label distribution. Specifically, when selecting positive and negative samples, we only need to consider whether there is an intersection between labels. To model the relationships between labels, we introduce two methods to recover label distributions from logical labels, based on Radial Basis Function (RBF) and contrastive loss, respectively. We evaluate our method on nine widely used multi-label datasets, including image and vector datasets. The results demonstrate that our method outperforms state-of-the-art methods in six evaluation metrics.
Low-Complexity Signal Detection for the Splitting Receiver Scheme
May 30, 2023This letter proposes a low-complexity signal detection method for the splitting receiver scheme, which achieves an excellent symbol error rate (SER) performance. Based on the three-dimensional (3D) received signal of the splitting receiver, we derive an equivalent two-dimensional (2D) signal model and develop a low-complexity signal detection method for the practical modulation scheme. The computational complexity of the proposed signal detector is reduced by at least 11.1 times as compared to the 3D signal detection scheme shown in [1]. Simulation results demonstrate that the approximation SER achieved by the low-complexity signal detection is very close to that of the accurate SER at a certain power splitting ratio.
Splitting Receiver with Multiple Antennas
Mar 08, 2023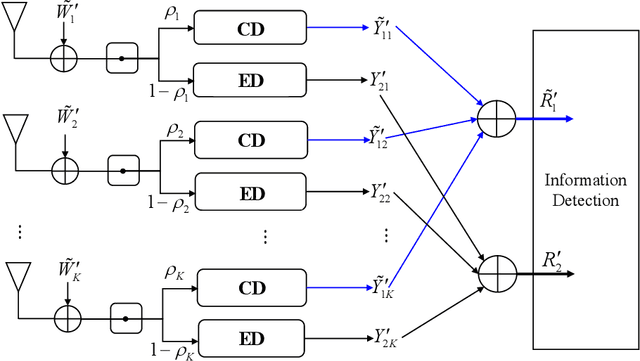
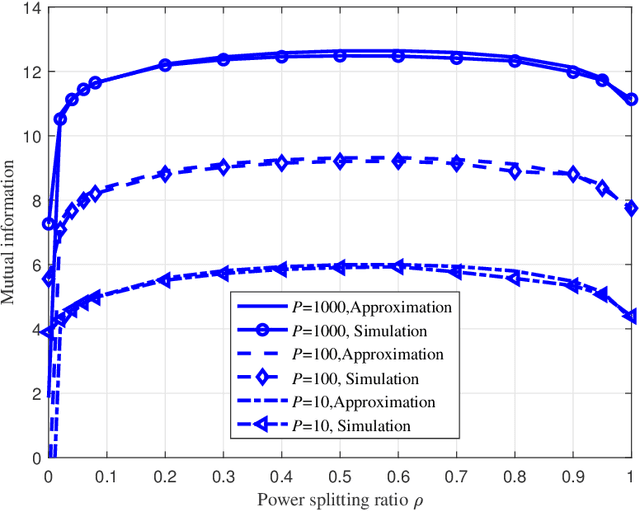
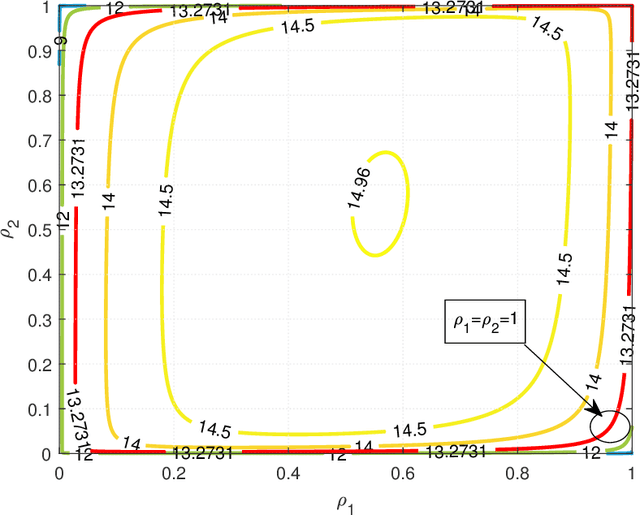
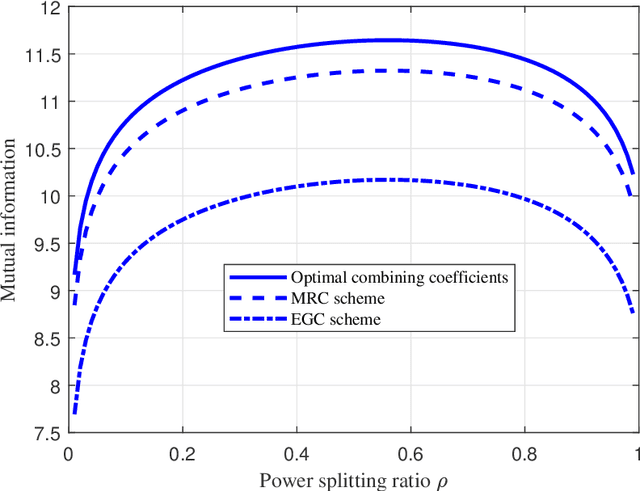
Recently proposed splitting receivers, utilizing both coherently and non-coherently processed signals for detection, have demonstrated remarkable performance gain compared to conventional receivers in the single-antenna scenario. In this paper, we propose a multi-antenna splitting receiver, where the received signal at each antenna is split into an envelope detection (ED) branch and a coherent detection (CD) branch, and the processed signals from both branches of all antennas are then jointly utilized for recovering the transmitted information. We derive a closed-form approximation of the achievable mutual information (MI) in terms of the key receiver design parameters, including the power splitting ratio at each antenna and the signal combining coefficients from all the ED and CD branches. We further optimize these receiver design parameters and demonstrate important design insights for the proposed multi-antenna ED-CD splitting receiver: 1) the optimal splitting ratio is identical at each antenna, and 2) the optimal combining coefficients for the ED and CD branches are the same, and each coefficient is proportional to the corresponding antenna's channel power gain. Our numerical results also demonstrate the MI performance improvement of the proposed receiver over conventional non-splitting receivers.
Splitting Receiver with Joint Envelope and Coherent Detection
Mar 02, 2022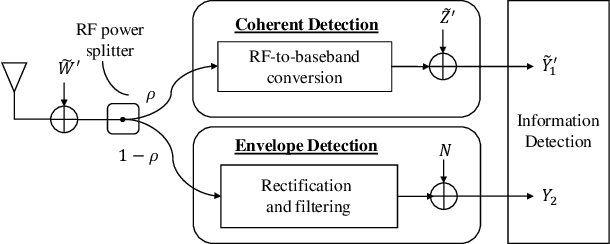
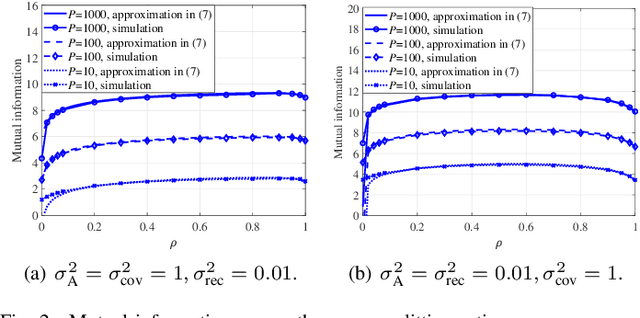
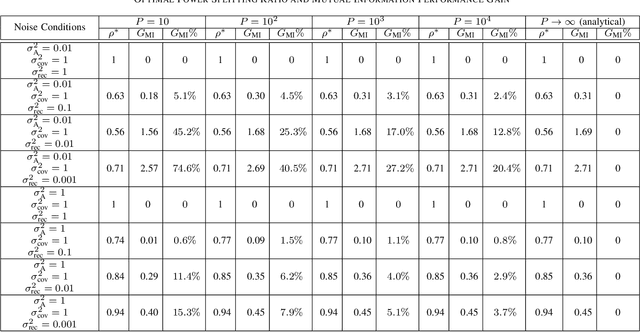
This letter proposes a new splitting receiver design with joint envelope detection (ED) and coherent detection (CD). To characterize its fundamental performance limit, we conduct high signal-to-noise ratio (SNR) analysis on the proposed ED-CD splitting receiver and obtain closed-form approximations of both the achievable mutual information and the optimal splitting ratio (i.e., a key design parameter of the receiver). Our numerical results show that these high SNR approximations are accurate over a wide range of moderate SNR values, signifying the usefulness of the obtained analytical results. We also provide insights on the conditions at which the proposed splitting receiver has significant performance advantages over the traditional receivers.
MDFEND: Multi-domain Fake News Detection
Jan 04, 2022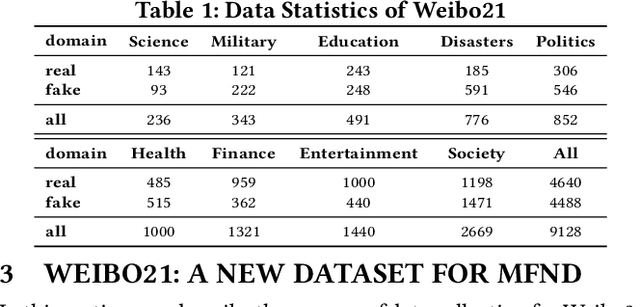

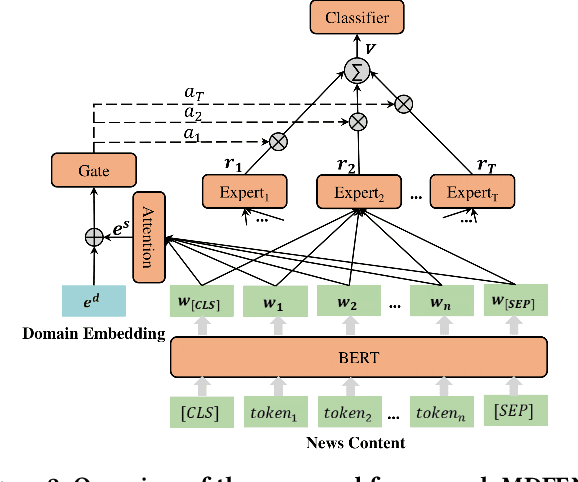
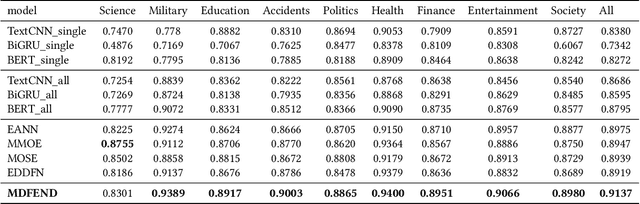
Fake news spread widely on social media in various domains, which lead to real-world threats in many aspects like politics, disasters, and finance. Most existing approaches focus on single-domain fake news detection (SFND), which leads to unsatisfying performance when these methods are applied to multi-domain fake news detection. As an emerging field, multi-domain fake news detection (MFND) is increasingly attracting attention. However, data distributions, such as word frequency and propagation patterns, vary from domain to domain, namely domain shift. Facing the challenge of serious domain shift, existing fake news detection techniques perform poorly for multi-domain scenarios. Therefore, it is demanding to design a specialized model for MFND. In this paper, we first design a benchmark of fake news dataset for MFND with domain label annotated, namely Weibo21, which consists of 4,488 fake news and 4,640 real news from 9 different domains. We further propose an effective Multi-domain Fake News Detection Model (MDFEND) by utilizing a domain gate to aggregate multiple representations extracted by a mixture of experts. The experiments show that MDFEND can significantly improve the performance of multi-domain fake news detection. Our dataset and code are available at https://github.com/kennqiang/MDFEND-Weibo21.
Gradual Machine Learning for Aspect-level Sentiment Analysis
Jul 01, 2019
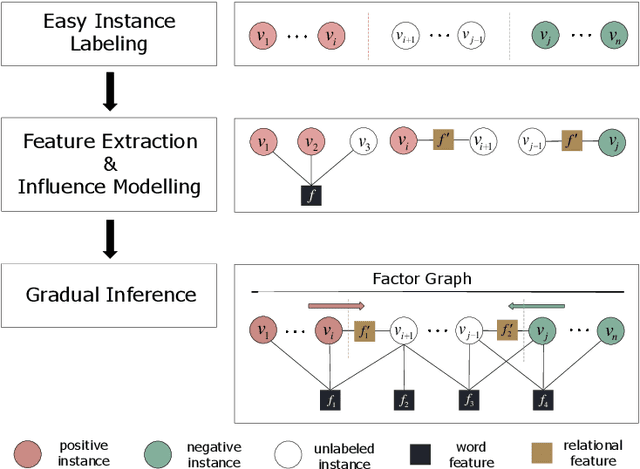

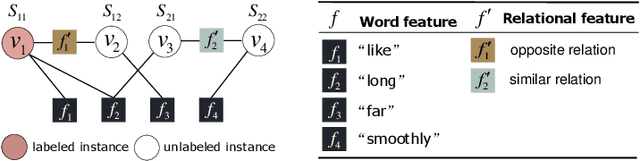
The state-of-the-art solutions for Aspect-Level Sentiment Analysis (ALSA) were built on a variety of deep neural networks (DNN), whose efficacy depends on large amounts of accurately labeled training data. Unfortunately, high-quality labeled training data usually require expensive manual work, and may thus not be readily available in real scenarios. In this paper, we propose a novel solution for ALSA based on the recently proposed paradigm of gradual machine learning, which can enable effective machine labeling without the requirement for manual labeling effort. It begins with some easy instances in an ALSA task, which can be automatically labeled by the machine with high accuracy, and then gradually labels the more challenging instances by iterative factor graph inference. In the process of gradual machine learning, the hard instances are gradually labeled in small stages based on the estimated evidential certainty provided by the labeled easier instances. Our extensive experiments on the benchmark datasets have shown that the performance of the proposed solution is considerably better than its unsupervised alternatives, and also highly competitive compared to the state-of-the-art supervised DNN techniques.
Gradual Machine Learning for Entity Resolution
Oct 29, 2018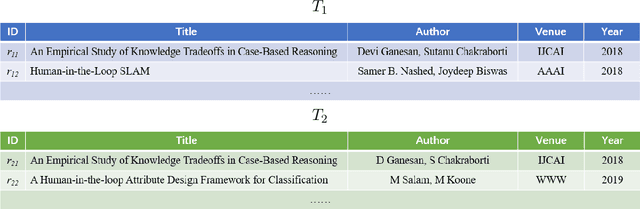

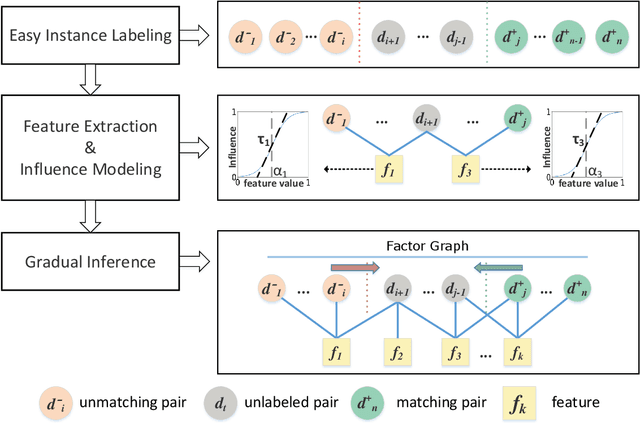
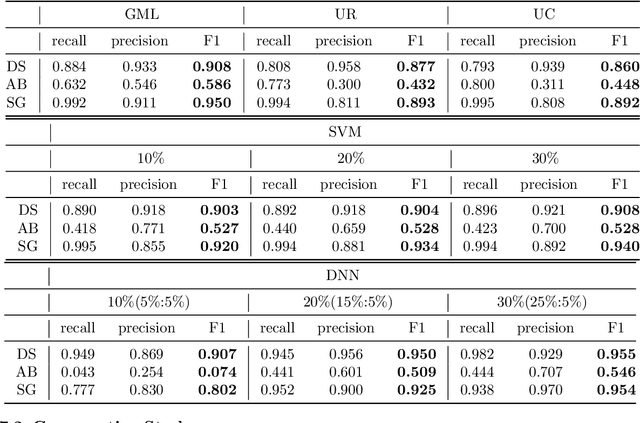
Usually considered as a classification problem, entity resolution can be very challenging on real data due to the prevalence of dirty values. The state-of-the-art solutions for ER were built on a variety of learning models (most notably deep neural networks), which require lots of accurately labeled training data. Unfortunately, high-quality labeled data usually require expensive manual work, and are therefore not readily available in many real scenarios. In this paper, we propose a novel learning paradigm for ER, called gradual machine learning, which aims to enable effective machine learning without the requirement for manual labeling effort. It begins with some easy instances in a task, which can be automatically labeled by the machine with high accuracy, and then gradually labels more challenging instances based on iterative factor graph inference. In gradual machine learning, the hard instances in a task are gradually labeled in small stages based on the estimated evidential certainty provided by the labeled easier instances. Our extensive experiments on real data have shown that the proposed approach performs considerably better than its unsupervised alternatives, and it is highly competitive with the state-of-the-art supervised techniques. Using ER as a test case, we demonstrate that gradual machine learning is a promising paradigm potentially applicable to other challenging classification tasks requiring extensive labeling effort.