 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Time-Phase Synchronization for Distributed Sensing Networks via Feature-Level Hyper-Plane Regression
Mar 30, 2026Achieving coherent integration in distributed Internet of Things (IoT) sensing networks requires precise synchronization to jointly compensate clock offsets and radio-frequency (RF) phase errors. Conventional two-step protocols suffer from time-phase coupling, where residual timing offsets degrade phase coherence. This paper proposes a generalized hyper-plane regression (GHR) framework for joint calibration by transforming coupled spatiotemporal phase evolution into a unified regression model, enabling effective parameter decoupling. To support resource-constrained IoT edge nodes, a feature-level distributed architecture is developed. By adopting a linear frequency-modulated (LFM) waveform, the model order is reduced, yielding linear computational complexity. In addition, a unidirectional feature transmission mechanism eliminates the communication overhead of bidirectional timestamp exchange, making the approach suitable for resource-constrained IoT networks. Simulation results demonstrate reliable picosecond-level synchronization accuracy under severe noise across kilometer-scale distributed IoT sensing networks.
Geometric Direction Finding on Dynamic Manifolds: Unambiguous DOA Estimation for Spatially Undersampled UWB Arrays
Mar 24, 2026Traditional Direction of Arrival (DOA) estimation methods struggle to simultaneously address three physical constraints in Ultra-Wideband (UWB) electromagnetic sensing: spatial undersampling, asynchronous array phase, and beam squint. Existing solutions treat these issues in isolation, leading to limited performance in complex scenarios. This paper proposes a novel dynamic manifold perspective, which models UWB signal observations as a continuous manifold curve in a high-dimensional space driven by temporal evolution and array topology. We theoretically demonstrate that the DOA can be uniquely determined solely by the geometric shape of the manifold, rather than the absolute arrival phase. Based on this perspective, we construct a geometric parameter system comprising extrinsic and intrinsic parameters, along with a corresponding DOA estimation framework. Extrinsic vector parameters serve as a dynamic extension of traditional array processing, effectively expanding the degrees of freedom to suppress grating lobes. Intrinsic scalar invariants provide a new geometric perspective independent of traditional phase models, offering intrinsic robustness against array channel phase errors. Simulation results show that the derived analytical expressions for geometric parameters are highly consistent with numerical truths. The proposed framework not only completely eliminates spatial ambiguity in sparse arrays but also achieves high-precision direction finding under conditions with calibration-free phase errors.
Enhance and Reuse: A Dual-Mechanism Approach to Boost Deep Forest for Label Distribution Learning
Feb 06, 2026Label distribution learning (LDL) requires the learner to predict the degree of correlation between each sample and each label. To achieve this, a crucial task during learning is to leverage the correlation among labels. Deep Forest (DF) is a deep learning framework based on tree ensembles, whose training phase does not rely on backpropagation. DF performs in-model feature transform using the prediction of each layer and achieves competitive performance on many tasks. However, its exploration in the field of LDL is still in its infancy. The few existing methods that apply DF to the field of LDL do not have effective ways to utilize the correlation among labels. Therefore, we propose a method named Enhanced and Reused Feature Deep Forest (ERDF). It mainly contains two mechanisms: feature enhancement exploiting label correlation and measure-aware feature reuse. The first one is to utilize the correlation among labels to enhance the original features, enabling the samples to acquire more comprehensive information for the task of LDL. The second one performs a reuse operation on the features of samples that perform worse than the previous layer on the validation set, in order to ensure the stability of the training process. This kind of Enhance-Reuse pattern not only enables samples to enrich their features but also validates the effectiveness of their new features and conducts a reuse process to prevent the noise from spreading further. Experiments show that our method outperforms other comparison algorithms on six evaluation metrics.
Pose as a Modality: A Psychology-Inspired Network for Personality Recognition with a New Multimodal Dataset
Mar 17, 2025In recent years, predicting Big Five personality traits from multimodal data has received significant attention in artificial intelligence (AI). However, existing computational models often fail to achieve satisfactory performance. Psychological research has shown a strong correlation between pose and personality traits, yet previous research has largely ignored pose data in computational models. To address this gap, we develop a novel multimodal dataset that incorporates full-body pose data. The dataset includes video recordings of 287 participants completing a virtual interview with 36 questions, along with self-reported Big Five personality scores as labels. To effectively utilize this multimodal data, we introduce the Psychology-Inspired Network (PINet), which consists of three key modules: Multimodal Feature Awareness (MFA), Multimodal Feature Interaction (MFI), and Psychology-Informed Modality Correlation Loss (PIMC Loss). The MFA module leverages the Vision Mamba Block to capture comprehensive visual features related to personality, while the MFI module efficiently fuses the multimodal features. The PIMC Loss, grounded in psychological theory, guides the model to emphasize different modalities for different personality dimensions. Experimental results show that the PINet outperforms several state-of-the-art baseline models. Furthermore, the three modules of PINet contribute almost equally to the model's overall performance. Incorporating pose data significantly enhances the model's performance, with the pose modality ranking mid-level in importance among the five modalities. These findings address the existing gap in personality-related datasets that lack full-body pose data and provide a new approach for improving the accuracy of personality prediction models, highlighting the importance of integrating psychological insights into AI frameworks.
Improving Multi-Label Contrastive Learning by Leveraging Label Distribution
Jan 31, 2025



In multi-label learning, leveraging contrastive learning to learn better representations faces a key challenge: selecting positive and negative samples and effectively utilizing label information. Previous studies selected positive and negative samples based on the overlap between labels and used them for label-wise loss balancing. However, these methods suffer from a complex selection process and fail to account for the varying importance of different labels. To address these problems, we propose a novel method that improves multi-label contrastive learning through label distribution. Specifically, when selecting positive and negative samples, we only need to consider whether there is an intersection between labels. To model the relationships between labels, we introduce two methods to recover label distributions from logical labels, based on Radial Basis Function (RBF) and contrastive loss, respectively. We evaluate our method on nine widely used multi-label datasets, including image and vector datasets. The results demonstrate that our method outperforms state-of-the-art methods in six evaluation metrics.
SSFam: Scribble Supervised Salient Object Detection Family
Sep 07, 2024
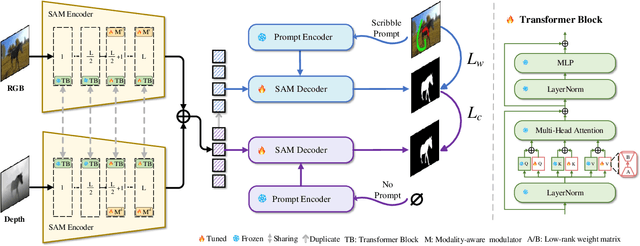
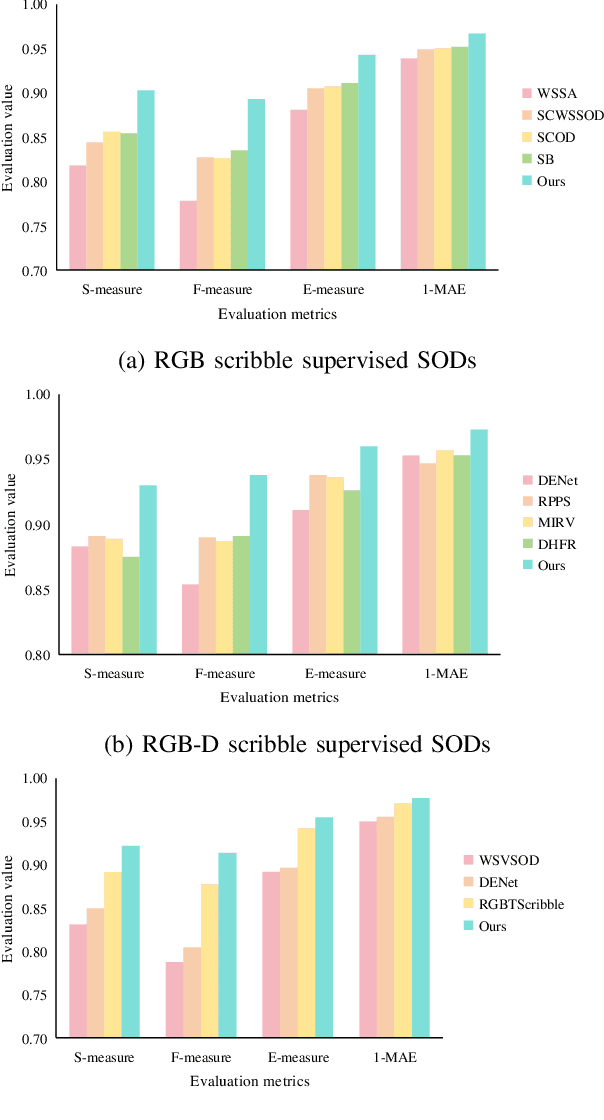

Scribble supervised salient object detection (SSSOD) constructs segmentation ability of attractive objects from surroundings under the supervision of sparse scribble labels. For the better segmentation, depth and thermal infrared modalities serve as the supplement to RGB images in the complex scenes. Existing methods specifically design various feature extraction and multi-modal fusion strategies for RGB, RGB-Depth, RGB-Thermal, and Visual-Depth-Thermal image input respectively, leading to similar model flood. As the recently proposed Segment Anything Model (SAM) possesses extraordinary segmentation and prompt interactive capability, we propose an SSSOD family based on SAM, named SSFam, for the combination input with different modalities. Firstly, different modal-aware modulators are designed to attain modal-specific knowledge which cooperates with modal-agnostic information extracted from the frozen SAM encoder for the better feature ensemble. Secondly, a siamese decoder is tailored to bridge the gap between the training with scribble prompt and the testing with no prompt for the stronger decoding ability. Our model demonstrates the remarkable performance among combinations of different modalities and refreshes the highest level of scribble supervised methods and comes close to the ones of fully supervised methods. https://github.com/liuzywen/SSFam
A Fast Power Spectrum Sensing Solution for Generalized Coprime Sampling
Nov 23, 2023The growing scarcity of spectrum resources, wideband spectrum sensing is required to process a prohibitive volume of data at a high sampling rate. For some applications, spectrum estimation only requires second-order statistics. In this case, a fast power spectrum sensing solution is proposed based on the generalized coprime sampling. By exploring the sensing vector inherent structure, the autocorrelation sequence of inputs can be reconstructed from sub-Nyquist samples by only utilizing the parallel Fourier transform and simple multiplication operations. Thus, it takes less time than the state-of-the-art methods while maintaining the same performance, and it achieves higher performance than the existing methods within the same execution time, without the need for pre-estimating the number of inputs. Furthermore, the influence of the model mismatch has only a minor impact on the estimation performance, which allows for more efficient use of the spectrum resource in a distributed swarm scenario. Simulation results demonstrate the low complexity in sampling and computation, making it a more practical solution for real-time and distributed wideband spectrum sensing applications.
Multiscale Motion-Aware and Spatial-Temporal-Channel Contextual Coding Network for Learned Video Compression
Oct 19, 2023Recently, learned video compression has achieved exciting performance. Following the traditional hybrid prediction coding framework, most learned methods generally adopt the motion estimation motion compensation (MEMC) method to remove inter-frame redundancy. However, inaccurate motion vector (MV) usually lead to the distortion of reconstructed frame. In addition, most approaches ignore the spatial and channel redundancy. To solve above problems, we propose a motion-aware and spatial-temporal-channel contextual coding based video compression network (MASTC-VC), which learns the latent representation and uses variational autoencoders (VAEs) to capture the characteristics of intra-frame pixels and inter-frame motion. Specifically, we design a multiscale motion-aware module (MS-MAM) to estimate spatial-temporal-channel consistent motion vector by utilizing the multiscale motion prediction information in a coarse-to-fine way. On the top of it, we further propose a spatial-temporal-channel contextual module (STCCM), which explores the correlation of latent representation to reduce the bit consumption from spatial, temporal and channel aspects respectively. Comprehensive experiments show that our proposed MASTC-VC is surprior to previous state-of-the-art (SOTA) methods on three public benchmark datasets. More specifically, our method brings average 10.15\% BD-rate savings against H.265/HEVC (HM-16.20) in PSNR metric and average 23.93\% BD-rate savings against H.266/VVC (VTM-13.2) in MS-SSIM metric.
Wideband Spectrum Acquisition for UAV Swarm Using the Sparse Coding Fourier Transform
Aug 14, 2023



As the trend towards small, safe, smart, speedy and swarm development grows, unmanned aerial vehicles (UAVs) are becoming increasingly popular for a wide range of applications. In this letter, the challenge of wideband spectrum acquisition for the UAV swarms is studied by proposing a processing method that features lower power consumption, higher compression rates, and a lower signal-to-noise ratio. Our system is equipped with multiple UAVs, each with a different sub-sampling rate. That allows for frequency backetization and estimation based on sparse Fourier transform theory. Unlike other techniques, the collisions and iterations caused by non-sparsity environ-ments are considered. We introduce sparse coding Fourier transform to address these issues. The key is to code the entire spectrum and decode it through spectrum correlation in the code. Simulation results show that our proposed method performs well in acquiring both narrowband and wideband signals simultaneously, compared to the other methods.
Distributed UAV Swarm Augmented Wideband Spectrum Sensing Using Nyquist Folding Receiver
Aug 14, 2023Distributed unmanned aerial vehicle (UAV) swarms are formed by multiple UAVs with increased portability, higher levels of sensing capabilities, and more powerful autonomy. These features make them attractive for many recent applica-tions, potentially increasing the shortage of spectrum resources. In this paper, wideband spectrum sensing augmented technology is discussed for distributed UAV swarms to improve the utilization of spectrum. However, the sub-Nyquist sampling applied in existing schemes has high hardware complexity, power consumption, and low recovery efficiency for non-strictly sparse conditions. Thus, the Nyquist folding receiver (NYFR) is considered for the distributed UAV swarms, which can theoretically achieve full-band spectrum detection and reception using a single analog-to-digital converter (ADC) at low speed for all circuit components. There is a focus on the sensing model of two multichannel scenarios for the distributed UAV swarms, one with a complete functional receiver for the UAV swarm with RIS, and another with a decentralized UAV swarm equipped with a complete functional receiver for each UAV element. The key issue is to consider whether the application of RIS technology will bring advantages to spectrum sensing and the data fusion problem of decentralized UAV swarms based on the NYFR architecture. Therefore, the property for multiple pulse reconstruction is analyzed through the Gershgorin circle theorem, especially for very short pulses. Further, the block sparse recovery property is analyzed for wide bandwidth signals. The proposed technology can improve the processing capability for multiple signals and wide bandwidth signals while reducing interference from folded noise and subsampled harmonics. Experiment results show augmented spectrum sensing efficiency under non-strictly sparse conditions.