 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHRTransNet: HRFormer-Driven Two-Modality Salient Object Detection
Paper and Code
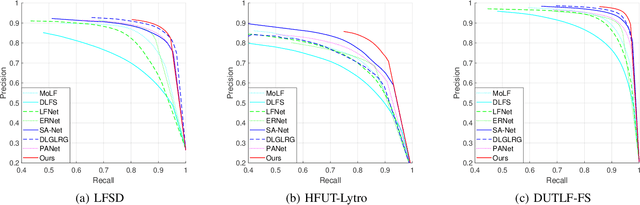

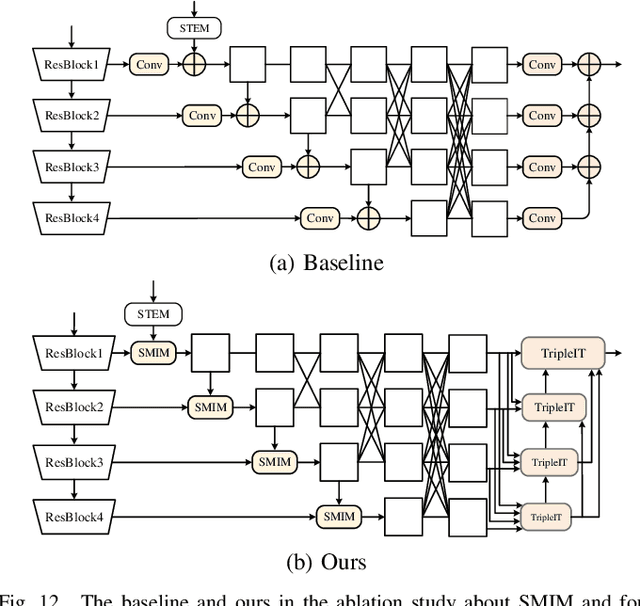
The High-Resolution Transformer (HRFormer) can maintain high-resolution representation and share global receptive fields. It is friendly towards salient object detection (SOD) in which the input and output have the same resolution. However, two critical problems need to be solved for two-modality SOD. One problem is two-modality fusion. The other problem is the HRFormer output's fusion. To address the first problem, a supplementary modality is injected into the primary modality by using global optimization and an attention mechanism to select and purify the modality at the input level. To solve the second problem, a dual-direction short connection fusion module is used to optimize the output features of HRFormer, thereby enhancing the detailed representation of objects at the output level. The proposed model, named HRTransNet, first introduces an auxiliary stream for feature extraction of supplementary modality. Then, features are injected into the primary modality at the beginning of each multi-resolution branch. Next, HRFormer is applied to achieve forwarding propagation. Finally, all the output features with different resolutions are aggregated by intra-feature and inter-feature interactive transformers. Application of the proposed model results in impressive improvement for driving two-modality SOD tasks, e.g., RGB-D, RGB-T, and light field SOD.https://github.com/liuzywen/HRTransNet