 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferSeg: Towards Diverse Multimodal Binary Segmentation via Differential Perception and Frequency Guidance
Jun 08, 2026In many binary segmentation tasks, most multimodal methods rely on fixed feature concatenation for cross-modal interaction and straightforward decoder designs dominated by low-frequency semantics. %ToDO: % However, they ignore two key challenges: one is the lack of an adaptive mechanism to handle modality discrepancies and complementarity, and the other is the absence of an efficient decoding strategy to balance both high- and low-frequency representations. % In this work, we propose a simple yet general multimodal binary segmentation framework, termed DifferSeg, to address both problems simultaneously. With the help of the differential perception fusion (DPF) module, DifferSeg employs learnable differential operators to adaptively align multimodal features and enhance their complementarity through residual fusion, effectively mitigating modality mismatch and fusion redundancy. % In addition, we design a frequency-guided decoder (FGD) that builds cross-frequency interactions and multi-path upsampling to maintain consistency between detailed high-frequency structures and semantic low-frequency representations, ensuring fine-grained boundary recovery and noise suppression. % Benefiting from these designs, DifferSeg can be easily generalized to diverse binary segmentation tasks, including both natural and medical modalities. Without bells and whistles, it consistently surpasses 67 state-of-the-art methods across 29 public datasets involving 18 downstream tasks, demonstrating superior generalization and segmentation accuracy.Code and pretrained models will be available at the Link.
Hyperbolic and Evidence-Prioritized Experts for Large Vision-Language Models
May 29, 2026Large Vision-Language Models (LVLMs) have demonstrated impressive performance on multimodal tasks through scaled architectures and extensive training. Recent studies introduce Mixture of Experts (MoE) into LVLMs for improved computational efficiency. However, existing MoE approaches treat visual and linguistic modalities with symmetric architectures, overlooking the inherent asymmetry in how these two modalities are processed. This asymmetry causes two critical issues. First, text and vision form hierarchical rather than parallel relationships, as text queries typically describe partial aspects of complete visual scenes. Euclidean expert space struggles to encode such containment structures. Second, language experts in deeper layers progressively shift from evidence-based processing to parametric memory dependence, losing grounding in the provided visual and linguistic information. To address these issues, we propose AsyMoE, a novel architecture that explicitly models this asymmetry through three specialized expert groups. Intra-modality experts handle modality-specific processing. Hyperbolic inter-modality experts capture hierarchical cross-modal relationships through negative curvature geometry. Evidence-priority language experts suppress parametric memory activation and maintain contextual grounding throughout network depth. Extensive experiments demonstrate that AsyMoE achieves consistent improvements over baseline methods, with average gains of 1.5\% over MoE variants and up to 3.8\% on hallucination-sensitive tasks. AsyMoE activates 25.45\% fewer parameters compared to dense models.
NTIRE 2026 The 3rd Restore Any Image Model (RAIM) Challenge: Professional Image Quality Assessment (Track 1)
Apr 14, 2026In this paper, we present an overview of the NTIRE 2026 challenge on the 3rd Restore Any Image Model in the Wild, specifically focusing on Track 1: Professional Image Quality Assessment. Conventional Image Quality Assessment (IQA) typically relies on scalar scores. By compressing complex visual characteristics into a single number, these methods fundamentally struggle to distinguish subtle differences among uniformly high-quality images. Furthermore, they fail to articulate why one image is superior, lacking the reasoning capabilities required to provide guidance for vision tasks. To bridge this gap, recent advancements in Multimodal Large Language Models (MLLMs) offer a promising paradigm. Inspired by this potential, our challenge establishes a novel benchmark exploring the ability of MLLMs to mimic human expert cognition in evaluating high-quality image pairs. Participants were tasked with overcoming critical bottlenecks in professional scenarios, centering on two primary objectives: (1) Comparative Quality Selection: reliably identifying the visually superior image within a high-quality pair; and (2) Interpretative Reasoning: generating grounded, expert-level explanations that detail the rationale behind the selection. In total, the challenge attracted nearly 200 registrations and over 2,500 submissions. The top-performing methods significantly advanced the state of the art in professional IQA. The challenge dataset is available at https://github.com/narthchin/RAIM-PIQA, and the official homepage is accessible at https://www.codabench.org/competitions/12789/.
LoViF 2026 Challenge on Human-oriented Semantic Image Quality Assessment: Methods and Results
Apr 13, 2026This paper reviews the LoViF 2026 Challenge on Human-oriented Semantic Image Quality Assessment. This challenge aims to raise a new direction, i.e., how to evaluate the loss of semantic information from the human perspective, intending to promote the development of some new directions, like semantic coding, processing, and semantic-oriented optimization, etc. Unlike existing datasets of quality assessment, we form a dataset of human-oriented semantic quality assessment, termed the SeIQA dataset. This dataset is divided into three parts for this competition: (i) training data: 510 pairs of degraded images and their corresponding ground truth references; (ii) validation data: 80 pairs of degraded images and their corresponding ground-truth references; (iii) testing data: 160 pairs of degraded images and their corresponding ground-truth references. The primary objective of this challenge is to establish a new and powerful benchmark for human-oriented semantic image quality assessment. There are a total of 58 teams registered in this competition, and 6 teams submitted valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the SeIQA dataset.
TP-Seg: Task-Prototype Framework for Unified Medical Lesion Segmentation
Apr 01, 2026Building a unified model with a single set of parameters to efficiently handle diverse types of medical lesion segmentation has become a crucial objective for AI-assisted diagnosis. Existing unified segmentation approaches typically rely on shared encoders across heterogeneous tasks and modalities, which often leads to feature entanglement, gradient interference, and suboptimal lesion discrimination. In this work, we propose TP-Seg, a task-prototype framework for unified medical lesion segmentation. On one hand, the task-conditioned adapter effectively balances shared and task-specific representations through a dual-path expert structure, enabling adaptive feature extraction across diverse medical imaging modalities and lesion types. On the other hand, the prototype-guided task decoder introduces learnable task prototypes as semantic anchors and employs a cross-attention mechanism to achieve fine-grained modeling of task-specific foreground and background semantics. Without bells and whistles, TP-Seg consistently outperforms specialized, general and unified segmentation methods across 8 different medical lesion segmentation tasks covering multiple imaging modalities, demonstrating strong generalization, scalability and clinical applicability.
DP^2-VL: Private Photo Dataset Protection by Data Poisoning for Vision-Language Models
Mar 25, 2026Recent advances in visual-language alignment have endowed vision-language models (VLMs) with fine-grained image understanding capabilities. However, this progress also introduces new privacy risks. This paper first proposes a novel privacy threat model named identity-affiliation learning: an attacker fine-tunes a VLM using only a few private photos of a target individual, thereby embedding associations between the target facial identity and their private property and social relationships into the model's internal representations. Once deployed via public APIs, this model enables unauthorized exposure of the target user's private information upon input of their photos. To benchmark VLMs' susceptibility to such identity-affiliation leakage, we introduce the first identity-affiliation dataset comprising seven typical scenarios appearing in private photos. Each scenario is instantiated with multiple identity-centered photo-description pairs. Experimental results demonstrate that mainstream VLMs like LLaVA, Qwen-VL, and MiniGPT-v2, can recognize facial identities and infer identity-affiliation relationships by fine-tuning on small-scale private photographic dataset, and even on synthetically generated datasets. To mitigate this privacy risk, we propose DP2-VL, the first Dataset Protection framework for private photos that leverages Data Poisoning. Though optimizing imperceptible perturbations by pushing the original representations toward an antithetical region, DP2-VL induces a dataset-level shift in the embedding space of VLMs'encoders. This shift separates protected images from clean inference images, causing fine-tuning on the protected set to overfit. Extensive experiments demonstrate that DP2-VL achieves strong generalization across models, robustness to diverse post-processing operations, and consistent effectiveness across varying protection ratios.
LifeEval: A Multimodal Benchmark for Assistive AI in Egocentric Daily Life Tasks
Feb 28, 2026The rapid progress of Multimodal Large Language Models (MLLMs) marks a significant step toward artificial general intelligence, offering great potential for augmenting human capabilities. However, their ability to provide effective assistance in dynamic, real-world environments remains largely underexplored. Existing video benchmarks predominantly assess passive understanding through retrospective analysis or isolated perception tasks, failing to capture the interactive and adaptive nature of real-time user assistance. To bridge this gap, we introduce LifeEval, a multimodal benchmark designed to evaluate real-time, task-oriented human-AI collaboration in daily life from an egocentric perspective. LifeEval emphasizes three key aspects: task-oriented holistic evaluation, egocentric real-time perception from continuous first-person streams, and human-assistant collaborative interaction through natural dialogues. Constructed via a rigorous annotation pipeline, the benchmark comprises 4,075 high-quality question-answer pairs across 6 core capability dimensions. Extensive evaluations of 26 state-of-the-art MLLMs on LifeEval reveal substantial challenges in achieving timely, effective and adaptive interaction, highlighting essential directions for advancing human-centered interactive intelligence.
Surveillance Facial Image Quality Assessment: A Multi-dimensional Dataset and Lightweight Model
Feb 07, 2026Surveillance facial images are often captured under unconstrained conditions, resulting in severe quality degradation due to factors such as low resolution, motion blur, occlusion, and poor lighting. Although recent face restoration techniques applied to surveillance cameras can significantly enhance visual quality, they often compromise fidelity (i.e., identity-preserving features), which directly conflicts with the primary objective of surveillance images -- reliable identity verification. Existing facial image quality assessment (FIQA) predominantly focus on either visual quality or recognition-oriented evaluation, thereby failing to jointly address visual quality and fidelity, which are critical for surveillance applications. To bridge this gap, we propose the first comprehensive study on surveillance facial image quality assessment (SFIQA), targeting the unique challenges inherent to surveillance scenarios. Specifically, we first construct SFIQA-Bench, a multi-dimensional quality assessment benchmark for surveillance facial images, which consists of 5,004 surveillance facial images captured by three widely deployed surveillance cameras in real-world scenarios. A subjective experiment is conducted to collect six dimensional quality ratings, including noise, sharpness, colorfulness, contrast, fidelity and overall quality, covering the key aspects of SFIQA. Furthermore, we propose SFIQA-Assessor, a lightweight multi-task FIQA model that jointly exploits complementary facial views through cross-view feature interaction, and employs learnable task tokens to guide the unified regression of multiple quality dimensions. The experiment results on the proposed dataset show that our method achieves the best performance compared with the state-of-the-art general image quality assessment (IQA) and FIQA methods, validating its effectiveness for real-world surveillance applications.
QualiRAG: Retrieval-Augmented Generation for Visual Quality Understanding
Jan 26, 2026Visual quality assessment (VQA) is increasingly shifting from scalar score prediction toward interpretable quality understanding -- a paradigm that demands \textit{fine-grained spatiotemporal perception} and \textit{auxiliary contextual information}. Current approaches rely on supervised fine-tuning or reinforcement learning on curated instruction datasets, which involve labor-intensive annotation and are prone to dataset-specific biases. To address these challenges, we propose \textbf{QualiRAG}, a \textit{training-free} \textbf{R}etrieval-\textbf{A}ugmented \textbf{G}eneration \textbf{(RAG)} framework that systematically leverages the latent perceptual knowledge of large multimodal models (LMMs) for visual quality perception. Unlike conventional RAG that retrieves from static corpora, QualiRAG dynamically generates auxiliary knowledge by decomposing questions into structured requests and constructing four complementary knowledge sources: \textit{visual metadata}, \textit{subject localization}, \textit{global quality summaries}, and \textit{local quality descriptions}, followed by relevance-aware retrieval for evidence-grounded reasoning. Extensive experiments show that QualiRAG achieves substantial improvements over open-source general-purpose LMMs and VQA-finetuned LMMs on visual quality understanding tasks, and delivers competitive performance on visual quality comparison tasks, demonstrating robust quality assessment capabilities without any task-specific training. The code will be publicly available at https://github.com/clh124/QualiRAG.
VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models: Methods and Results
Sep 11, 2025
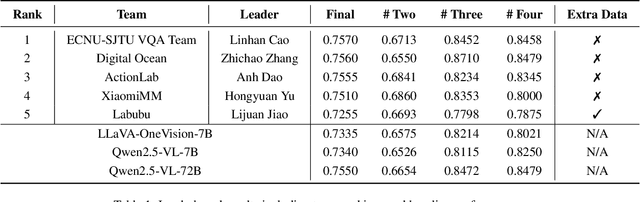
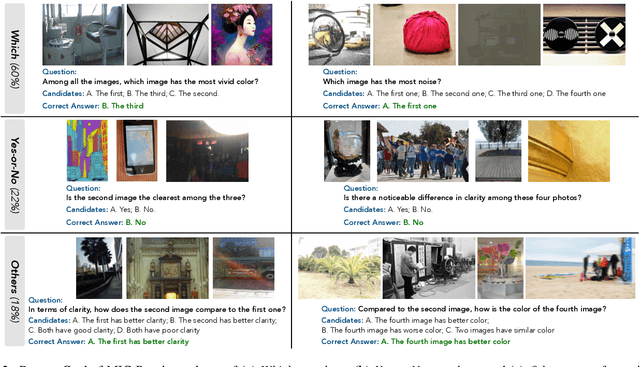
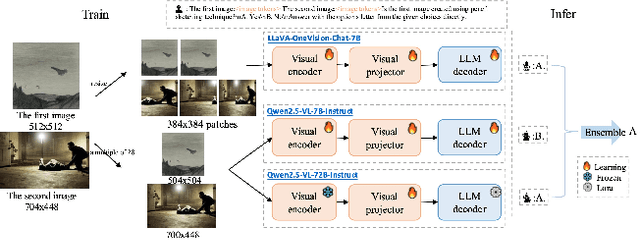
This paper presents a summary of the VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models (LMMs), hosted as part of the ICCV 2025 Workshop on Visual Quality Assessment. The challenge aims to evaluate and enhance the ability of state-of-the-art LMMs to perform open-ended and detailed reasoning about visual quality differences across multiple images. To this end, the competition introduces a novel benchmark comprising thousands of coarse-to-fine grained visual quality comparison tasks, spanning single images, pairs, and multi-image groups. Each task requires models to provide accurate quality judgments. The competition emphasizes holistic evaluation protocols, including 2AFC-based binary preference and multi-choice questions (MCQs). Around 100 participants submitted entries, with five models demonstrating the emerging capabilities of instruction-tuned LMMs on quality assessment. This challenge marks a significant step toward open-domain visual quality reasoning and comparison and serves as a catalyst for future research on interpretable and human-aligned quality evaluation systems.