 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAIR: Cost-Efficient Multi-Stage ML Pipeline Autoscaling via In-Context Reinforcement Learning
Jan 29, 2026Multi-stage ML inference pipelines are difficult to autoscale due to heterogeneous resources, cross-stage coupling, and dynamic bottleneck migration. We present SAIR, an autoscaling framework that uses an LLM as an in-context reinforcement learning controller, improving its policy online from reward-labeled interaction histories without gradient updates. SAIR combines Pareto-dominance reward shaping with a provable separation margin, surprisal-guided experience retrieval for context efficiency, and fine-grained GPU rate control via user-space CUDA interception. We provide regret analysis decomposing error into retrieval coverage and LLM selection components. On four ML serving pipelines under three workload patterns, SAIR achieves the best or tied-best P99 latency and effective resource cost among deployed baselines, improving P99 by up to 50% and reducing effective cost by up to 97% (under GPU rate-control assumptions), with 86% bottleneck detection accuracy and no offline training.
Human-LLM Collaborative Feature Engineering for Tabular Data
Jan 28, 2026Large language models (LLMs) are increasingly used to automate feature engineering in tabular learning. Given task-specific information, LLMs can propose diverse feature transformation operations to enhance downstream model performance. However, current approaches typically assign the LLM as a black-box optimizer, responsible for both proposing and selecting operations based solely on its internal heuristics, which often lack calibrated estimations of operation utility and consequently lead to repeated exploration of low-yield operations without a principled strategy for prioritizing promising directions. In this paper, we propose a human-LLM collaborative feature engineering framework for tabular learning. We begin by decoupling the transformation operation proposal and selection processes, where LLMs are used solely to generate operation candidates, while the selection is guided by explicitly modeling the utility and uncertainty of each proposed operation. Since accurate utility estimation can be difficult especially in the early rounds of feature engineering, we design a mechanism within the framework that selectively elicits and incorporates human expert preference feedback, comparing which operations are more promising, into the selection process to help identify more effective operations. Our evaluations on both the synthetic study and the real user study demonstrate that the proposed framework improves feature engineering performance across a variety of tabular datasets and reduces users' cognitive load during the feature engineering process.
Dynamic Expert Quantization for Scalable Mixture-of-Experts Inference
Nov 19, 2025Mixture-of-Experts (MoE) models scale LLM capacity efficiently, but deployment on consumer GPUs is limited by the large memory footprint of inactive experts. Static post-training quantization reduces storage costs but cannot adapt to shifting activation patterns, causing accuracy loss under aggressive compression. So we present DynaExq, a runtime system that treats expert precision as a first-class, dynamically managed resource. DynaExq combines (1) a hotness-aware precision controller that continuously aligns expert bit-widths with long-term activation statistics, (2) a fully asynchronous precision-switching pipeline that overlaps promotion and demotion with MoE computation, and (3) a fragmentation-free memory pooling mechanism that supports hybrid-precision experts with deterministic allocation. Together, these components enable stable, non-blocking precision transitions under strict HBM budgets. Across Qwen3-30B and Qwen3-80B MoE models and six representative benchmarks, DynaExq deploys large LLMs on single RTX 5090 and A6000 GPUs and improves accuracy by up to 4.03 points over static low-precision baselines. The results show that adaptive, workload-aware quantization is an effective strategy for memory-constrained MoE serving.
Selective KV-Cache Sharing to Mitigate Timing Side-Channels in LLM Inference
Aug 11, 2025Global KV-cache sharing has emerged as a key optimization for accelerating large language model (LLM) inference. However, it exposes a new class of timing side-channel attacks, enabling adversaries to infer sensitive user inputs via shared cache entries. Existing defenses, such as per-user isolation, eliminate leakage but degrade performance by up to 38.9% in time-to-first-token (TTFT), making them impractical for high-throughput deployment. To address this gap, we introduce SafeKV (Secure and Flexible KV Cache Sharing), a privacy-aware KV-cache management framework that selectively shares non-sensitive entries while confining sensitive content to private caches. SafeKV comprises three components: (i) a hybrid, multi-tier detection pipeline that integrates rule-based pattern matching, a general-purpose privacy detector, and context-aware validation; (ii) a unified radix-tree index that manages public and private entries across heterogeneous memory tiers (HBM, DRAM, SSD); and (iii) entropy-based access monitoring to detect and mitigate residual information leakage. Our evaluation shows that SafeKV mitigates 94% - 97% of timing-based side-channel attacks. Compared to per-user isolation method, SafeKV improves TTFT by up to 40.58% and throughput by up to 2.66X across diverse LLMs and workloads. SafeKV reduces cache-induced TTFT overhead from 50.41% to 11.74% on Qwen3-235B. By combining fine-grained privacy control with high cache reuse efficiency, SafeKV reclaims the performance advantages of global sharing while providing robust runtime privacy guarantees for LLM inference.
Towards Zero-Shot Annotation of the Built Environment with Vision-Language Models (Vision Paper)
Aug 01, 2024Equitable urban transportation applications require high-fidelity digital representations of the built environment: not just streets and sidewalks, but bike lanes, marked and unmarked crossings, curb ramps and cuts, obstructions, traffic signals, signage, street markings, potholes, and more. Direct inspections and manual annotations are prohibitively expensive at scale. Conventional machine learning methods require substantial annotated training data for adequate performance. In this paper, we consider vision language models as a mechanism for annotating diverse urban features from satellite images, reducing the dependence on human annotation to produce large training sets. While these models have achieved impressive results in describing common objects in images captured from a human perspective, their training sets are less likely to include strong signals for esoteric features in the built environment, and their performance in these settings is therefore unclear. We demonstrate proof-of-concept combining a state-of-the-art vision language model and variants of a prompting strategy that asks the model to consider segmented elements independently of the original image. Experiments on two urban features -- stop lines and raised tables -- show that while direct zero-shot prompting correctly annotates nearly zero images, the pre-segmentation strategies can annotate images with near 40% intersection-over-union accuracy. We describe how these results inform a new research agenda in automatic annotation of the built environment to improve equity, accessibility, and safety at broad scale and in diverse environments.
DiffStega: Towards Universal Training-Free Coverless Image Steganography with Diffusion Models
Jul 15, 2024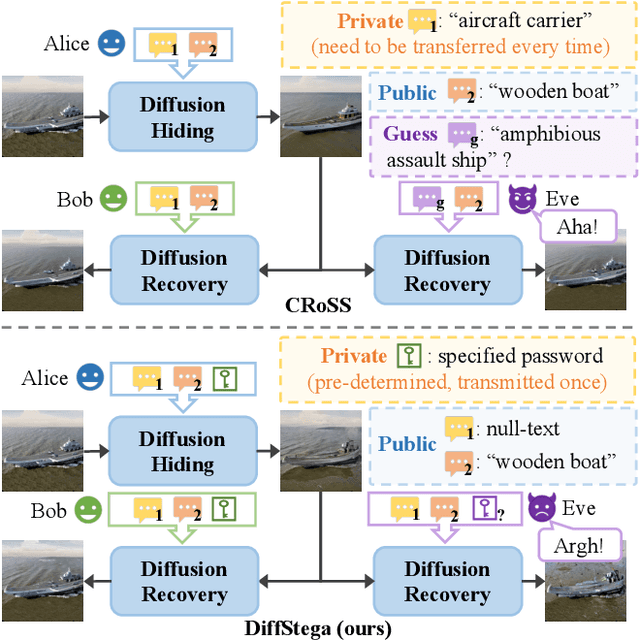


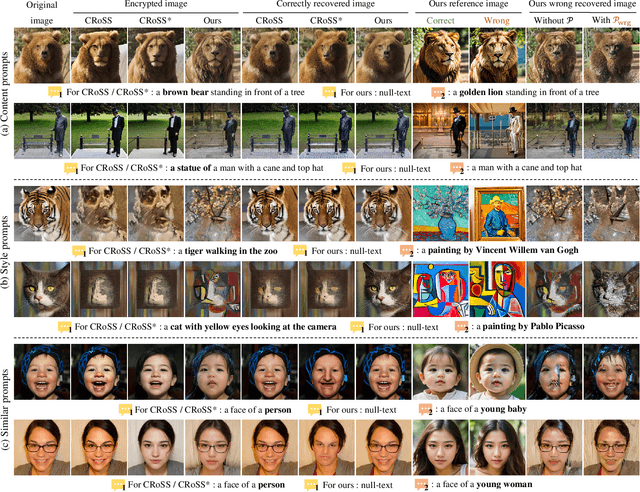
Traditional image steganography focuses on concealing one image within another, aiming to avoid steganalysis by unauthorized entities. Coverless image steganography (CIS) enhances imperceptibility by not using any cover image. Recent works have utilized text prompts as keys in CIS through diffusion models. However, this approach faces three challenges: invalidated when private prompt is guessed, crafting public prompts for semantic diversity, and the risk of prompt leakage during frequent transmission. To address these issues, we propose DiffStega, an innovative training-free diffusion-based CIS strategy for universal application. DiffStega uses a password-dependent reference image as an image prompt alongside the text, ensuring that only authorized parties can retrieve the hidden information. Furthermore, we develop Noise Flip technique to further secure the steganography against unauthorized decryption. To comprehensively assess our method across general CIS tasks, we create a dataset comprising various image steganography instances. Experiments indicate substantial improvements in our method over existing ones, particularly in aspects of versatility, password sensitivity, and recovery quality. Codes are available at \url{https://github.com/evtricks/DiffStega}.
Laboratory-Scale AI: Open-Weight Models are Competitive with ChatGPT Even in Low-Resource Settings
May 27, 2024



The rapid proliferation of generative AI has raised questions about the competitiveness of lower-parameter, locally tunable, open-weight models relative to high-parameter, API-guarded, closed-weight models in terms of performance, domain adaptation, cost, and generalization. Centering under-resourced yet risk-intolerant settings in government, research, and healthcare, we see for-profit closed-weight models as incompatible with requirements for transparency, privacy, adaptability, and standards of evidence. Yet the performance penalty in using open-weight models, especially in low-data and low-resource settings, is unclear. We assess the feasibility of using smaller, open-weight models to replace GPT-4-Turbo in zero-shot, few-shot, and fine-tuned regimes, assuming access to only a single, low-cost GPU. We assess value-sensitive issues around bias, privacy, and abstention on three additional tasks relevant to those topics. We find that with relatively low effort, very low absolute monetary cost, and relatively little data for fine-tuning, small open-weight models can achieve competitive performance in domain-adapted tasks without sacrificing generality. We then run experiments considering practical issues in bias, privacy, and hallucination risk, finding that open models offer several benefits over closed models. We intend this work as a case study in understanding the opportunity cost of reproducibility and transparency over for-profit state-of-the-art zero shot performance, finding this cost to be marginal under realistic settings.
KEN: Kernel Extensions using Natural Language
Dec 09, 2023The ability to modify and extend an operating system is an important feature for improving a system's security, reliability, and performance. The extended Berkeley Packet Filters (eBPF) ecosystem has emerged as the standard mechanism for extending the Linux kernel and has recently been ported to Windows. eBPF programs inject new logic into the kernel that the system will execute before or after existing logic. While the eBPF ecosystem provides a flexible mechanism for kernel extension, it is difficult for developers to write eBPF programs today. An eBPF developer must have deep knowledge of the internals of the operating system to determine where to place logic and cope with programming limitations on the control flow and data accesses of their eBPF program enforced by the eBPF verifier. This paper presents KEN, an alternative framework that alleviates the difficulty of writing an eBPF program by allowing Kernel Extensions to be written in Natural language. KEN uses recent advances in large language models (LLMs) to synthesize an eBPF program given a user's English language prompt. To ensure that LLM's output is semantically equivalent to the user's prompt, KEN employs a combination of LLM-empowered program comprehension, symbolic execution, and a series of feedback loops. KEN's key novelty is the combination of these techniques. In particular, the system uses symbolic execution in a novel structure that allows it to combine the results of program synthesis and program comprehension and build on the recent success that LLMs have shown for each of these tasks individually. To evaluate KEN, we developed a new corpus of natural language prompts for eBPF programs. We show that KEN produces correct eBPF programs on 80% which is an improvement of a factor of 2.67 compared to an LLM-empowered program synthesis baseline.
Contrastive Language-Vision AI Models Pretrained on Web-Scraped Multimodal Data Exhibit Sexual Objectification Bias
Dec 21, 2022



Nine language-vision AI models trained on web scrapes with the Contrastive Language-Image Pretraining (CLIP) objective are evaluated for evidence of a bias studied by psychologists: the sexual objectification of girls and women, which occurs when a person's human characteristics are disregarded and the person is treated as a body or a collection of body parts. A first experiment uses standardized images of women from the Sexual OBjectification and EMotion Database, and finds that, commensurate with prior research in psychology, human characteristics are disassociated from images of objectified women: the model's recognition of emotional state is mediated by whether the subject is fully or partially clothed. Embedding association tests (EATs) return significant effect sizes for both anger (d >.8) and sadness (d >.5). A second experiment measures the effect in a representative application: an automatic image captioner (Antarctic Captions) includes words denoting emotion less than 50% as often for images of partially clothed women than for images of fully clothed women. A third experiment finds that images of female professionals (scientists, doctors, executives) are likely to be associated with sexual descriptions relative to images of male professionals. A fourth experiment shows that a prompt of "a [age] year old girl" generates sexualized images (as determined by an NSFW classifier) up to 73% of the time for VQGAN-CLIP (age 17), and up to 40% of the time for Stable Diffusion (ages 14 and 18); the corresponding rate for boys never surpasses 9%. The evidence indicates that language-vision AI models trained on automatically collected web scrapes learn biases of sexual objectification, which propagate to downstream applications.
FocusNetv2: Imbalanced Large and Small Organ Segmentation with Adversarial Shape Constraint for Head and Neck CT Images
Apr 05, 2021


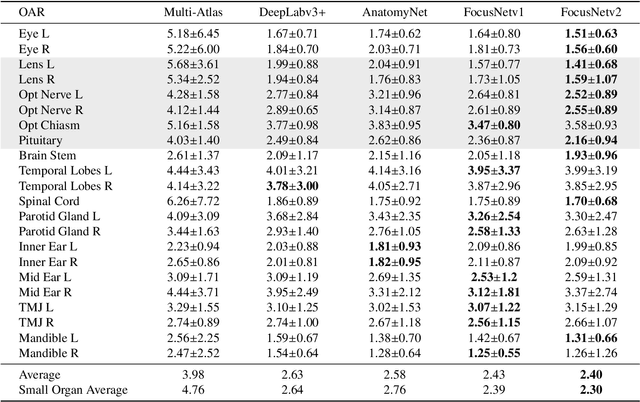
Radiotherapy is a treatment where radiation is used to eliminate cancer cells. The delineation of organs-at-risk (OARs) is a vital step in radiotherapy treatment planning to avoid damage to healthy organs. For nasopharyngeal cancer, more than 20 OARs are needed to be precisely segmented in advance. The challenge of this task lies in complex anatomical structure, low-contrast organ contours, and the extremely imbalanced size between large and small organs. Common segmentation methods that treat them equally would generally lead to inaccurate small-organ labeling. We propose a novel two-stage deep neural network, FocusNetv2, to solve this challenging problem by automatically locating, ROI-pooling, and segmenting small organs with specifically designed small-organ localization and segmentation sub-networks while maintaining the accuracy of large organ segmentation. In addition to our original FocusNet, we employ a novel adversarial shape constraint on small organs to ensure the consistency between estimated small-organ shapes and organ shape prior knowledge. Our proposed framework is extensively tested on both self-collected dataset of 1,164 CT scans and the MICCAI Head and Neck Auto Segmentation Challenge 2015 dataset, which shows superior performance compared with state-of-the-art head and neck OAR segmentation methods.