 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuousBench: Can Differentially Private Synthetic Text Improve Capabilities?
Jun 01, 2026Differentially private (DP) text synthesis promises to unlock sensitive corpora for model training, but it remains unclear whether DP synthetic data transmits genuinely new knowledge and capabilities present only in those corpora. This is because existing evaluations rely on tasks that are nearly solvable without training, so strong benchmark performance does not establish that DP synthesis can substitute original data access. Thus, we introduce ContinuousBench, a continuously and automatically-regenerated benchmark that measures capability gain from DP synthetic text. Each quarter, a new release pairs a never-before-seen training corpus with a derived QA set, constructed to be: (1) unsolvable sans-corpus; and (2) learnable under DP, as the tested knowledge is supported by hundreds of independent records. Researchers produce DP synthetic data from the training corpus and run our standardized training and evaluation harness on their synthetic data to measure gains. We instantiate two tracks: Geminon, a procedurally-generated dataset about fictional creatures; and News, a stream of newly crawled public news articles. Although standard benchmarks are nearly saturated, on ContinuousBench we find that non-private synthesis transfers substantial knowledge from the original corpus, while state-of-the-art DP synthesis methods generally fail to do so, even at $\varepsilon=100$.
Towards Provably Unbiased LLM Judges via Bias-Bounded Evaluation
Mar 05, 2026As AI models progress beyond simple chatbots into more complex workflows, we draw ever closer to the event horizon beyond which AI systems will be utilized in autonomous, self-maintaining feedback loops. Any autonomous AI system will depend on automated, verifiable rewards and feedback; in settings where ground truth is sparse or non-deterministic, one practical source of such rewards is an LLM-as-a-Judge. Although LLM judges continue to improve, the literature has yet to introduce systems capable of enforcing standards with strong guarantees, particularly when bias vectors are unknown or adversarially discovered. To remedy this issue, we propose average bias-boundedness (A-BB), an algorithmic framework which formally guarantees reductions of harm/impact as a result of any measurable bias in an LLM judge. Evaluating on Arena-Hard-Auto with four LLM judges, we achieve (tau=0.5, delta=0.01) bias-bounded guarantees while retaining 61-99% correlation with original rankings across formatting and schematic bias settings, with most judge-bias combinations exceeding 80%. The code to reproduce our findings is available at https://github.com/penfever/bias-bounded-evaluation.
Exactly Computing do-Shapley Values
Feb 06, 2026Structural Causal Models (SCM) are a powerful framework for describing complicated dynamics across the natural sciences. A particularly elegant way of interpreting SCMs is do-Shapley, a game-theoretic method of quantifying the average effect of $d$ variables across exponentially many interventions. Like Shapley values, computing do-Shapley values generally requires evaluating exponentially many terms. The foundation of our work is a reformulation of do-Shapley values in terms of the irreducible sets of the underlying SCM. Leveraging this insight, we can exactly compute do-Shapley values in time linear in the number of irreducible sets $r$, which itself can range from $d$ to $2^d$ depending on the graph structure of the SCM. Since $r$ is unknown a priori, we complement the exact algorithm with an estimator that, like general Shapley value estimators, can be run with any query budget. As the query budget approaches $r$, our estimators can produce more accurate estimates than prior methods by several orders of magnitude, and, when the budget reaches $r$, return the Shapley values up to machine precision. Beyond computational speed, we also reduce the identification burden: we prove that non-parametric identifiability of do-Shapley values requires only the identification of interventional effects for the $d$ singleton coalitions, rather than all classes.
Privately Fine-Tuned LLMs Preserve Temporal Dynamics in Tabular Data
Feb 02, 2026Research on differentially private synthetic tabular data has largely focused on independent and identically distributed rows where each record corresponds to a unique individual. This perspective neglects the temporal complexity in longitudinal datasets, such as electronic health records, where a user contributes an entire (sub) table of sequential events. While practitioners might attempt to model such data by flattening user histories into high-dimensional vectors for use with standard marginal-based mechanisms, we demonstrate that this strategy is insufficient. Flattening fails to preserve temporal coherence even when it maintains valid marginal distributions. We introduce PATH, a novel generative framework that treats the full table as the unit of synthesis and leverages the autoregressive capabilities of privately fine-tuned large language models. Extensive evaluations show that PATH effectively captures long-range dependencies that traditional methods miss. Empirically, our method reduces the distributional distance to real trajectories by over 60% and reduces state transition errors by nearly 50% compared to leading marginal mechanisms while achieving similar marginal fidelity.
Explanation Multiplicity in SHAP: Characterization and Assessment
Jan 19, 2026Post-hoc explanations are widely used to justify, contest, and audit automated decisions in high-stakes domains. SHAP, in particular, is often treated as a reliable account of which features drove an individual prediction. Yet SHAP explanations can vary substantially across repeated runs even when the input, task, and trained model are held fixed. We term this phenomenon explanation multiplicity: multiple internally valid but substantively different explanations for the same decision. We present a methodology to characterize multiplicity in feature-attribution explanations and to disentangle sources due to model training/selection from stochasticity intrinsic to the explanation pipeline. We further show that apparent stability depends on the metric: magnitude-based distances can remain near zero while rank-based measures reveal substantial churn in the identity and ordering of top features. To contextualize observed disagreement, we derive randomized baseline values under plausible null models. Across datasets, model classes, and confidence regimes, we find explanation multiplicity is pervasive and persists even for high-confidence predictions, highlighting the need for metrics and baselines that match the intended use of explanations.
Fragments to Facts: Partial-Information Fragment Inference from LLMs
May 20, 2025Large language models (LLMs) can leak sensitive training data through memorization and membership inference attacks. Prior work has primarily focused on strong adversarial assumptions, including attacker access to entire samples or long, ordered prefixes, leaving open the question of how vulnerable LLMs are when adversaries have only partial, unordered sample information. For example, if an attacker knows a patient has "hypertension," under what conditions can they query a model fine-tuned on patient data to learn the patient also has "osteoarthritis?" In this paper, we introduce a more general threat model under this weaker assumption and show that fine-tuned LLMs are susceptible to these fragment-specific extraction attacks. To systematically investigate these attacks, we propose two data-blind methods: (1) a likelihood ratio attack inspired by methods from membership inference, and (2) a novel approach, PRISM, which regularizes the ratio by leveraging an external prior. Using examples from both medical and legal settings, we show that both methods are competitive with a data-aware baseline classifier that assumes access to labeled in-distribution data, underscoring their robustness.
Do You Really Need Public Data? Surrogate Public Data for Differential Privacy on Tabular Data
Apr 19, 2025Differentially private (DP) machine learning often relies on the availability of public data for tasks like privacy-utility trade-off estimation, hyperparameter tuning, and pretraining. While public data assumptions may be reasonable in text and image domains, they are less likely to hold for tabular data due to tabular data heterogeneity across domains. We propose leveraging powerful priors to address this limitation; specifically, we synthesize realistic tabular data directly from schema-level specifications - such as variable names, types, and permissible ranges - without ever accessing sensitive records. To that end, this work introduces the notion of "surrogate" public data - datasets generated independently of sensitive data, which consume no privacy loss budget and are constructed solely from publicly available schema or metadata. Surrogate public data are intended to encode plausible statistical assumptions (informed by publicly available information) into a dataset with many downstream uses in private mechanisms. We automate the process of generating surrogate public data with large language models (LLMs); in particular, we propose two methods: direct record generation as CSV files, and automated structural causal model (SCM) construction for sampling records. Through extensive experiments, we demonstrate that surrogate public tabular data can effectively replace traditional public data when pretraining differentially private tabular classifiers. To a lesser extent, surrogate public data are also useful for hyperparameter tuning of DP synthetic data generators, and for estimating the privacy-utility tradeoff.
Differential Privacy Under Class Imbalance: Methods and Empirical Insights
Nov 08, 2024
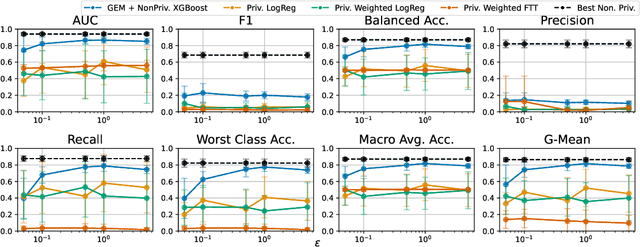
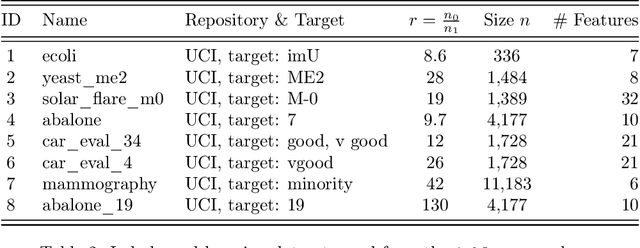
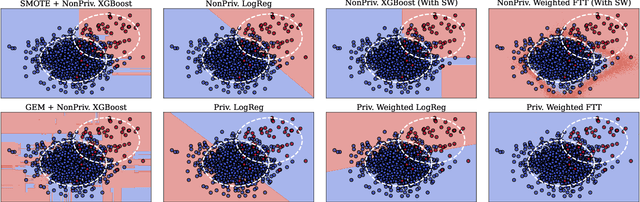
Imbalanced learning occurs in classification settings where the distribution of class-labels is highly skewed in the training data, such as when predicting rare diseases or in fraud detection. This class imbalance presents a significant algorithmic challenge, which can be further exacerbated when privacy-preserving techniques such as differential privacy are applied to protect sensitive training data. Our work formalizes these challenges and provides a number of algorithmic solutions. We consider DP variants of pre-processing methods that privately augment the original dataset to reduce the class imbalance; these include oversampling, SMOTE, and private synthetic data generation. We also consider DP variants of in-processing techniques, which adjust the learning algorithm to account for the imbalance; these include model bagging, class-weighted empirical risk minimization and class-weighted deep learning. For each method, we either adapt an existing imbalanced learning technique to the private setting or demonstrate its incompatibility with differential privacy. Finally, we empirically evaluate these privacy-preserving imbalanced learning methods under various data and distributional settings. We find that private synthetic data methods perform well as a data pre-processing step, while class-weighted ERMs are an alternative in higher-dimensional settings where private synthetic data suffers from the curse of dimensionality.
FairlyUncertain: A Comprehensive Benchmark of Uncertainty in Algorithmic Fairness
Oct 02, 2024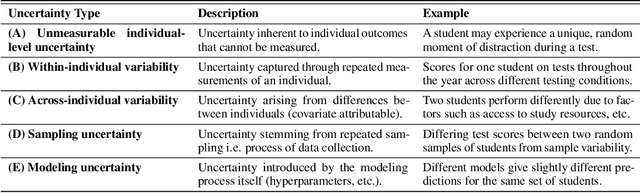
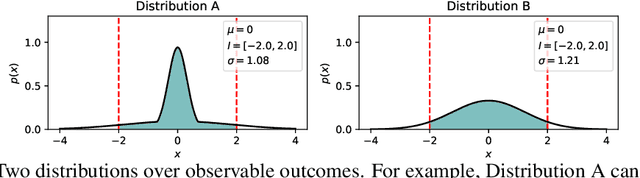
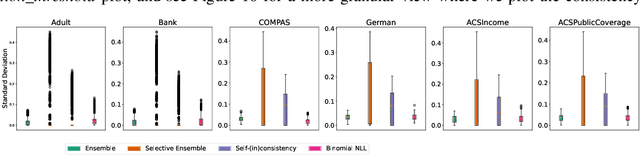

Fair predictive algorithms hinge on both equality and trust, yet inherent uncertainty in real-world data challenges our ability to make consistent, fair, and calibrated decisions. While fairly managing predictive error has been extensively explored, some recent work has begun to address the challenge of fairly accounting for irreducible prediction uncertainty. However, a clear taxonomy and well-specified objectives for integrating uncertainty into fairness remains undefined. We address this gap by introducing FairlyUncertain, an axiomatic benchmark for evaluating uncertainty estimates in fairness. Our benchmark posits that fair predictive uncertainty estimates should be consistent across learning pipelines and calibrated to observed randomness. Through extensive experiments on ten popular fairness datasets, our evaluation reveals: (1) A theoretically justified and simple method for estimating uncertainty in binary settings is more consistent and calibrated than prior work; (2) Abstaining from binary predictions, even with improved uncertainty estimates, reduces error but does not alleviate outcome imbalances between demographic groups; (3) Incorporating consistent and calibrated uncertainty estimates in regression tasks improves fairness without any explicit fairness interventions. Additionally, our benchmark package is designed to be extensible and open-source, to grow with the field. By providing a standardized framework for assessing the interplay between uncertainty and fairness, FairlyUncertain paves the way for more equitable and trustworthy machine learning practices.
Sharper Bounds for Chebyshev Moment Matching with Applications to Differential Privacy and Beyond
Aug 22, 2024We study the problem of approximately recovering a probability distribution given noisy measurements of its Chebyshev polynomial moments. We sharpen prior work, proving that accurate recovery in the Wasserstein distance is possible with more noise than previously known. As a main application, our result yields a simple "linear query" algorithm for constructing a differentially private synthetic data distribution with Wasserstein-1 error $\tilde{O}(1/n)$ based on a dataset of $n$ points in $[-1,1]$. This bound is optimal up to log factors and matches a recent breakthrough of Boedihardjo, Strohmer, and Vershynin [Probab. Theory. Rel., 2024], which uses a more complex "superregular random walk" method to beat an $O(1/\sqrt{n})$ accuracy barrier inherent to earlier approaches. We illustrate a second application of our new moment-based recovery bound in numerical linear algebra: by improving an approach of Braverman, Krishnan, and Musco [STOC 2022], our result yields a faster algorithm for estimating the spectral density of a symmetric matrix up to small error in the Wasserstein distance.