 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTOP: Structured On-Policy Pruning of Long-Form Reasoning in Low-Data Regimes
May 13, 2026Long chain-of-thought (Long CoT) reasoning improves performance on multi-step problems, but it also induces overthinking: models often generate low-yield reasoning that increases inference cost and latency. This inefficiency is especially problematic in low-data fine-tuning regimes, where real applications adapt reasoning models with limited supervision and cannot rely on large-scale teacher distillation or heavy test-time control. To address this, we propose STOP (Structured On-policy Pruning), an on-policy algorithm for analyzing and pruning long-form reasoning traces. STOP constructs self-distilled traces from the model. Then it maps each trace into a structured reasoning interface through node segmentation, taxonomy annotation, and reasoning-tree construction. On top of this interface, we introduce ECN (Earliest Correct Node), which retains the shortest prefix ending at the earliest node that both functions as an answering conclusion and yields the correct final answer, removing redundant post-solution reasoning while preserving semantic continuity. Experiments on DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-LLaMA-3-8B across GSM8K, Math 500, and AIME 2024 show that STOP reduces generated tokens by 19.4-42.4% while largely preserving accuracy in low-data fine-tuning. Beyond efficiency, our analyses show that STOP induces much smaller distributional shift than teacher-guided pruning, improves the structural efficiency of generated reasoning, and reallocates reasoning effort away from redundant verification and backtracking toward more productive exploration.
Towards Dynamic Dense Retrieval with Routing Strategy
Feb 26, 2026The \textit{de facto} paradigm for applying dense retrieval (DR) to new tasks involves fine-tuning a pre-trained model for a specific task. However, this paradigm has two significant limitations: (1) It is difficult adapt the DR to a new domain if the training dataset is limited. (2) Old DR models are simply replaced by newer models that are trained from scratch when the former are no longer up to date. Especially for scenarios where the model needs to be updated frequently, this paradigm is prohibitively expensive. To address these challenges, we propose a novel dense retrieval approach, termed \textit{dynamic dense retrieval} (DDR). DDR uses \textit{prefix tuning} as a \textit{module} specialized for a specific domain. These modules can then be compositional combined with a dynamic routing strategy, enabling highly flexible domain adaptation in the retrieval part. Extensive evaluation on six zero-shot downstream tasks demonstrates that this approach can surpass DR while utilizing only 2\% of the training parameters, paving the way to achieve more flexible dense retrieval in IR. We see it as a promising future direction for applying dense retrieval to various tasks.
Clarify or Answer: Reinforcement Learning for Agentic VQA with Context Under-specification
Jan 23, 2026Real-world visual question answering (VQA) is often context-dependent: an image-question pair may be under-specified, such that the correct answer depends on external information that is not observable in the image. In such cases, directly answering can lead to confident but incorrect predictions. We propose CoA(Clarify-or-Answer), an ask-or-answer agent that separately models the decision to ask or answer, and what to ask if needed. CoA first determines whether clarification is necessary; if so, it asks a single focused question and then incorporates the response to produce the final answer. We introduce CONTEXTCLARIFY with a set of ambiguous VQA questions and the contrast set that is non-ambiguous. We further introduce GRPO-CR (Clarification Reasoning), a reinforcement learning approach that optimizes clarification question generation with multiple reward signals encouraging well-formed, focused, non-trivial questions that resolve ambiguity. Across three VLLMs and three datasets, CoA achieves consistent improvements at both the module and system levels, improving end-to-end VQA accuracy by an average of +15.3 points (83%) over prompting-based baselines
Tensorized Clustered LoRA Merging for Multi-Task Interference
Aug 06, 2025Despite the success of the monolithic dense paradigm of large language models (LLMs), the LoRA adapters offer an efficient solution by fine-tuning small task-specific modules and merging them with the base model. However, in multi-task settings, merging LoRA adapters trained on heterogeneous sources frequently causes \textit{task interference}, degrading downstream performance. To address this, we propose a tensorized clustered LoRA (TC-LoRA) library targeting to address the task interference at the \textit{text-level} and \textit{parameter-level}. At the \textit{text-level}, we cluster the training samples in the embedding space to capture input-format similarities, then train a specialized LoRA adapter for each cluster. At the \textit{parameter-level}, we introduce a joint Canonical Polyadic (CP) decomposition that disentangles task-specific and shared factors across LoRA adapters. This joint factorization preserves essential knowledge while reducing cross-task interference. Extensive experiments on out-of-domain zero-shot and skill-composition tasks-including reasoning, question answering, and coding. Compared to strong SVD-based baselines, TC-LoRA achieves +1.4\% accuracy on Phi-3 and +2.3\% on Mistral-7B (+2.3\%), demonstrating the effectiveness of TC-LoRA in LLM adaptation.
MMMG: a Comprehensive and Reliable Evaluation Suite for Multitask Multimodal Generation
May 23, 2025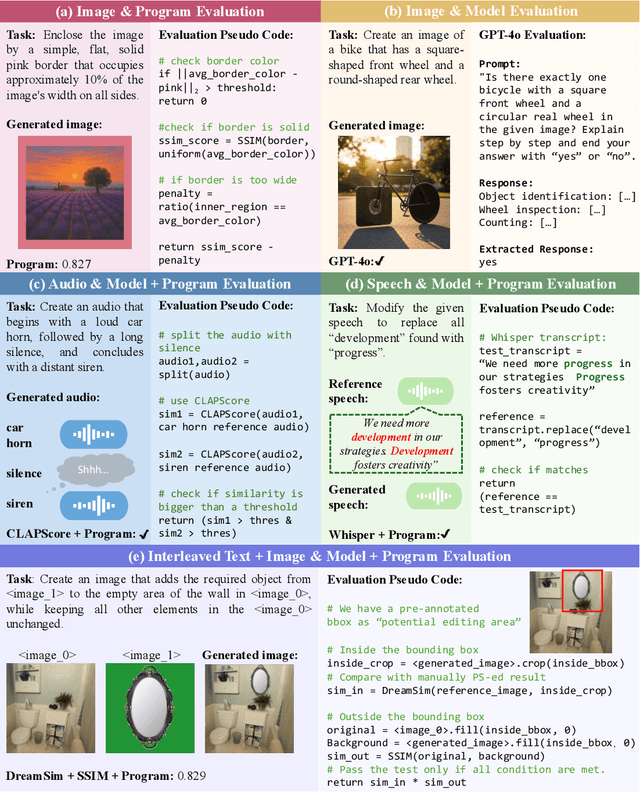
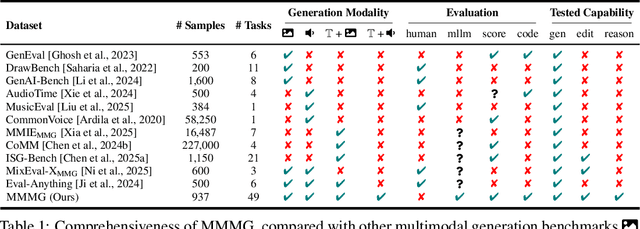
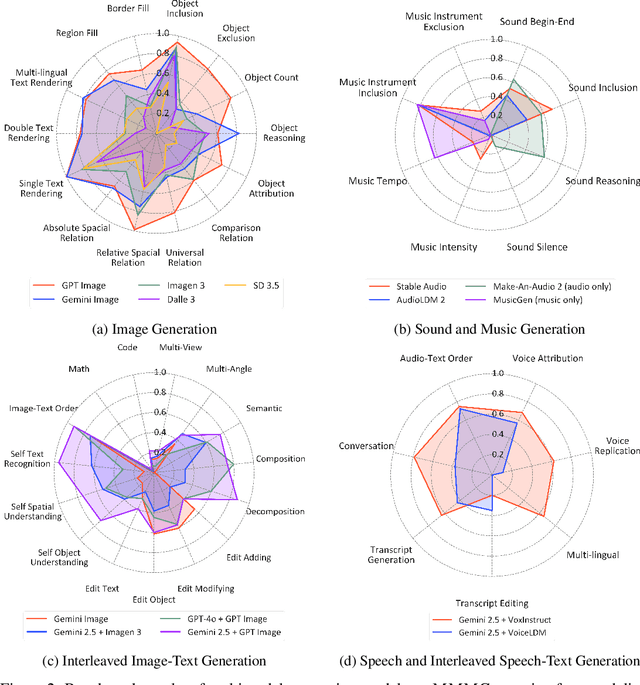
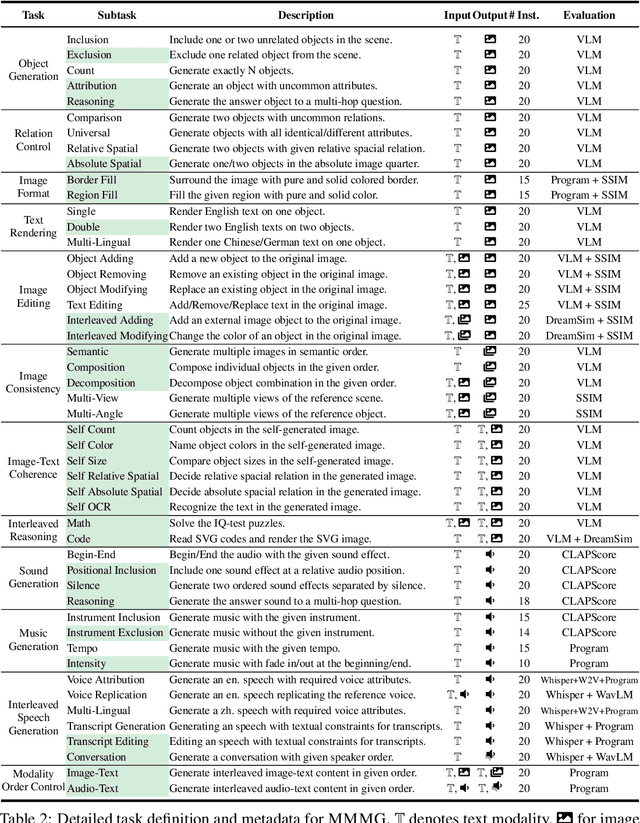
Automatically evaluating multimodal generation presents a significant challenge, as automated metrics often struggle to align reliably with human evaluation, especially for complex tasks that involve multiple modalities. To address this, we present MMMG, a comprehensive and human-aligned benchmark for multimodal generation across 4 modality combinations (image, audio, interleaved text and image, interleaved text and audio), with a focus on tasks that present significant challenges for generation models, while still enabling reliable automatic evaluation through a combination of models and programs. MMMG encompasses 49 tasks (including 29 newly developed ones), each with a carefully designed evaluation pipeline, and 937 instructions to systematically assess reasoning, controllability, and other key capabilities of multimodal generation models. Extensive validation demonstrates that MMMG is highly aligned with human evaluation, achieving an average agreement of 94.3%. Benchmarking results on 24 multimodal generation models reveal that even though the state-of-the-art model, GPT Image, achieves 78.3% accuracy for image generation, it falls short on multimodal reasoning and interleaved generation. Furthermore, results suggest considerable headroom for improvement in audio generation, highlighting an important direction for future research.
Know Your Limits: A Survey of Abstention in Large Language Models
Aug 08, 2024



Abstention, the refusal of large language models (LLMs) to provide an answer, is increasingly recognized for its potential to mitigate hallucinations and enhance safety in LLM systems. In this survey, we introduce a framework to examine abstention from three perspectives: the query, the model, and human values. We organize the literature on abstention methods, benchmarks, and evaluation metrics using this framework, and discuss merits and limitations of prior work. We further identify and motivate areas for future work, centered around whether abstention can be achieved as a meta-capability that transcends specific tasks or domains, while still providing opportunities to optimize abstention abilities based on context.
AutoScale: Automatic Prediction of Compute-optimal Data Composition for Training LLMs
Jul 29, 2024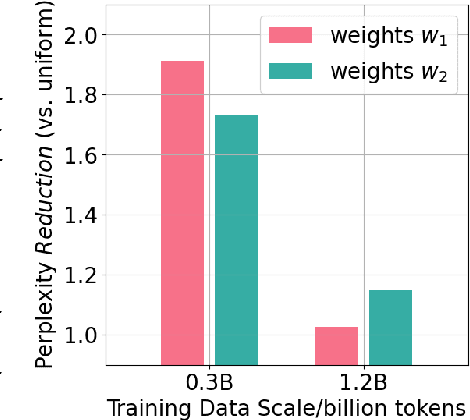
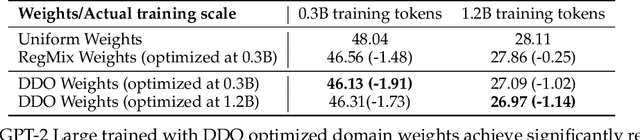
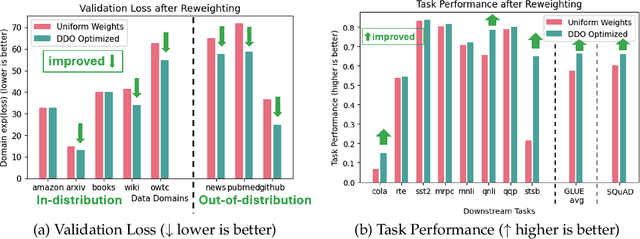
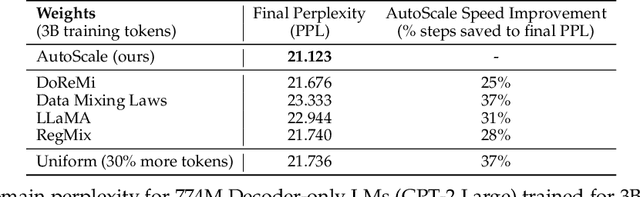
To ensure performance on a diverse set of downstream tasks, LLMs are pretrained via data mixtures over different domains. In this work, we demonstrate that the optimal data composition for a fixed compute budget varies depending on the scale of the training data, suggesting that the common practice of empirically determining an optimal composition using small-scale experiments will not yield the optimal data mixtures when scaling up to the final model. To address this challenge, we propose *AutoScale*, an automated tool that finds a compute-optimal data composition for training at any desired target scale. AutoScale first determines the optimal composition at a small scale using a novel bilevel optimization framework, Direct Data Optimization (*DDO*), and then fits a predictor to estimate the optimal composition at larger scales. The predictor's design is inspired by our theoretical analysis of scaling laws related to data composition, which could be of independent interest. In empirical studies with pre-training 774M Decoder-only LMs (GPT-2 Large) on RedPajama dataset, AutoScale decreases validation perplexity at least 25% faster than any baseline with up to 38% speed up compared to without reweighting, achieving the best overall performance across downstream tasks. On pre-training Encoder-only LMs (BERT) with masked language modeling, DDO is shown to decrease loss on all domains while visibly improving average task performance on GLUE benchmark by 8.7% and on large-scale QA dataset (SQuAD) by 5.9% compared with without reweighting. AutoScale speeds up training by up to 28%. Our codes are open-sourced.
The Art of Refusal: A Survey of Abstention in Large Language Models
Jul 25, 2024Abstention, the refusal of large language models (LLMs) to provide an answer, is increasingly recognized for its potential to mitigate hallucinations and enhance safety in building LLM systems. In this survey, we introduce a framework to examine abstention behavior from three perspectives: the query, the model, and human values. We review the literature on abstention methods (categorized based on the development stages of LLMs), benchmarks, and evaluation metrics, and discuss the merits and limitations of prior work. We further identify and motivate areas for future research, such as encouraging the study of abstention as a meta-capability across tasks and customizing abstention abilities based on context. In doing so, we aim to broaden the scope and impact of abstention methodologies in AI systems.
Laboratory-Scale AI: Open-Weight Models are Competitive with ChatGPT Even in Low-Resource Settings
May 27, 2024



The rapid proliferation of generative AI has raised questions about the competitiveness of lower-parameter, locally tunable, open-weight models relative to high-parameter, API-guarded, closed-weight models in terms of performance, domain adaptation, cost, and generalization. Centering under-resourced yet risk-intolerant settings in government, research, and healthcare, we see for-profit closed-weight models as incompatible with requirements for transparency, privacy, adaptability, and standards of evidence. Yet the performance penalty in using open-weight models, especially in low-data and low-resource settings, is unclear. We assess the feasibility of using smaller, open-weight models to replace GPT-4-Turbo in zero-shot, few-shot, and fine-tuned regimes, assuming access to only a single, low-cost GPU. We assess value-sensitive issues around bias, privacy, and abstention on three additional tasks relevant to those topics. We find that with relatively low effort, very low absolute monetary cost, and relatively little data for fine-tuning, small open-weight models can achieve competitive performance in domain-adapted tasks without sacrificing generality. We then run experiments considering practical issues in bias, privacy, and hallucination risk, finding that open models offer several benefits over closed models. We intend this work as a case study in understanding the opportunity cost of reproducibility and transparency over for-profit state-of-the-art zero shot performance, finding this cost to be marginal under realistic settings.
Characterizing LLM Abstention Behavior in Science QA with Context Perturbations
Apr 18, 2024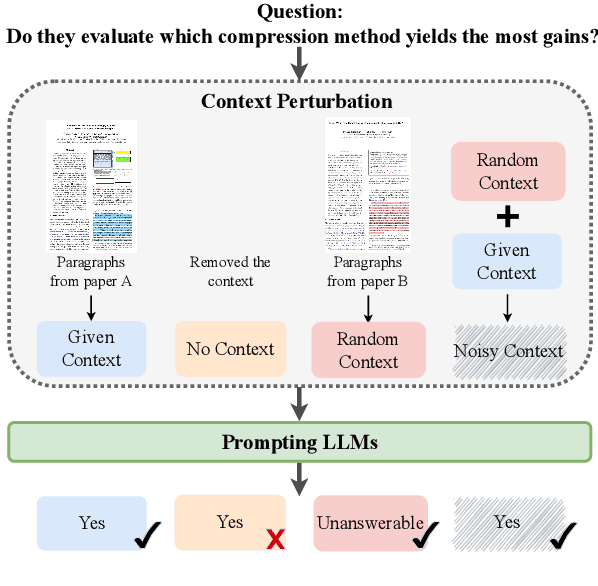



The correct model response in the face of uncertainty is to abstain from answering a question so as not to mislead the user. In this work, we study the ability of LLMs to abstain from answering context-dependent science questions when provided insufficient or incorrect context. We probe model sensitivity in several settings: removing gold context, replacing gold context with irrelevant context, and providing additional context beyond what is given. In experiments on four QA datasets with four LLMs, we show that performance varies greatly across models, across the type of context provided, and also by question type; in particular, many LLMs seem unable to abstain from answering boolean questions using standard QA prompts. Our analysis also highlights the unexpected impact of abstention performance on QA task accuracy. Counter-intuitively, in some settings, replacing gold context with irrelevant context or adding irrelevant context to gold context can improve abstention performance in a way that results in improvements in task performance. Our results imply that changes are needed in QA dataset design and evaluation to more effectively assess the correctness and downstream impacts of model abstention.