 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMG: Avatar Motion Guided Video Generation
Sep 02, 2024



Human video generation task has gained significant attention with the advancement of deep generative models. Generating realistic videos with human movements is challenging in nature, due to the intricacies of human body topology and sensitivity to visual artifacts. The extensively studied 2D media generation methods take advantage of massive human media datasets, but struggle with 3D-aware control; whereas 3D avatar-based approaches, while offering more freedom in control, lack photorealism and cannot be harmonized seamlessly with background scene. We propose AMG, a method that combines the 2D photorealism and 3D controllability by conditioning video diffusion models on controlled rendering of 3D avatars. We additionally introduce a novel data processing pipeline that reconstructs and renders human avatar movements from dynamic camera videos. AMG is the first method that enables multi-person diffusion video generation with precise control over camera positions, human motions, and background style. We also demonstrate through extensive evaluation that it outperforms existing human video generation methods conditioned on pose sequences or driving videos in terms of realism and adaptability.
Towards Open Domain Text-Driven Synthesis of Multi-Person Motions
May 28, 2024This work aims to generate natural and diverse group motions of multiple humans from textual descriptions. While single-person text-to-motion generation is extensively studied, it remains challenging to synthesize motions for more than one or two subjects from in-the-wild prompts, mainly due to the lack of available datasets. In this work, we curate human pose and motion datasets by estimating pose information from large-scale image and video datasets. Our models use a transformer-based diffusion framework that accommodates multiple datasets with any number of subjects or frames. Experiments explore both generation of multi-person static poses and generation of multi-person motion sequences. To our knowledge, our method is the first to generate multi-subject motion sequences with high diversity and fidelity from a large variety of textual prompts.
OmniMotionGPT: Animal Motion Generation with Limited Data
Nov 30, 2023



Our paper aims to generate diverse and realistic animal motion sequences from textual descriptions, without a large-scale animal text-motion dataset. While the task of text-driven human motion synthesis is already extensively studied and benchmarked, it remains challenging to transfer this success to other skeleton structures with limited data. In this work, we design a model architecture that imitates Generative Pretraining Transformer (GPT), utilizing prior knowledge learned from human data to the animal domain. We jointly train motion autoencoders for both animal and human motions and at the same time optimize through the similarity scores among human motion encoding, animal motion encoding, and text CLIP embedding. Presenting the first solution to this problem, we are able to generate animal motions with high diversity and fidelity, quantitatively and qualitatively outperforming the results of training human motion generation baselines on animal data. Additionally, we introduce AnimalML3D, the first text-animal motion dataset with 1240 animation sequences spanning 36 different animal identities. We hope this dataset would mediate the data scarcity problem in text-driven animal motion generation, providing a new playground for the research community.
Animating Street View
Oct 12, 2023We present a system that automatically brings street view imagery to life by populating it with naturally behaving, animated pedestrians and vehicles. Our approach is to remove existing people and vehicles from the input image, insert moving objects with proper scale, angle, motion, and appearance, plan paths and traffic behavior, as well as render the scene with plausible occlusion and shadowing effects. The system achieves these by reconstructing the still image street scene, simulating crowd behavior, and rendering with consistent lighting, visibility, occlusions, and shadows. We demonstrate results on a diverse range of street scenes including regular still images and panoramas.
StyleSDF: High-Resolution 3D-Consistent Image and Geometry Generation
Dec 21, 2021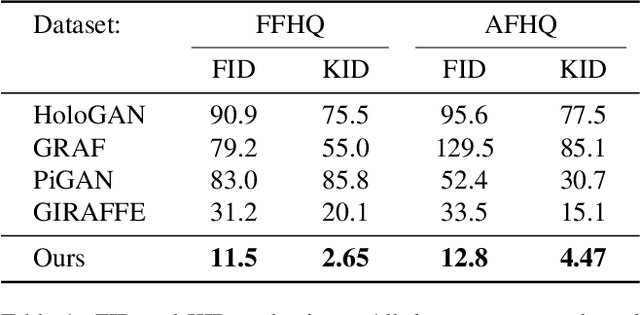
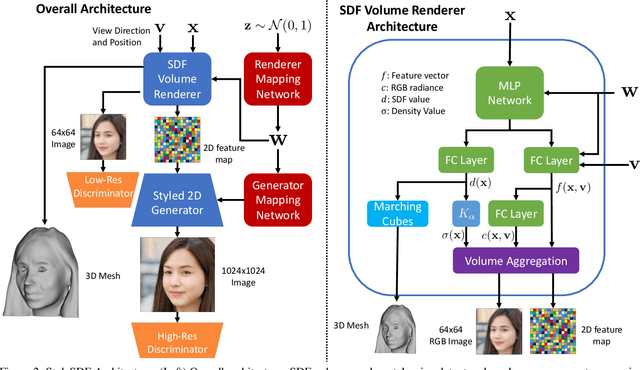


We introduce a high resolution, 3D-consistent image and shape generation technique which we call StyleSDF. Our method is trained on single-view RGB data only, and stands on the shoulders of StyleGAN2 for image generation, while solving two main challenges in 3D-aware GANs: 1) high-resolution, view-consistent generation of the RGB images, and 2) detailed 3D shape. We achieve this by merging a SDF-based 3D representation with a style-based 2D generator. Our 3D implicit network renders low-resolution feature maps, from which the style-based network generates view-consistent, 1024x1024 images. Notably, our SDF-based 3D modeling defines detailed 3D surfaces, leading to consistent volume rendering. Our method shows higher quality results compared to state of the art in terms of visual and geometric quality.