 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenstory++: A Large-scale Dataset and Benchmark for Instance-aware Open-domain Visual Storytelling
Aug 07, 2024



Recent image generation models excel at creating high-quality images from brief captions. However, they fail to maintain consistency of multiple instances across images when encountering lengthy contexts. This inconsistency is largely due to in existing training datasets the absence of granular instance feature labeling in existing training datasets. To tackle these issues, we introduce Openstory++, a large-scale dataset combining additional instance-level annotations with both images and text. Furthermore, we develop a training methodology that emphasizes entity-centric image-text generation, ensuring that the models learn to effectively interweave visual and textual information. Specifically, Openstory++ streamlines the process of keyframe extraction from open-domain videos, employing vision-language models to generate captions that are then polished by a large language model for narrative continuity. It surpasses previous datasets by offering a more expansive open-domain resource, which incorporates automated captioning, high-resolution imagery tailored for instance count, and extensive frame sequences for temporal consistency. Additionally, we present Cohere-Bench, a pioneering benchmark framework for evaluating the image generation tasks when long multimodal context is provided, including the ability to keep the background, style, instances in the given context coherent. Compared to existing benchmarks, our work fills critical gaps in multi-modal generation, propelling the development of models that can adeptly generate and interpret complex narratives in open-domain environments. Experiments conducted within Cohere-Bench confirm the superiority of Openstory++ in nurturing high-quality visual storytelling models, enhancing their ability to address open-domain generation tasks. More details can be found at https://openstorypp.github.io/
UltrAvatar: A Realistic Animatable 3D Avatar Diffusion Model with Authenticity Guided Textures
Jan 20, 2024Recent advances in 3D avatar generation have gained significant attentions. These breakthroughs aim to produce more realistic animatable avatars, narrowing the gap between virtual and real-world experiences. Most of existing works employ Score Distillation Sampling (SDS) loss, combined with a differentiable renderer and text condition, to guide a diffusion model in generating 3D avatars. However, SDS often generates oversmoothed results with few facial details, thereby lacking the diversity compared with ancestral sampling. On the other hand, other works generate 3D avatar from a single image, where the challenges of unwanted lighting effects, perspective views, and inferior image quality make them difficult to reliably reconstruct the 3D face meshes with the aligned complete textures. In this paper, we propose a novel 3D avatar generation approach termed UltrAvatar with enhanced fidelity of geometry, and superior quality of physically based rendering (PBR) textures without unwanted lighting. To this end, the proposed approach presents a diffuse color extraction model and an authenticity guided texture diffusion model. The former removes the unwanted lighting effects to reveal true diffuse colors so that the generated avatars can be rendered under various lighting conditions. The latter follows two gradient-based guidances for generating PBR textures to render diverse face-identity features and details better aligning with 3D mesh geometry. We demonstrate the effectiveness and robustness of the proposed method, outperforming the state-of-the-art methods by a large margin in the experiments.
OmniMotionGPT: Animal Motion Generation with Limited Data
Nov 30, 2023



Our paper aims to generate diverse and realistic animal motion sequences from textual descriptions, without a large-scale animal text-motion dataset. While the task of text-driven human motion synthesis is already extensively studied and benchmarked, it remains challenging to transfer this success to other skeleton structures with limited data. In this work, we design a model architecture that imitates Generative Pretraining Transformer (GPT), utilizing prior knowledge learned from human data to the animal domain. We jointly train motion autoencoders for both animal and human motions and at the same time optimize through the similarity scores among human motion encoding, animal motion encoding, and text CLIP embedding. Presenting the first solution to this problem, we are able to generate animal motions with high diversity and fidelity, quantitatively and qualitatively outperforming the results of training human motion generation baselines on animal data. Additionally, we introduce AnimalML3D, the first text-animal motion dataset with 1240 animation sequences spanning 36 different animal identities. We hope this dataset would mediate the data scarcity problem in text-driven animal motion generation, providing a new playground for the research community.
AdPE: Adversarial Positional Embeddings for Pretraining Vision Transformers via MAE+
Mar 14, 2023



Unsupervised learning of vision transformers seeks to pretrain an encoder via pretext tasks without labels. Among them is the Masked Image Modeling (MIM) aligned with pretraining of language transformers by predicting masked patches as a pretext task. A criterion in unsupervised pretraining is the pretext task needs to be sufficiently hard to prevent the transformer encoder from learning trivial low-level features not generalizable well to downstream tasks. For this purpose, we propose an Adversarial Positional Embedding (AdPE) approach -- It distorts the local visual structures by perturbing the position encodings so that the learned transformer cannot simply use the locally correlated patches to predict the missing ones. We hypothesize that it forces the transformer encoder to learn more discriminative features in a global context with stronger generalizability to downstream tasks. We will consider both absolute and relative positional encodings, where adversarial positions can be imposed both in the embedding mode and the coordinate mode. We will also present a new MAE+ baseline that brings the performance of the MIM pretraining to a new level with the AdPE. The experiments demonstrate that our approach can improve the fine-tuning accuracy of MAE by $0.8\%$ and $0.4\%$ over 1600 epochs of pretraining ViT-B and ViT-L on Imagenet1K. For the transfer learning task, it outperforms the MAE with the ViT-B backbone by $2.6\%$ in mIoU on ADE20K, and by $3.2\%$ in AP$^{bbox}$ and $1.6\%$ in AP$^{mask}$ on COCO, respectively. These results are obtained with the AdPE being a pure MIM approach that does not use any extra models or external datasets for pretraining. The code is available at https://github.com/maple-research-lab/AdPE.
Dual-Flattening Transformers through Decomposed Row and Column Queries for Semantic Segmentation
Jan 22, 2022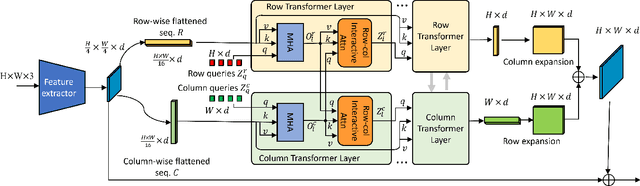

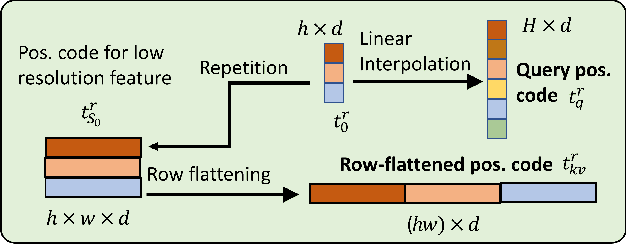
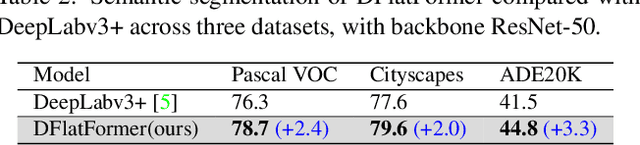
It is critical to obtain high resolution features with long range dependency for dense prediction tasks such as semantic segmentation. To generate high-resolution output of size $H\times W$ from a low-resolution feature map of size $h\times w$ ($hw\ll HW$), a naive dense transformer incurs an intractable complexity of $\mathcal{O}(hwHW)$, limiting its application on high-resolution dense prediction. We propose a Dual-Flattening Transformer (DFlatFormer) to enable high-resolution output by reducing complexity to $\mathcal{O}(hw(H+W))$ that is multiple orders of magnitude smaller than the naive dense transformer. Decomposed queries are presented to retrieve row and column attentions tractably through separate transformers, and their outputs are combined to form a dense feature map at high resolution. To this end, the input sequence fed from an encoder is row-wise and column-wise flattened to align with decomposed queries by preserving their row and column structures, respectively. Row and column transformers also interact with each other to capture their mutual attentions with the spatial crossings between rows and columns. We also propose to perform attentions through efficient grouping and pooling to further reduce the model complexity. Extensive experiments on ADE20K and Cityscapes datasets demonstrate the superiority of the proposed dual-flattening transformer architecture with higher mIoUs.