 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLOT: Sample-specific Language Model Optimization at Test-time
May 18, 2025We propose SLOT (Sample-specific Language Model Optimization at Test-time), a novel and parameter-efficient test-time inference approach that enhances a language model's ability to more accurately respond to individual prompts. Existing Large Language Models (LLMs) often struggle with complex instructions, leading to poor performances on those not well represented among general samples. To address this, SLOT conducts few optimization steps at test-time to update a light-weight sample-specific parameter vector. It is added to the final hidden layer before the output head, and enables efficient adaptation by caching the last layer features during per-sample optimization. By minimizing the cross-entropy loss on the input prompt only, SLOT helps the model better aligned with and follow each given instruction. In experiments, we demonstrate that our method outperforms the compared models across multiple benchmarks and LLMs. For example, Qwen2.5-7B with SLOT achieves an accuracy gain of 8.6% on GSM8K from 57.54% to 66.19%, while DeepSeek-R1-Distill-Llama-70B with SLOT achieves a SOTA accuracy of 68.69% on GPQA among 70B-level models. Our code is available at https://github.com/maple-research-lab/SLOT.
Cross Paradigm Representation and Alignment Transformer for Image Deraining
Apr 23, 2025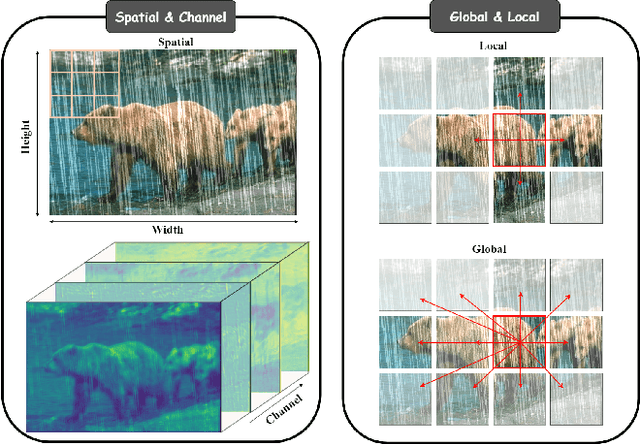
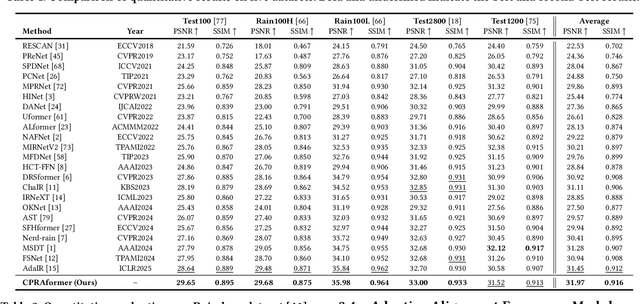
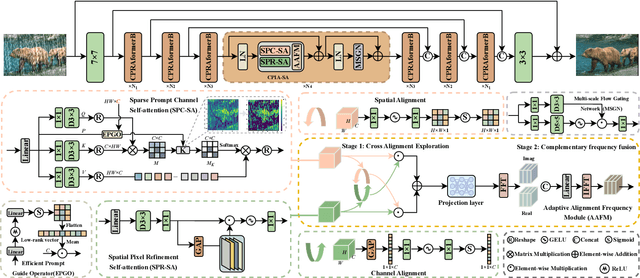
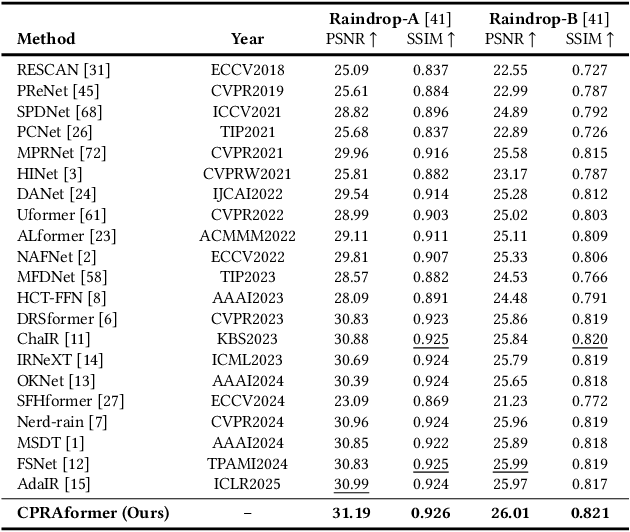
Transformer-based networks have achieved strong performance in low-level vision tasks like image deraining by utilizing spatial or channel-wise self-attention. However, irregular rain patterns and complex geometric overlaps challenge single-paradigm architectures, necessitating a unified framework to integrate complementary global-local and spatial-channel representations. To address this, we propose a novel Cross Paradigm Representation and Alignment Transformer (CPRAformer). Its core idea is the hierarchical representation and alignment, leveraging the strengths of both paradigms (spatial-channel and global-local) to aid image reconstruction. It bridges the gap within and between paradigms, aligning and coordinating them to enable deep interaction and fusion of features. Specifically, we use two types of self-attention in the Transformer blocks: sparse prompt channel self-attention (SPC-SA) and spatial pixel refinement self-attention (SPR-SA). SPC-SA enhances global channel dependencies through dynamic sparsity, while SPR-SA focuses on spatial rain distribution and fine-grained texture recovery. To address the feature misalignment and knowledge differences between them, we introduce the Adaptive Alignment Frequency Module (AAFM), which aligns and interacts with features in a two-stage progressive manner, enabling adaptive guidance and complementarity. This reduces the information gap within and between paradigms. Through this unified cross-paradigm dynamic interaction framework, we achieve the extraction of the most valuable interactive fusion information from the two paradigms. Extensive experiments demonstrate that our model achieves state-of-the-art performance on eight benchmark datasets and further validates CPRAformer's robustness in other image restoration tasks and downstream applications.
Learning Dual-Domain Multi-Scale Representations for Single Image Deraining
Mar 15, 2025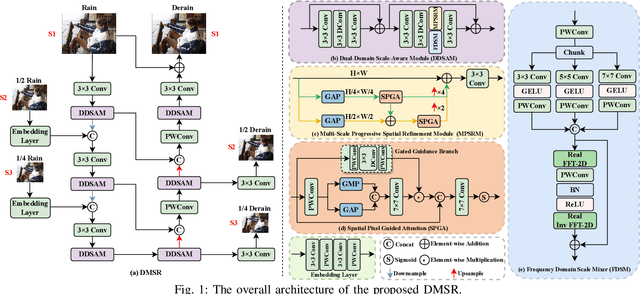
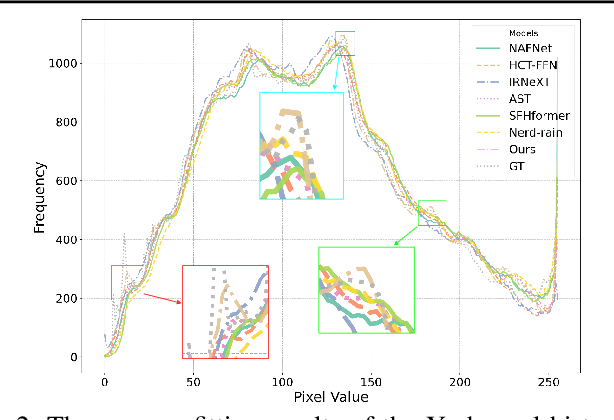

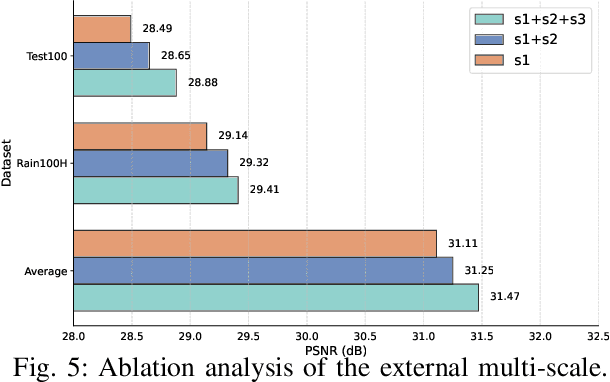
Existing image deraining methods typically rely on single-input, single-output, and single-scale architectures, which overlook the joint multi-scale information between external and internal features. Furthermore, single-domain representations are often too restrictive, limiting their ability to handle the complexities of real-world rain scenarios. To address these challenges, we propose a novel Dual-Domain Multi-Scale Representation Network (DMSR). The key idea is to exploit joint multi-scale representations from both external and internal domains in parallel while leveraging the strengths of both spatial and frequency domains to capture more comprehensive properties. Specifically, our method consists of two main components: the Multi-Scale Progressive Spatial Refinement Module (MPSRM) and the Frequency Domain Scale Mixer (FDSM). The MPSRM enables the interaction and coupling of multi-scale expert information within the internal domain using a hierarchical modulation and fusion strategy. The FDSM extracts multi-scale local information in the spatial domain, while also modeling global dependencies in the frequency domain. Extensive experiments show that our model achieves state-of-the-art performance across six benchmark datasets.
DiffSpeaker: Speech-Driven 3D Facial Animation with Diffusion Transformer
Feb 08, 2024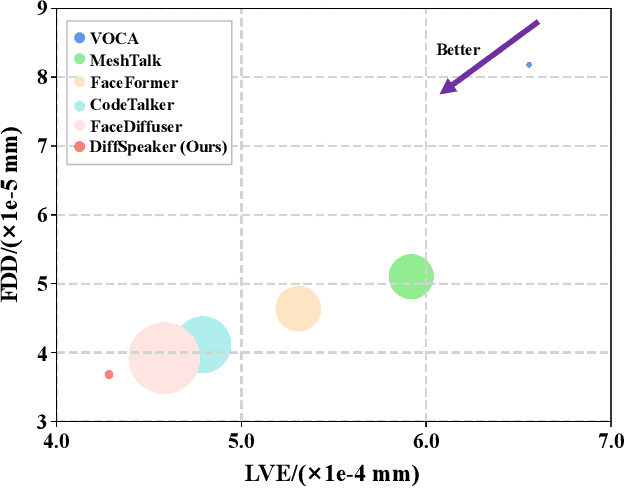

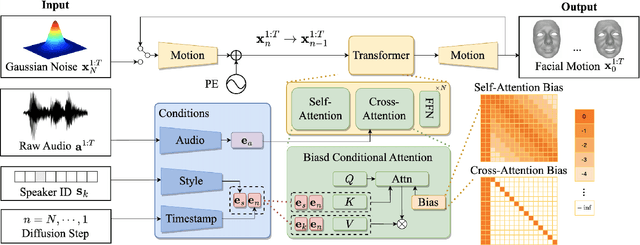

Speech-driven 3D facial animation is important for many multimedia applications. Recent work has shown promise in using either Diffusion models or Transformer architectures for this task. However, their mere aggregation does not lead to improved performance. We suspect this is due to a shortage of paired audio-4D data, which is crucial for the Transformer to effectively perform as a denoiser within the Diffusion framework. To tackle this issue, we present DiffSpeaker, a Transformer-based network equipped with novel biased conditional attention modules. These modules serve as substitutes for the traditional self/cross-attention in standard Transformers, incorporating thoughtfully designed biases that steer the attention mechanisms to concentrate on both the relevant task-specific and diffusion-related conditions. We also explore the trade-off between accurate lip synchronization and non-verbal facial expressions within the Diffusion paradigm. Experiments show our model not only achieves state-of-the-art performance on existing benchmarks, but also fast inference speed owing to its ability to generate facial motions in parallel.
UltrAvatar: A Realistic Animatable 3D Avatar Diffusion Model with Authenticity Guided Textures
Jan 20, 2024Recent advances in 3D avatar generation have gained significant attentions. These breakthroughs aim to produce more realistic animatable avatars, narrowing the gap between virtual and real-world experiences. Most of existing works employ Score Distillation Sampling (SDS) loss, combined with a differentiable renderer and text condition, to guide a diffusion model in generating 3D avatars. However, SDS often generates oversmoothed results with few facial details, thereby lacking the diversity compared with ancestral sampling. On the other hand, other works generate 3D avatar from a single image, where the challenges of unwanted lighting effects, perspective views, and inferior image quality make them difficult to reliably reconstruct the 3D face meshes with the aligned complete textures. In this paper, we propose a novel 3D avatar generation approach termed UltrAvatar with enhanced fidelity of geometry, and superior quality of physically based rendering (PBR) textures without unwanted lighting. To this end, the proposed approach presents a diffuse color extraction model and an authenticity guided texture diffusion model. The former removes the unwanted lighting effects to reveal true diffuse colors so that the generated avatars can be rendered under various lighting conditions. The latter follows two gradient-based guidances for generating PBR textures to render diverse face-identity features and details better aligning with 3D mesh geometry. We demonstrate the effectiveness and robustness of the proposed method, outperforming the state-of-the-art methods by a large margin in the experiments.
Lightweight high-resolution Subject Matting in the Real World
Dec 12, 2023



Existing saliency object detection (SOD) methods struggle to satisfy fast inference and accurate results simultaneously in high resolution scenes. They are limited by the quality of public datasets and efficient network modules for high-resolution images. To alleviate these issues, we propose to construct a saliency object matting dataset HRSOM and a lightweight network PSUNet. Considering efficient inference of mobile depolyment framework, we design a symmetric pixel shuffle module and a lightweight module TRSU. Compared to 13 SOD methods, the proposed PSUNet has the best objective performance on the high-resolution benchmark dataset. Evaluation results of objective assessment are superior compared to U$^2$Net that has 10 times of parameter amount of our network. On Snapdragon 8 Gen 2 Mobile Platform, inference a single 640$\times$640 image only takes 113ms. And on the subjective assessment, evaluation results are better than the industry benchmark IOS16 (Lift subject from background).
LatentAvatar: Learning Latent Expression Code for Expressive Neural Head Avatar
May 03, 2023Existing approaches to animatable NeRF-based head avatars are either built upon face templates or use the expression coefficients of templates as the driving signal. Despite the promising progress, their performances are heavily bound by the expression power and the tracking accuracy of the templates. In this work, we present LatentAvatar, an expressive neural head avatar driven by latent expression codes. Such latent expression codes are learned in an end-to-end and self-supervised manner without templates, enabling our method to get rid of expression and tracking issues. To achieve this, we leverage a latent head NeRF to learn the person-specific latent expression codes from a monocular portrait video, and further design a Y-shaped network to learn the shared latent expression codes of different subjects for cross-identity reenactment. By optimizing the photometric reconstruction objectives in NeRF, the latent expression codes are learned to be 3D-aware while faithfully capturing the high-frequency detailed expressions. Moreover, by learning a mapping between the latent expression code learned in shared and person-specific settings, LatentAvatar is able to perform expressive reenactment between different subjects. Experimental results show that our LatentAvatar is able to capture challenging expressions and the subtle movement of teeth and even eyeballs, which outperforms previous state-of-the-art solutions in both quantitative and qualitative comparisons. Project page: https://www.liuyebin.com/latentavatar.
OTAvatar: One-shot Talking Face Avatar with Controllable Tri-plane Rendering
Mar 26, 2023Controllability, generalizability and efficiency are the major objectives of constructing face avatars represented by neural implicit field. However, existing methods have not managed to accommodate the three requirements simultaneously. They either focus on static portraits, restricting the representation ability to a specific subject, or suffer from substantial computational cost, limiting their flexibility. In this paper, we propose One-shot Talking face Avatar (OTAvatar), which constructs face avatars by a generalized controllable tri-plane rendering solution so that each personalized avatar can be constructed from only one portrait as the reference. Specifically, OTAvatar first inverts a portrait image to a motion-free identity code. Second, the identity code and a motion code are utilized to modulate an efficient CNN to generate a tri-plane formulated volume, which encodes the subject in the desired motion. Finally, volume rendering is employed to generate an image in any view. The core of our solution is a novel decoupling-by-inverting strategy that disentangles identity and motion in the latent code via optimization-based inversion. Benefiting from the efficient tri-plane representation, we achieve controllable rendering of generalized face avatar at $35$ FPS on A100. Experiments show promising performance of cross-identity reenactment on subjects out of the training set and better 3D consistency.
Causal Attention for Vision-Language Tasks
Mar 05, 2021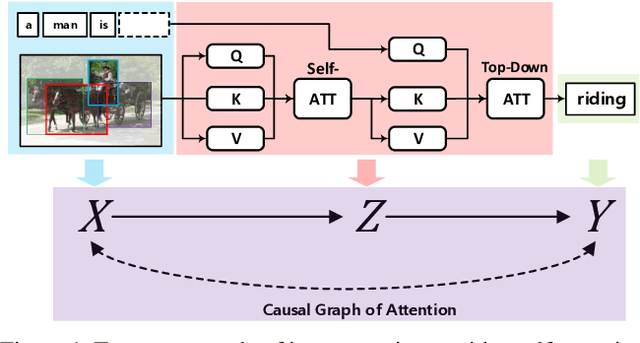
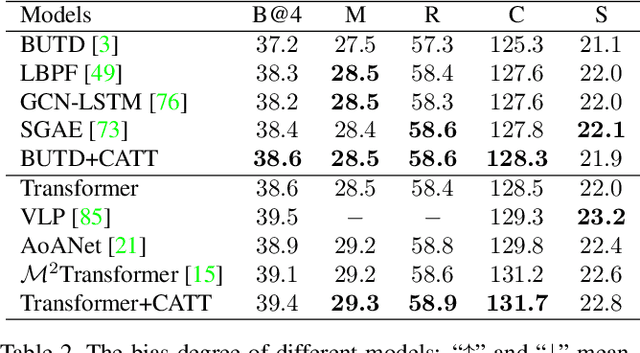

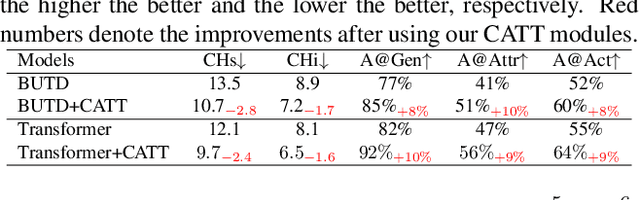
We present a novel attention mechanism: Causal Attention (CATT), to remove the ever-elusive confounding effect in existing attention-based vision-language models. This effect causes harmful bias that misleads the attention module to focus on the spurious correlations in training data, damaging the model generalization. As the confounder is unobserved in general, we use the front-door adjustment to realize the causal intervention, which does not require any knowledge on the confounder. Specifically, CATT is implemented as a combination of 1) In-Sample Attention (IS-ATT) and 2) Cross-Sample Attention (CS-ATT), where the latter forcibly brings other samples into every IS-ATT, mimicking the causal intervention. CATT abides by the Q-K-V convention and hence can replace any attention module such as top-down attention and self-attention in Transformers. CATT improves various popular attention-based vision-language models by considerable margins. In particular, we show that CATT has great potential in large-scale pre-training, e.g., it can promote the lighter LXMERT~\cite{tan2019lxmert}, which uses fewer data and less computational power, comparable to the heavier UNITER~\cite{chen2020uniter}. Code is published in \url{https://github.com/yangxuntu/catt}.
FLAT: Few-Shot Learning via Autoencoding Transformation Regularizers
Dec 29, 2019
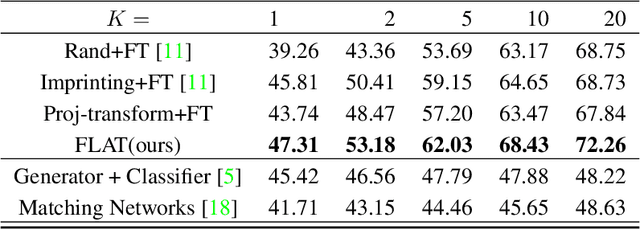
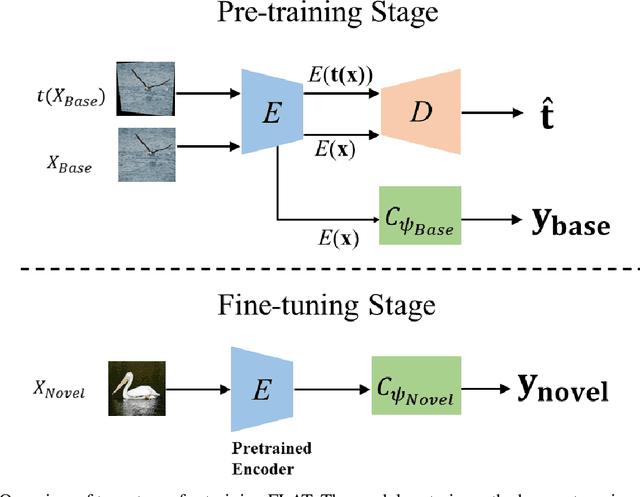
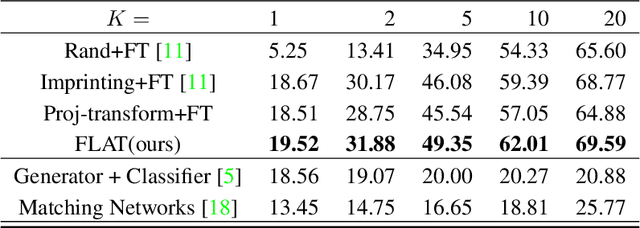
One of the most significant challenges facing a few-shot learning task is the generalizability of the (meta-)model from the base to the novel categories. Most of existing few-shot learning models attempt to address this challenge by either learning the meta-knowledge from multiple simulated tasks on the base categories, or resorting to data augmentation by applying various transformations to training examples. However, the supervised nature of model training in these approaches limits their ability of exploring variations across different categories, thus restricting their cross-category generalizability in modeling novel concepts. To this end, we present a novel regularization mechanism by learning the change of feature representations induced by a distribution of transformations without using the labels of data examples. We expect this regularizer could expand the semantic space of base categories to cover that of novel categories through the transformation of feature representations. It could minimize the risk of overfitting into base categories by inspecting the transformation-augmented variations at the encoded feature level. This results in the proposed FLAT (Few-shot Learning via Autoencoding Transformations) approach by autoencoding the applied transformations. The experiment results show the superior performances to the current state-of-the-art methods in literature.