 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltrAvatar: A Realistic Animatable 3D Avatar Diffusion Model with Authenticity Guided Textures
Jan 20, 2024Recent advances in 3D avatar generation have gained significant attentions. These breakthroughs aim to produce more realistic animatable avatars, narrowing the gap between virtual and real-world experiences. Most of existing works employ Score Distillation Sampling (SDS) loss, combined with a differentiable renderer and text condition, to guide a diffusion model in generating 3D avatars. However, SDS often generates oversmoothed results with few facial details, thereby lacking the diversity compared with ancestral sampling. On the other hand, other works generate 3D avatar from a single image, where the challenges of unwanted lighting effects, perspective views, and inferior image quality make them difficult to reliably reconstruct the 3D face meshes with the aligned complete textures. In this paper, we propose a novel 3D avatar generation approach termed UltrAvatar with enhanced fidelity of geometry, and superior quality of physically based rendering (PBR) textures without unwanted lighting. To this end, the proposed approach presents a diffuse color extraction model and an authenticity guided texture diffusion model. The former removes the unwanted lighting effects to reveal true diffuse colors so that the generated avatars can be rendered under various lighting conditions. The latter follows two gradient-based guidances for generating PBR textures to render diverse face-identity features and details better aligning with 3D mesh geometry. We demonstrate the effectiveness and robustness of the proposed method, outperforming the state-of-the-art methods by a large margin in the experiments.
Factorized Tensor Networks for Multi-Task and Multi-Domain Learning
Oct 09, 2023



Multi-task and multi-domain learning methods seek to learn multiple tasks/domains, jointly or one after another, using a single unified network. The key challenge and opportunity is to exploit shared information across tasks and domains to improve the efficiency of the unified network. The efficiency can be in terms of accuracy, storage cost, computation, or sample complexity. In this paper, we propose a factorized tensor network (FTN) that can achieve accuracy comparable to independent single-task/domain networks with a small number of additional parameters. FTN uses a frozen backbone network from a source model and incrementally adds task/domain-specific low-rank tensor factors to the shared frozen network. This approach can adapt to a large number of target domains and tasks without catastrophic forgetting. Furthermore, FTN requires a significantly smaller number of task-specific parameters compared to existing methods. We performed experiments on widely used multi-domain and multi-task datasets. We show the experiments on convolutional-based architecture with different backbones and on transformer-based architecture. We observed that FTN achieves similar accuracy as single-task/domain methods while using only a fraction of additional parameters per task.
Compressive Sensing with Tensorized Autoencoder
Mar 10, 2023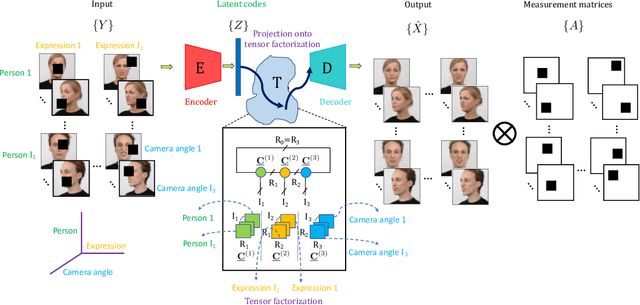
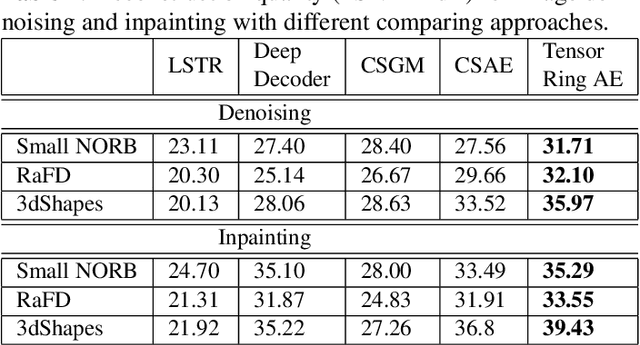
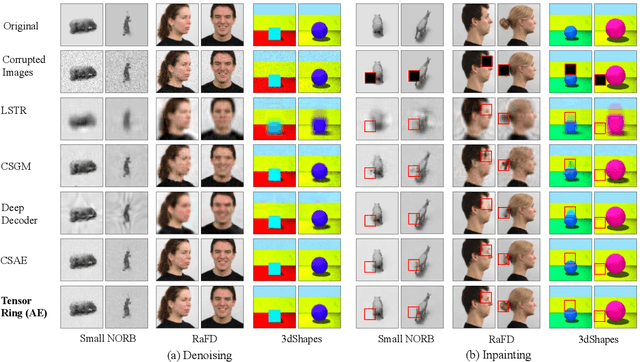
Deep networks can be trained to map images into a low-dimensional latent space. In many cases, different images in a collection are articulated versions of one another; for example, same object with different lighting, background, or pose. Furthermore, in many cases, parts of images can be corrupted by noise or missing entries. In this paper, our goal is to recover images without access to the ground-truth (clean) images using the articulations as structural prior of the data. Such recovery problems fall under the domain of compressive sensing. We propose to learn autoencoder with tensor ring factorization on the the embedding space to impose structural constraints on the data. In particular, we use a tensor ring structure in the bottleneck layer of the autoencoder that utilizes the soft labels of the structured dataset. We empirically demonstrate the effectiveness of the proposed approach for inpainting and denoising applications. The resulting method achieves better reconstruction quality compared to other generative prior-based self-supervised recovery approaches for compressive sensing.
Incremental Task Learning with Incremental Rank Updates
Jul 19, 2022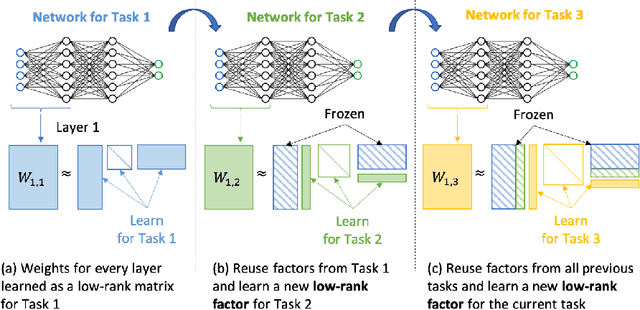
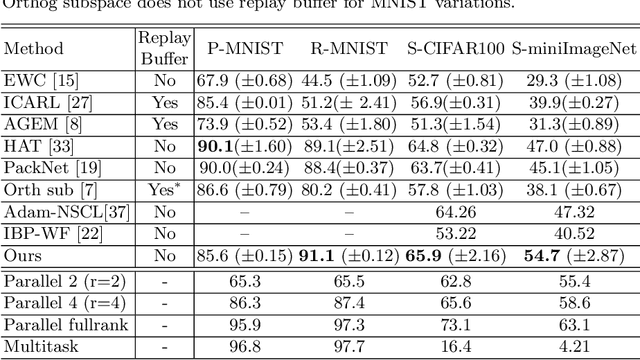
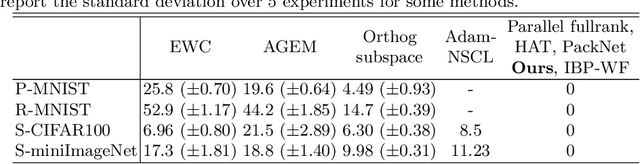
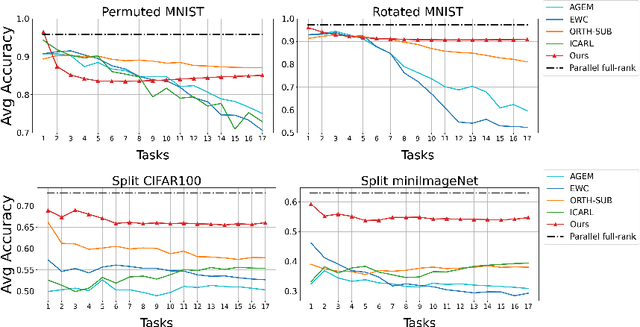
Incremental Task learning (ITL) is a category of continual learning that seeks to train a single network for multiple tasks (one after another), where training data for each task is only available during the training of that task. Neural networks tend to forget older tasks when they are trained for the newer tasks; this property is often known as catastrophic forgetting. To address this issue, ITL methods use episodic memory, parameter regularization, masking and pruning, or extensible network structures. In this paper, we propose a new incremental task learning framework based on low-rank factorization. In particular, we represent the network weights for each layer as a linear combination of several rank-1 matrices. To update the network for a new task, we learn a rank-1 (or low-rank) matrix and add that to the weights of every layer. We also introduce an additional selector vector that assigns different weights to the low-rank matrices learned for the previous tasks. We show that our approach performs better than the current state-of-the-art methods in terms of accuracy and forgetting. Our method also offers better memory efficiency compared to episodic memory- and mask-based approaches. Our code will be available at https://github.com/CSIPlab/task-increment-rank-update.git
* Code will be available at https://github.com/CSIPlab/task-increment-rank-update.git
Provably Convergent Algorithms for Solving Inverse Problems Using Generative Models
May 13, 2021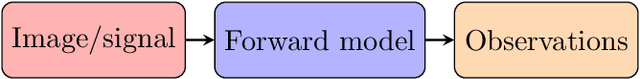
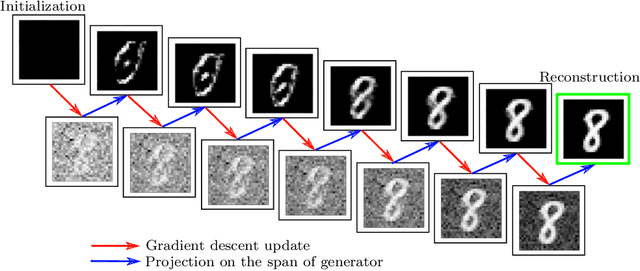


The traditional approach of hand-crafting priors (such as sparsity) for solving inverse problems is slowly being replaced by the use of richer learned priors (such as those modeled by deep generative networks). In this work, we study the algorithmic aspects of such a learning-based approach from a theoretical perspective. For certain generative network architectures, we establish a simple non-convex algorithmic approach that (a) theoretically enjoys linear convergence guarantees for certain linear and nonlinear inverse problems, and (b) empirically improves upon conventional techniques such as back-propagation. We support our claims with the experimental results for solving various inverse problems. We also propose an extension of our approach that can handle model mismatch (i.e., situations where the generative network prior is not exactly applicable). Together, our contributions serve as building blocks towards a principled use of generative models in inverse problems with more complete algorithmic understanding.
Solving Phase Retrieval with a Learned Reference
Jul 29, 2020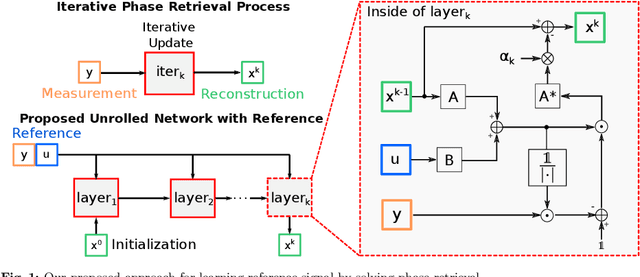

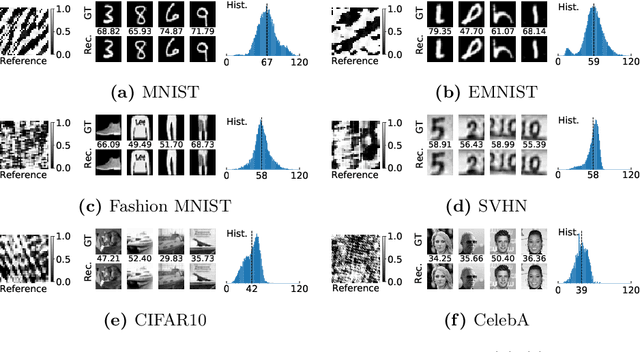
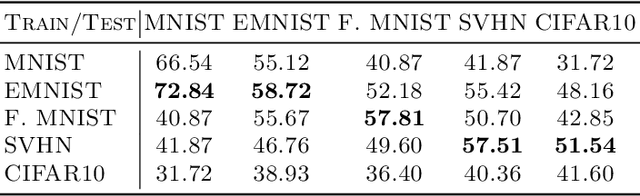
Fourier phase retrieval is a classical problem that deals with the recovery of an image from the amplitude measurements of its Fourier coefficients. Conventional methods solve this problem via iterative (alternating) minimization by leveraging some prior knowledge about the structure of the unknown image. The inherent ambiguities about shift and flip in the Fourier measurements make this problem especially difficult; and most of the existing methods use several random restarts with different permutations. In this paper, we assume that a known (learned) reference is added to the signal before capturing the Fourier amplitude measurements. Our method is inspired by the principle of adding a reference signal in holography. To recover the signal, we implement an iterative phase retrieval method as an unrolled network. Then we use back propagation to learn the reference that provides us the best reconstruction for a fixed number of phase retrieval iterations. We performed a number of simulations on a variety of datasets under different conditions and found that our proposed method for phase retrieval via unrolled network and learned reference provides near-perfect recovery at fixed (small) computational cost. We compared our method with standard Fourier phase retrieval methods and observed significant performance enhancement using the learned reference.
Non-Adversarial Video Synthesis with Learned Priors
Apr 17, 2020
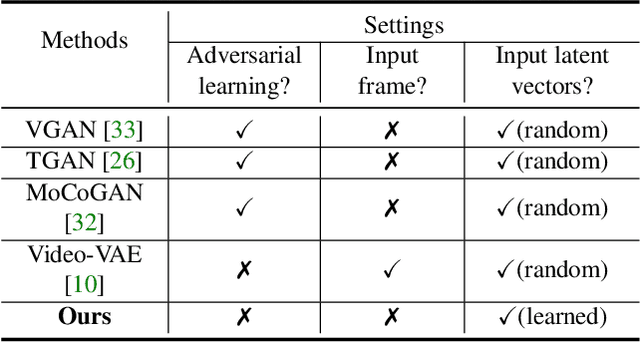
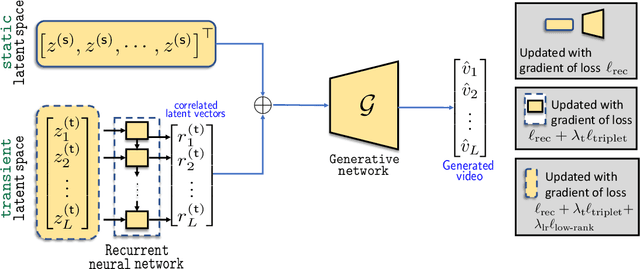

Most of the existing works in video synthesis focus on generating videos using adversarial learning. Despite their success, these methods often require input reference frame or fail to generate diverse videos from the given data distribution, with little to no uniformity in the quality of videos that can be generated. Different from these methods, we focus on the problem of generating videos from latent noise vectors, without any reference input frames. To this end, we develop a novel approach that jointly optimizes the input latent space, the weights of a recurrent neural network and a generator through non-adversarial learning. Optimizing for the input latent space along with the network weights allows us to generate videos in a controlled environment, i.e., we can faithfully generate all videos the model has seen during the learning process as well as new unseen videos. Extensive experiments on three challenging and diverse datasets well demonstrate that our approach generates superior quality videos compared to the existing state-of-the-art methods.
Alternating Phase Projected Gradient Descent with Generative Priors for Solving Compressive Phase Retrieval
Mar 07, 2019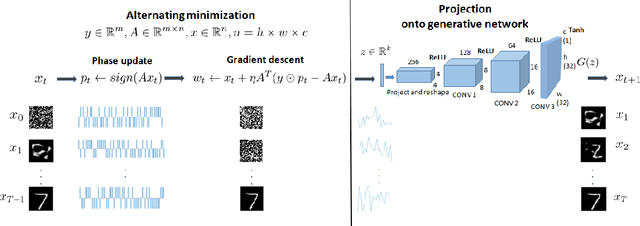
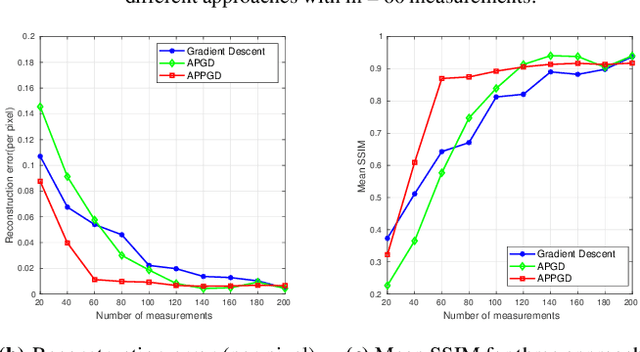
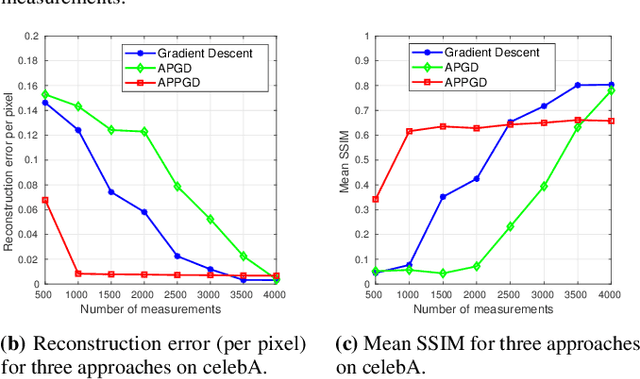
The classical problem of phase retrieval arises in various signal acquisition systems. Due to the ill-posed nature of the problem, the solution requires assumptions on the structure of the signal. In the last several years, sparsity and support-based priors have been leveraged successfully to solve this problem. In this work, we propose replacing the sparsity/support priors with generative priors and propose two algorithms to solve the phase retrieval problem. Our proposed algorithms combine the ideas from AltMin approach for non-convex sparse phase retrieval and projected gradient descent approach for solving linear inverse problems using generative priors. We empirically show that the performance of our method with projected gradient descent is superior to the existing approach for solving phase retrieval under generative priors. We support our method with an analysis of sample complexity with Gaussian measurements.
Generative Models for Low-Rank Video Representation and Reconstruction
Feb 25, 2019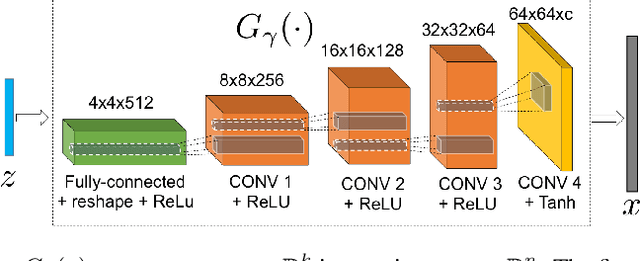
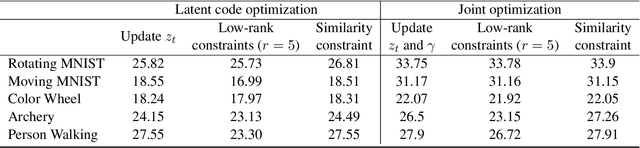
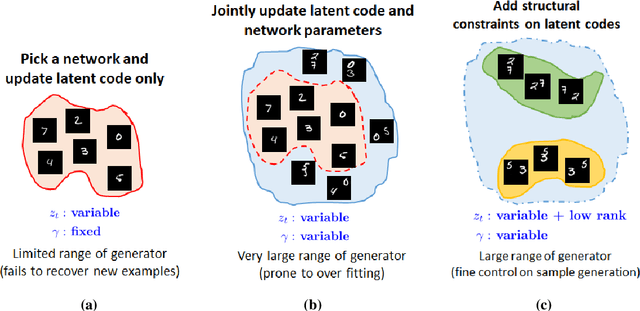
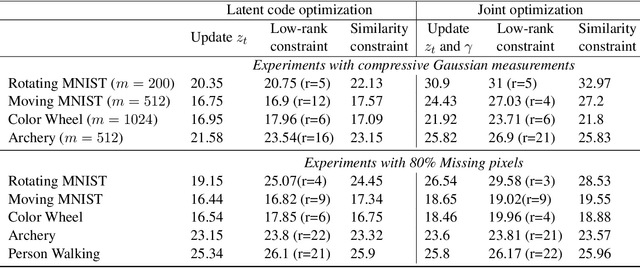
Finding compact representation of videos is an essential component in almost every problem related to video processing or understanding. In this paper, we propose a generative model to learn compact latent codes that can efficiently represent and reconstruct a video sequence from its missing or under-sampled measurements. We use a generative network that is trained to map a compact code into an image. We first demonstrate that if a video sequence belongs to the range of the pretrained generative network, then we can recover it by estimating the underlying compact latent codes. Then we demonstrate that even if the video sequence does not belong to the range of a pretrained network, we can still recover the true video sequence by jointly updating the latent codes and the weights of the generative network. To avoid overfitting in our model, we regularize the recovery problem by imposing low-rank and similarity constraints on the latent codes of the neighboring frames in the video sequence. We use our methods to recover a variety of videos from compressive measurements at different compression rates. We also demonstrate that we can generate missing frames in a video sequence by interpolating the latent codes of the observed frames in the low-dimensional space.