 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably Convergent Algorithms for Solving Inverse Problems Using Generative Models
Paper and Code
May 13, 2021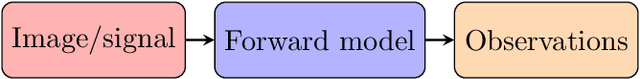
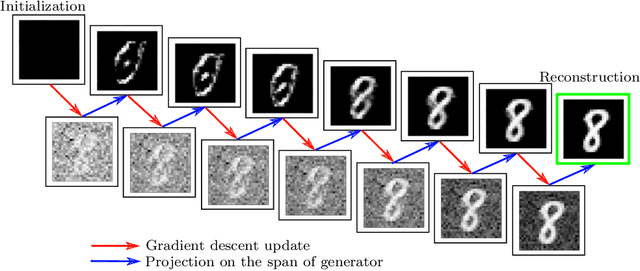


The traditional approach of hand-crafting priors (such as sparsity) for solving inverse problems is slowly being replaced by the use of richer learned priors (such as those modeled by deep generative networks). In this work, we study the algorithmic aspects of such a learning-based approach from a theoretical perspective. For certain generative network architectures, we establish a simple non-convex algorithmic approach that (a) theoretically enjoys linear convergence guarantees for certain linear and nonlinear inverse problems, and (b) empirically improves upon conventional techniques such as back-propagation. We support our claims with the experimental results for solving various inverse problems. We also propose an extension of our approach that can handle model mismatch (i.e., situations where the generative network prior is not exactly applicable). Together, our contributions serve as building blocks towards a principled use of generative models in inverse problems with more complete algorithmic understanding.