 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFMS$^2$: Unified Flow Matching for Segmentation and Synthesis of Thin Structures
Mar 14, 2026Segmenting thin structures like infrastructure cracks and anatomical vessels is a task hampered by topology-sensitive geometry, high annotation costs, and poor generalization across domains. Existing methods address these challenges in isolation. We propose FMS$^2$, a flow-matching framework with two modules. (1) SegFlow is a 2.96M-parameter segmentation model built on a standard encoder-decoder backbone that recasts prediction as continuous image $\rightarrow$ mask transport. It learns a time-indexed velocity field with a flow-matching regression loss and outputs the mask via ODE integration, rather than supervising only end-state logits. This trajectory-level supervision improves thin-structure continuity and sharpness, compared with tuned topology-aware loss baselines, without auxiliary topology heads, post-processing, or multi-term loss engineering. (2) SynFlow is a mask-conditioned mask $\rightarrow$ image generator that produces pixel-aligned synthetic image-mask pairs. It injects mask geometry at multiple scales and emphasizes boundary bands via edge-aware gating, while a controllable mask generator expands sparsity, width, and branching regimes. On five crack and vessel benchmarks, SegFlow alone outperforms strong CNN, Transformer, Mamba, and generative baselines, improving the volumetric metric (mean IoU) from 0.511 to 0.599 (+17.2%) and reducing the topological metric (Betti matching error) from 82.145 to 51.524 (-37.3%). When training with limited labels, augmenting SegFlow with SynFlow-generated pairs recovers near-full performance using 25% of real annotations and improves cross-domain IoU by 0.11 on average. Unlike classical data augmentation that promotes invariance via label-preserving transforms, SynFlow provides pixel-aligned paired supervision with controllable structural shifts (e.g., sparsity, width, branching), which is particularly effective under domain shift.
Reference-Guided Identity Preserving Face Restoration
May 28, 2025Preserving face identity is a critical yet persistent challenge in diffusion-based image restoration. While reference faces offer a path forward, existing reference-based methods often fail to fully exploit their potential. This paper introduces a novel approach that maximizes reference face utility for improved face restoration and identity preservation. Our method makes three key contributions: 1) Composite Context, a comprehensive representation that fuses multi-level (high- and low-level) information from the reference face, offering richer guidance than prior singular representations. 2) Hard Example Identity Loss, a novel loss function that leverages the reference face to address the identity learning inefficiencies found in the existing identity loss. 3) A training-free method to adapt the model to multi-reference inputs during inference. The proposed method demonstrably restores high-quality faces and achieves state-of-the-art identity preserving restoration on benchmarks such as FFHQ-Ref and CelebA-Ref-Test, consistently outperforming previous work.
UnZipLoRA: Separating Content and Style from a Single Image
Dec 05, 2024
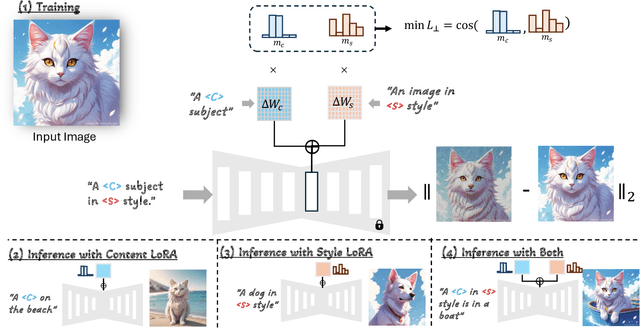
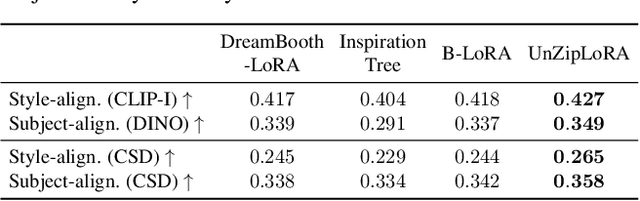
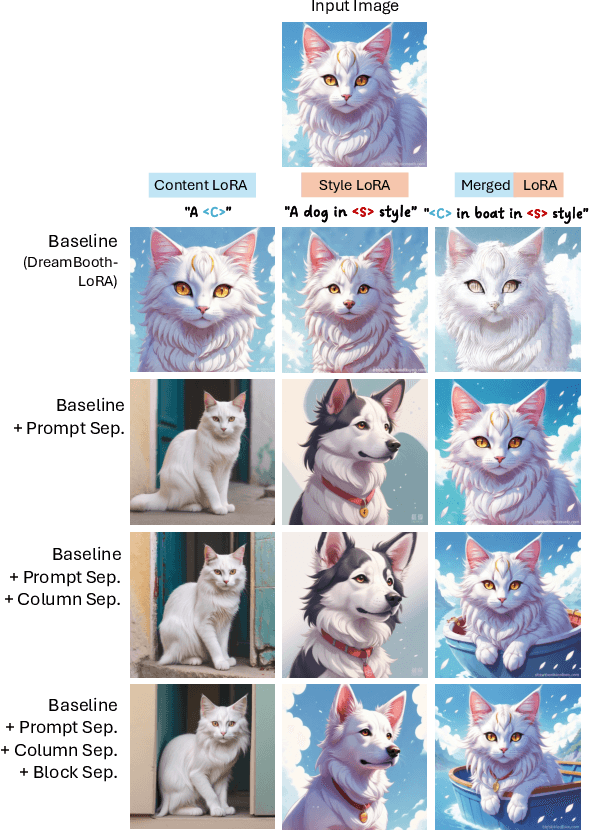
This paper introduces UnZipLoRA, a method for decomposing an image into its constituent subject and style, represented as two distinct LoRAs (Low-Rank Adaptations). Unlike existing personalization techniques that focus on either subject or style in isolation, or require separate training sets for each, UnZipLoRA disentangles these elements from a single image by training both the LoRAs simultaneously. UnZipLoRA ensures that the resulting LoRAs are compatible, i.e., they can be seamlessly combined using direct addition. UnZipLoRA enables independent manipulation and recontextualization of subject and style, including generating variations of each, applying the extracted style to new subjects, and recombining them to reconstruct the original image or create novel variations. To address the challenge of subject and style entanglement, UnZipLoRA employs a novel prompt separation technique, as well as column and block separation strategies to accurately preserve the characteristics of subject and style, and ensure compatibility between the learned LoRAs. Evaluation with human studies and quantitative metrics demonstrates UnZipLoRA's effectiveness compared to other state-of-the-art methods, including DreamBooth-LoRA, Inspiration Tree, and B-LoRA.
Street TryOn: Learning In-the-Wild Virtual Try-On from Unpaired Person Images
Nov 27, 2023Virtual try-on has become a popular research topic, but most existing methods focus on studio images with a clean background. They can achieve plausible results for this studio try-on setting by learning to warp a garment image to fit a person's body from paired training data, i.e., garment images paired with images of people wearing the same garment. Such data is often collected from commercial websites, where each garment is demonstrated both by itself and on several models. By contrast, it is hard to collect paired data for in-the-wild scenes, and therefore, virtual try-on for casual images of people against cluttered backgrounds is rarely studied. In this work, we fill the gap in the current virtual try-on research by (1) introducing a Street TryOn benchmark to evaluate performance on street scenes and (2) proposing a novel method that can learn without paired data, from a set of in-the-wild person images directly. Our method can achieve robust performance across shop and street domains using a novel DensePose warping correction method combined with diffusion-based inpainting controlled by pose and semantic segmentation. Our experiments demonstrate competitive performance for standard studio try-on tasks and SOTA performance for street try-on and cross-domain try-on tasks.
ZipLoRA: Any Subject in Any Style by Effectively Merging LoRAs
Nov 22, 2023



Methods for finetuning generative models for concept-driven personalization generally achieve strong results for subject-driven or style-driven generation. Recently, low-rank adaptations (LoRA) have been proposed as a parameter-efficient way of achieving concept-driven personalization. While recent work explores the combination of separate LoRAs to achieve joint generation of learned styles and subjects, existing techniques do not reliably address the problem; they often compromise either subject fidelity or style fidelity. We propose ZipLoRA, a method to cheaply and effectively merge independently trained style and subject LoRAs in order to achieve generation of any user-provided subject in any user-provided style. Experiments on a wide range of subject and style combinations show that ZipLoRA can generate compelling results with meaningful improvements over baselines in subject and style fidelity while preserving the ability to recontextualize. Project page: https://ziplora.github.io
JoIN: Joint GANs Inversion for Intrinsic Image Decomposition
May 18, 2023In this work, we propose to solve ill-posed inverse imaging problems using a bank of Generative Adversarial Networks (GAN) as a prior and apply our method to the case of Intrinsic Image Decomposition for faces and materials. Our method builds on the demonstrated success of GANs to capture complex image distributions. At the core of our approach is the idea that the latent space of a GAN is a well-suited optimization domain to solve inverse problems. Given an input image, we propose to jointly inverse the latent codes of a set of GANs and combine their outputs to reproduce the input. Contrary to most GAN inversion methods which are limited to inverting only a single GAN, we demonstrate that it is possible to maintain distribution priors while inverting several GANs jointly. We show that our approach is modular, allowing various forward imaging models, that it can successfully decompose both synthetic and real images, and provides additional advantages such as leveraging properties of GAN latent space for image relighting.
Make It So: Steering StyleGAN for Any Image Inversion and Editing
Apr 27, 2023StyleGAN's disentangled style representation enables powerful image editing by manipulating the latent variables, but accurately mapping real-world images to their latent variables (GAN inversion) remains a challenge. Existing GAN inversion methods struggle to maintain editing directions and produce realistic results. To address these limitations, we propose Make It So, a novel GAN inversion method that operates in the $\mathcal{Z}$ (noise) space rather than the typical $\mathcal{W}$ (latent style) space. Make It So preserves editing capabilities, even for out-of-domain images. This is a crucial property that was overlooked in prior methods. Our quantitative evaluations demonstrate that Make It So outperforms the state-of-the-art method PTI~\cite{roich2021pivotal} by a factor of five in inversion accuracy and achieves ten times better edit quality for complex indoor scenes.
MultiStyleGAN: Multiple One-shot Face Stylizations using a Single GAN
Oct 08, 2022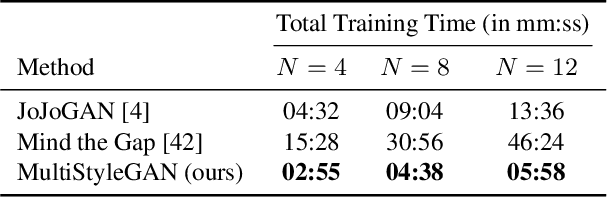
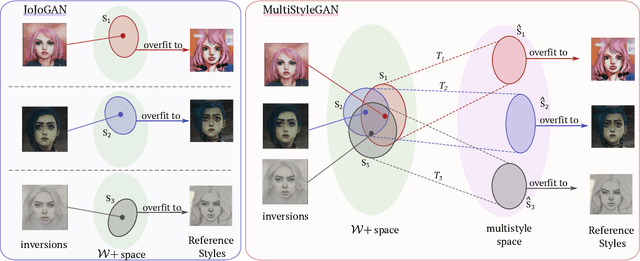
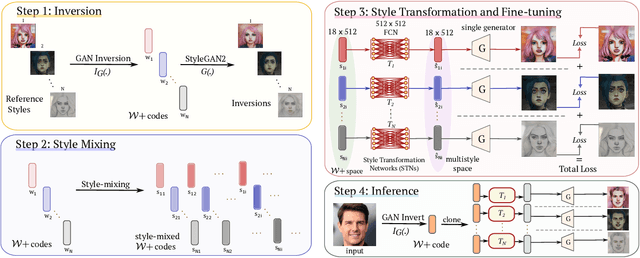

Image stylization aims at applying a reference style to arbitrary input images. A common scenario is one-shot stylization, where only one example is available for each reference style. A successful recent approach for one-shot face stylization is JoJoGAN, which fine-tunes a pre-trained StyleGAN2 generator on a single style reference image. However, it cannot generate multiple stylizations without fine-tuning a new model for each style separately. In this work, we present a MultiStyleGAN method that is capable of producing multiple different face stylizations at once by fine-tuning a single generator. The key component of our method is a learnable Style Transformation module that takes latent codes as input and learns linear mappings to different regions of the latent space to produce distinct codes for each style, resulting in a multistyle space. Our model inherently mitigates overfitting since it is trained on multiple styles, hence improving the quality of stylizations. Our method can learn upwards of $12$ image stylizations at once, bringing upto $8\times$ improvement in training time. We support our results through user studies that indicate meaningful improvements over existing methods.
Near Perfect GAN Inversion
Feb 23, 2022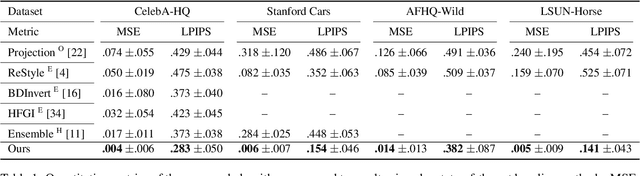
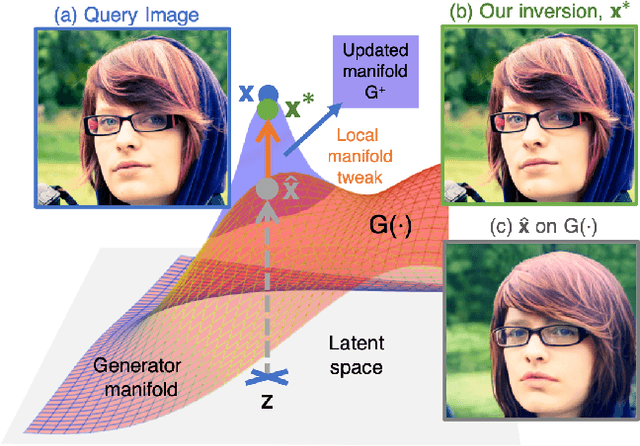


To edit a real photo using Generative Adversarial Networks (GANs), we need a GAN inversion algorithm to identify the latent vector that perfectly reproduces it. Unfortunately, whereas existing inversion algorithms can synthesize images similar to real photos, they cannot generate the identical clones needed in most applications. Here, we derive an algorithm that achieves near perfect reconstructions of photos. Rather than relying on encoder- or optimization-based methods to find an inverse mapping on a fixed generator $G(\cdot)$, we derive an approach to locally adjust $G(\cdot)$ to more optimally represent the photos we wish to synthesize. This is done by locally tweaking the learned mapping $G(\cdot)$ s.t. $\| {\bf x} - G({\bf z}) \|<\epsilon$, with ${\bf x}$ the photo we wish to reproduce, ${\bf z}$ the latent vector, $\|\cdot\|$ an appropriate metric, and $\epsilon > 0$ a small scalar. We show that this approach can not only produce synthetic images that are indistinguishable from the real photos we wish to replicate, but that these images are readily editable. We demonstrate the effectiveness of the derived algorithm on a variety of datasets including human faces, animals, and cars, and discuss its importance for diversity and inclusion.
Learning by Cheating : An End-to-End Zero Shot Framework for Autonomous Drone Navigation
Nov 11, 2021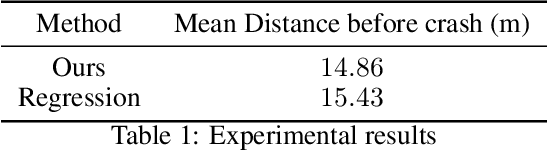
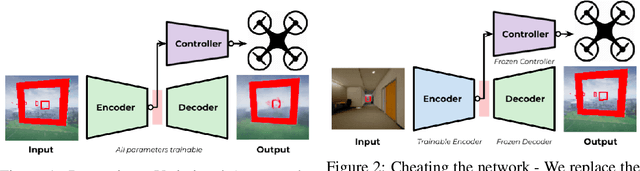
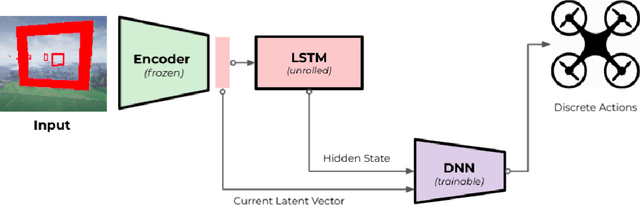

This paper proposes a novel framework for autonomous drone navigation through a cluttered environment. Control policies are learnt in a low-level environment during training and are applied to a complex environment during inference. The controller learnt in the training environment is tricked into believing that the robot is still in the training environment when it is actually navigating in a more complex environment. The framework presented in this paper can be adapted to reuse simple policies in more complex tasks. We also show that the framework can be used as an interpretation tool for reinforcement learning algorithms.