 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowFixer: Towards Detail-Preserving Subject-Driven Generation
Feb 24, 2026We present FlowFixer, a refinement framework for subject-driven generation (SDG) that restores fine details lost during generation caused by changes in scale and perspective of a subject. FlowFixer proposes direct image-to-image translation from visual references, avoiding ambiguities in language prompts. To enable image-to-image training, we introduce a one-step denoising scheme to generate self-supervised training data, which automatically removes high-frequency details while preserving global structure, effectively simulating real-world SDG errors. We further propose a keypoint matching-based metric to properly assess fidelity in details beyond semantic similarities usually measured by CLIP or DINO. Experimental results demonstrate that FlowFixer outperforms state-of-the-art SDG methods in both qualitative and quantitative evaluations, setting a new benchmark for high-fidelity subject-driven generation.
DDiT: Dynamic Patch Scheduling for Efficient Diffusion Transformers
Feb 19, 2026Diffusion Transformers (DiTs) have achieved state-of-the-art performance in image and video generation, but their success comes at the cost of heavy computation. This inefficiency is largely due to the fixed tokenization process, which uses constant-sized patches throughout the entire denoising phase, regardless of the content's complexity. We propose dynamic tokenization, an efficient test-time strategy that varies patch sizes based on content complexity and the denoising timestep. Our key insight is that early timesteps only require coarser patches to model global structure, while later iterations demand finer (smaller-sized) patches to refine local details. During inference, our method dynamically reallocates patch sizes across denoising steps for image and video generation and substantially reduces cost while preserving perceptual generation quality. Extensive experiments demonstrate the effectiveness of our approach: it achieves up to $3.52\times$ and $3.2\times$ speedup on FLUX-1.Dev and Wan $2.1$, respectively, without compromising the generation quality and prompt adherence.
Disentanglement in T-space for Faster and Distributed Training of Diffusion Models with Fewer Latent-states
Aug 20, 2025We challenge a fundamental assumption of diffusion models, namely, that a large number of latent-states or time-steps is required for training so that the reverse generative process is close to a Gaussian. We first show that with careful selection of a noise schedule, diffusion models trained over a small number of latent states (i.e. $T \sim 32$) match the performance of models trained over a much large number of latent states ($T \sim 1,000$). Second, we push this limit (on the minimum number of latent states required) to a single latent-state, which we refer to as complete disentanglement in T-space. We show that high quality samples can be easily generated by the disentangled model obtained by combining several independently trained single latent-state models. We provide extensive experiments to show that the proposed disentangled model provides 4-6$\times$ faster convergence measured across a variety of metrics on two different datasets.
Near Perfect GAN Inversion
Feb 23, 2022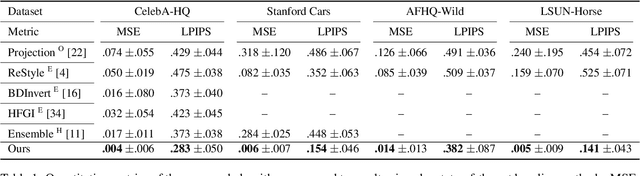


To edit a real photo using Generative Adversarial Networks (GANs), we need a GAN inversion algorithm to identify the latent vector that perfectly reproduces it. Unfortunately, whereas existing inversion algorithms can synthesize images similar to real photos, they cannot generate the identical clones needed in most applications. Here, we derive an algorithm that achieves near perfect reconstructions of photos. Rather than relying on encoder- or optimization-based methods to find an inverse mapping on a fixed generator $G(\cdot)$, we derive an approach to locally adjust $G(\cdot)$ to more optimally represent the photos we wish to synthesize. This is done by locally tweaking the learned mapping $G(\cdot)$ s.t. $\| {\bf x} - G({\bf z}) \|<\epsilon$, with ${\bf x}$ the photo we wish to reproduce, ${\bf z}$ the latent vector, $\|\cdot\|$ an appropriate metric, and $\epsilon > 0$ a small scalar. We show that this approach can not only produce synthetic images that are indistinguishable from the real photos we wish to replicate, but that these images are readily editable. We demonstrate the effectiveness of the derived algorithm on a variety of datasets including human faces, animals, and cars, and discuss its importance for diversity and inclusion.
Rayleigh EigenDirections (REDs): GAN latent space traversals for multidimensional features
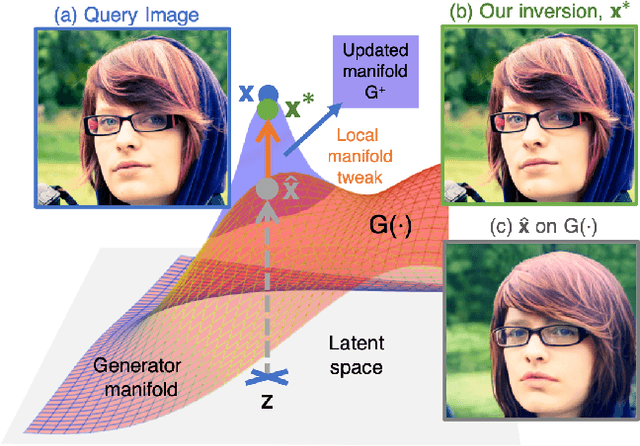
Jan 25, 2022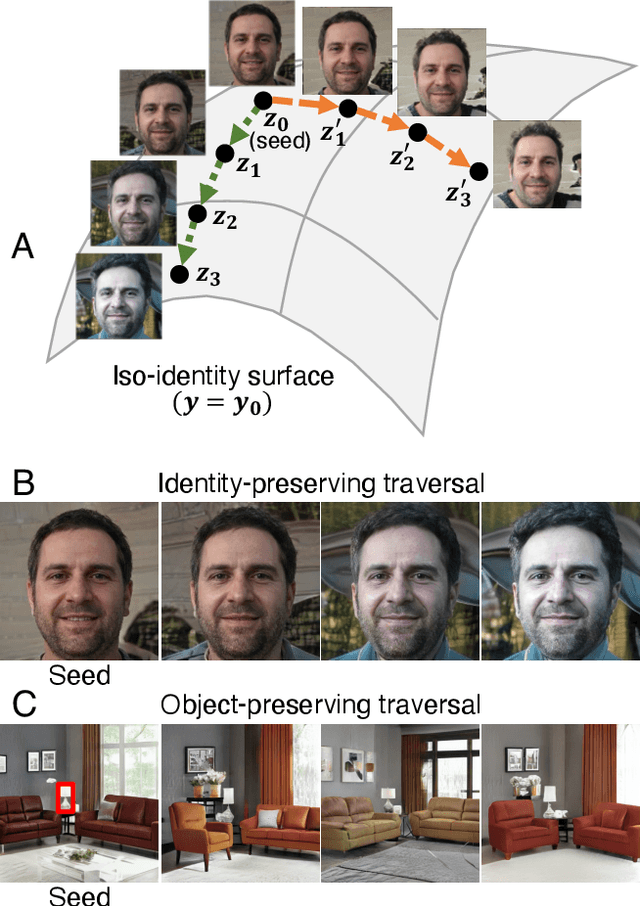

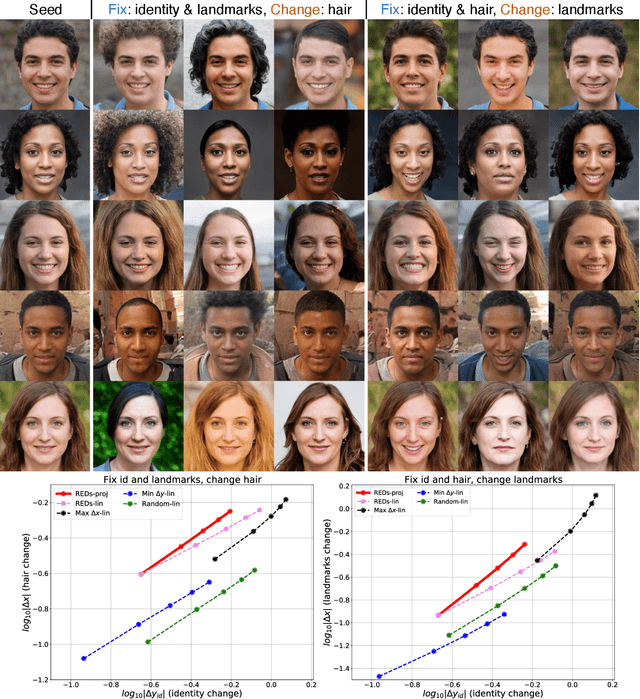

We present a method for finding paths in a deep generative model's latent space that can maximally vary one set of image features while holding others constant. Crucially, unlike past traversal approaches, ours can manipulate multidimensional features of an image such as facial identity and pixels within a specified region. Our method is principled and conceptually simple: optimal traversal directions are chosen by maximizing differential changes to one feature set such that changes to another set are negligible. We show that this problem is nearly equivalent to one of Rayleigh quotient maximization, and provide a closed-form solution to it based on solving a generalized eigenvalue equation. We use repeated computations of the corresponding optimal directions, which we call Rayleigh EigenDirections (REDs), to generate appropriately curved paths in latent space. We empirically evaluate our method using StyleGAN2 on two image domains: faces and living rooms. We show that our method is capable of controlling various multidimensional features out of the scope of previous latent space traversal methods: face identity, spatial frequency bands, pixels within a region, and the appearance and position of an object. Our work suggests that a wealth of opportunities lies in the local analysis of the geometry and semantics of latent spaces.
Semantic Video CNNs through Representation Warping
Aug 10, 2017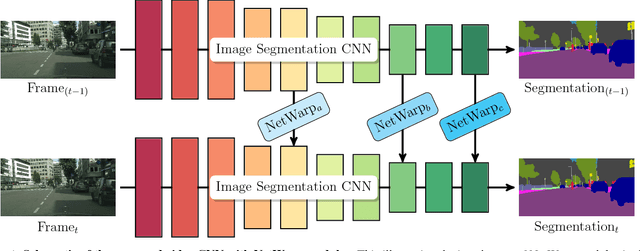



In this work, we propose a technique to convert CNN models for semantic segmentation of static images into CNNs for video data. We describe a warping method that can be used to augment existing architectures with very little extra computational cost. This module is called NetWarp and we demonstrate its use for a range of network architectures. The main design principle is to use optical flow of adjacent frames for warping internal network representations across time. A key insight of this work is that fast optical flow methods can be combined with many different CNN architectures for improved performance and end-to-end training. Experiments validate that the proposed approach incurs only little extra computational cost, while improving performance, when video streams are available. We achieve new state-of-the-art results on the CamVid and Cityscapes benchmark datasets and show consistent improvements over different baseline networks. Our code and models will be available at http://segmentation.is.tue.mpg.de
Video Propagation Networks
Apr 11, 2017
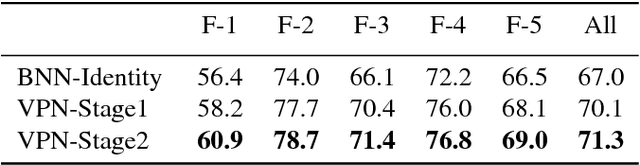
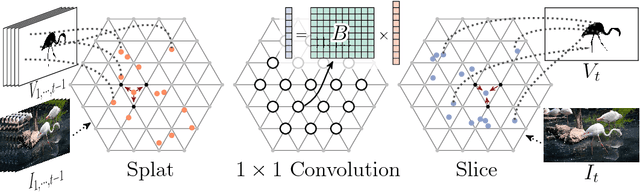
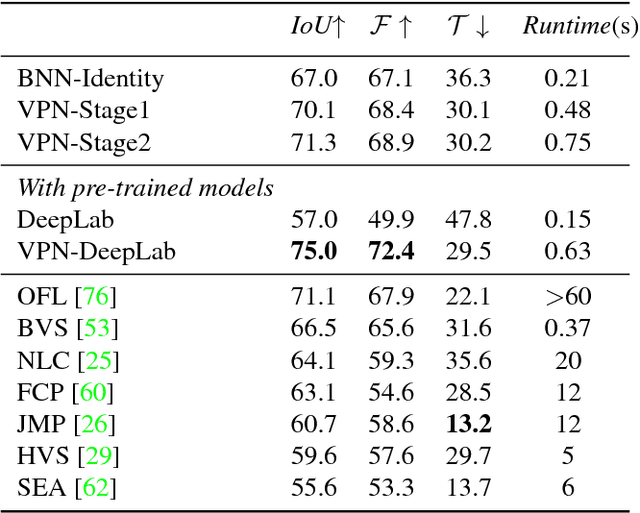
We propose a technique that propagates information forward through video data. The method is conceptually simple and can be applied to tasks that require the propagation of structured information, such as semantic labels, based on video content. We propose a 'Video Propagation Network' that processes video frames in an adaptive manner. The model is applied online: it propagates information forward without the need to access future frames. In particular we combine two components, a temporal bilateral network for dense and video adaptive filtering, followed by a spatial network to refine features and increased flexibility. We present experiments on video object segmentation and semantic video segmentation and show increased performance comparing to the best previous task-specific methods, while having favorable runtime. Additionally we demonstrate our approach on an example regression task of color propagation in a grayscale video.
Superpixel Convolutional Networks using Bilateral Inceptions
Aug 08, 2016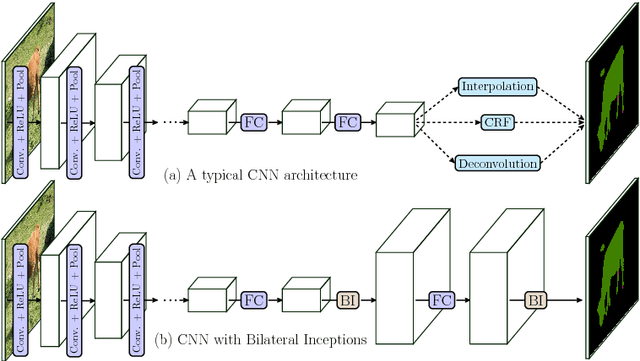
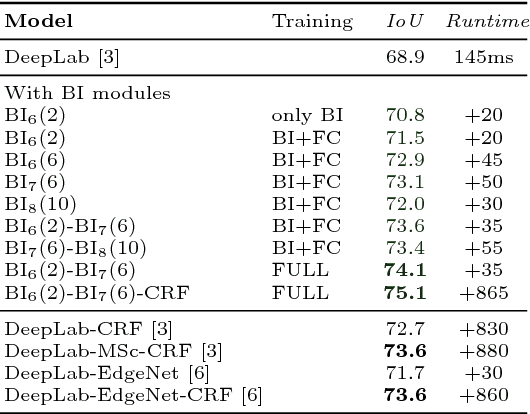
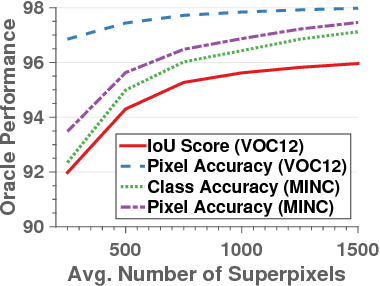

In this paper we propose a CNN architecture for semantic image segmentation. We introduce a new 'bilateral inception' module that can be inserted in existing CNN architectures and performs bilateral filtering, at multiple feature-scales, between superpixels in an image. The feature spaces for bilateral filtering and other parameters of the module are learned end-to-end using standard backpropagation techniques. The bilateral inception module addresses two issues that arise with general CNN segmentation architectures. First, this module propagates information between (super) pixels while respecting image edges, thus using the structured information of the problem for improved results. Second, the layer recovers a full resolution segmentation result from the lower resolution solution of a CNN. In the experiments, we modify several existing CNN architectures by inserting our inception module between the last CNN (1x1 convolution) layers. Empirical results on three different datasets show reliable improvements not only in comparison to the baseline networks, but also in comparison to several dense-pixel prediction techniques such as CRFs, while being competitive in time.
Efficient 2D and 3D Facade Segmentation using Auto-Context
Jun 21, 2016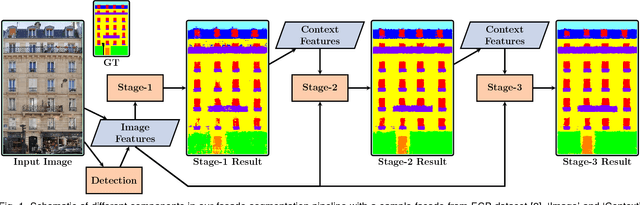
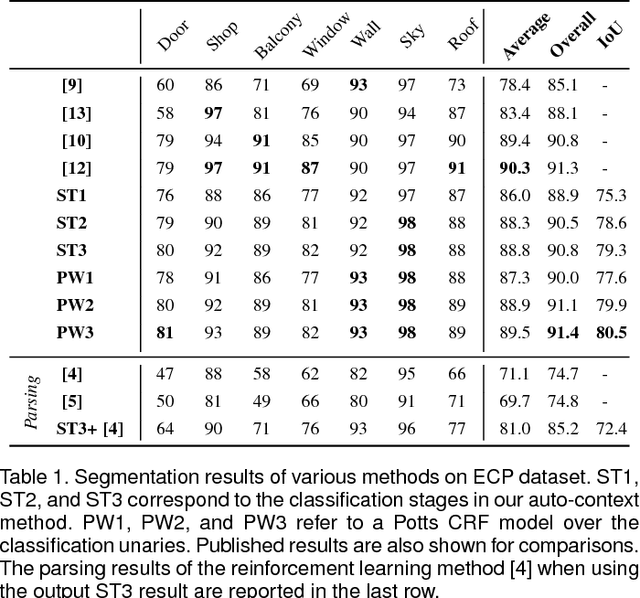


This paper introduces a fast and efficient segmentation technique for 2D images and 3D point clouds of building facades. Facades of buildings are highly structured and consequently most methods that have been proposed for this problem aim to make use of this strong prior information. Contrary to most prior work, we are describing a system that is almost domain independent and consists of standard segmentation methods. We train a sequence of boosted decision trees using auto-context features. This is learned using stacked generalization. We find that this technique performs better, or comparable with all previous published methods and present empirical results on all available 2D and 3D facade benchmark datasets. The proposed method is simple to implement, easy to extend, and very efficient at test-time inference.