 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Task-Specific Generalized Convolutions in the Permutohedral Lattice
Sep 09, 2019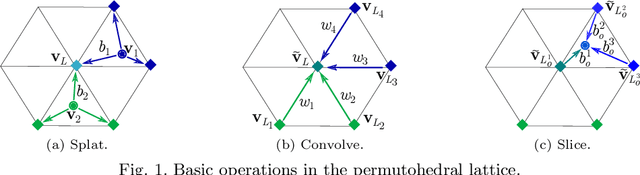
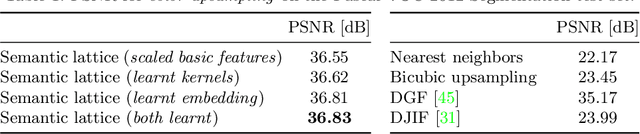
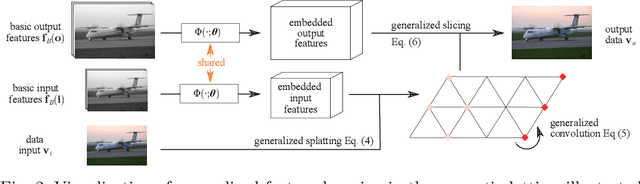

Dense prediction tasks typically employ encoder-decoder architectures, but the prevalent convolutions in the decoder are not image-adaptive and can lead to boundary artifacts. Different generalized convolution operations have been introduced to counteract this. We go beyond these by leveraging guidance data to redefine their inherent notion of proximity. Our proposed network layer builds on the permutohedral lattice, which performs sparse convolutions in a high-dimensional space allowing for powerful non-local operations despite small filters. Multiple features with different characteristics span this permutohedral space. In contrast to prior work, we learn these features in a task-specific manner by generalizing the basic permutohedral operations to learnt feature representations. As the resulting objective is complex, a carefully designed framework and learning procedure are introduced, yielding rich feature embeddings in practice. We demonstrate the general applicability of our approach in different joint upsampling tasks. When adding our network layer to state-of-the-art networks for optical flow and semantic segmentation, boundary artifacts are removed and the accuracy is improved.
Neural Body Fitting: Unifying Deep Learning and Model-Based Human Pose and Shape Estimation
Aug 17, 2018



Direct prediction of 3D body pose and shape remains a challenge even for highly parameterized deep learning models. Mapping from the 2D image space to the prediction space is difficult: perspective ambiguities make the loss function noisy and training data is scarce. In this paper, we propose a novel approach (Neural Body Fitting (NBF)). It integrates a statistical body model within a CNN, leveraging reliable bottom-up semantic body part segmentation and robust top-down body model constraints. NBF is fully differentiable and can be trained using 2D and 3D annotations. In detailed experiments, we analyze how the components of our model affect performance, especially the use of part segmentations as an explicit intermediate representation, and present a robust, efficiently trainable framework for 3D human pose estimation from 2D images with competitive results on standard benchmarks. Code will be made available at http://github.com/mohomran/neural_body_fitting
Towards Accurate Markerless Human Shape and Pose Estimation over Time
Apr 30, 2018



Existing marker-less motion capture methods often assume known backgrounds, static cameras, and sequence specific motion priors, which narrows its application scenarios. Here we propose a fully automatic method that given multi-view video, estimates 3D human motion and body shape. We take recent SMPLify \cite{bogo2016keep} as the base method, and extend it in several ways. First we fit the body to 2D features detected in multi-view images. Second, we use a CNN method to segment the person in each image and fit the 3D body model to the contours to further improves accuracy. Third we utilize a generic and robust DCT temporal prior to handle the left and right side swapping issue sometimes introduced by the 2D pose estimator. Validation on standard benchmarks shows our results are comparable to the state of the art and also provide a realistic 3D shape avatar. We also demonstrate accurate results on HumanEva and on challenging dance sequences from YouTube in monocular case.
Semantic Video CNNs through Representation Warping
Aug 10, 2017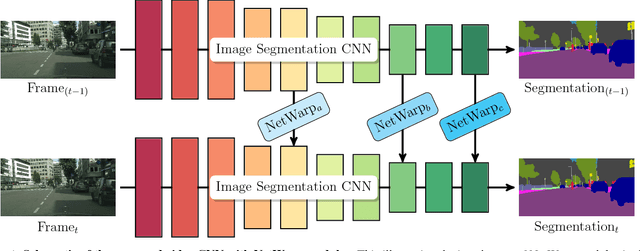



In this work, we propose a technique to convert CNN models for semantic segmentation of static images into CNNs for video data. We describe a warping method that can be used to augment existing architectures with very little extra computational cost. This module is called NetWarp and we demonstrate its use for a range of network architectures. The main design principle is to use optical flow of adjacent frames for warping internal network representations across time. A key insight of this work is that fast optical flow methods can be combined with many different CNN architectures for improved performance and end-to-end training. Experiments validate that the proposed approach incurs only little extra computational cost, while improving performance, when video streams are available. We achieve new state-of-the-art results on the CamVid and Cityscapes benchmark datasets and show consistent improvements over different baseline networks. Our code and models will be available at http://segmentation.is.tue.mpg.de
A Generative Model of People in Clothing
Jul 31, 2017



We present the first image-based generative model of people in clothing for the full body. We sidestep the commonly used complex graphics rendering pipeline and the need for high-quality 3D scans of dressed people. Instead, we learn generative models from a large image database. The main challenge is to cope with the high variance in human pose, shape and appearance. For this reason, pure image-based approaches have not been considered so far. We show that this challenge can be overcome by splitting the generating process in two parts. First, we learn to generate a semantic segmentation of the body and clothing. Second, we learn a conditional model on the resulting segments that creates realistic images. The full model is differentiable and can be conditioned on pose, shape or color. The result are samples of people in different clothing items and styles. The proposed model can generate entirely new people with realistic clothing. In several experiments we present encouraging results that suggest an entirely data-driven approach to people generation is possible.
Unite the People: Closing the Loop Between 3D and 2D Human Representations
Jul 25, 2017
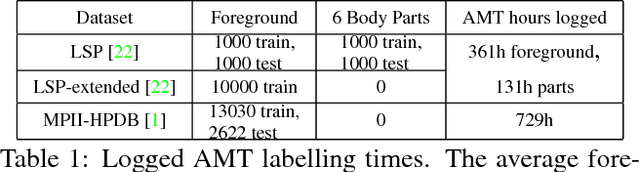


3D models provide a common ground for different representations of human bodies. In turn, robust 2D estimation has proven to be a powerful tool to obtain 3D fits "in-the- wild". However, depending on the level of detail, it can be hard to impossible to acquire labeled data for training 2D estimators on large scale. We propose a hybrid approach to this problem: with an extended version of the recently introduced SMPLify method, we obtain high quality 3D body model fits for multiple human pose datasets. Human annotators solely sort good and bad fits. This procedure leads to an initial dataset, UP-3D, with rich annotations. With a comprehensive set of experiments, we show how this data can be used to train discriminative models that produce results with an unprecedented level of detail: our models predict 31 segments and 91 landmark locations on the body. Using the 91 landmark pose estimator, we present state-of-the art results for 3D human pose and shape estimation using an order of magnitude less training data and without assumptions about gender or pose in the fitting procedure. We show that UP-3D can be enhanced with these improved fits to grow in quantity and quality, which makes the system deployable on large scale. The data, code and models are available for research purposes.
Reflectance Adaptive Filtering Improves Intrinsic Image Estimation
Jun 12, 2017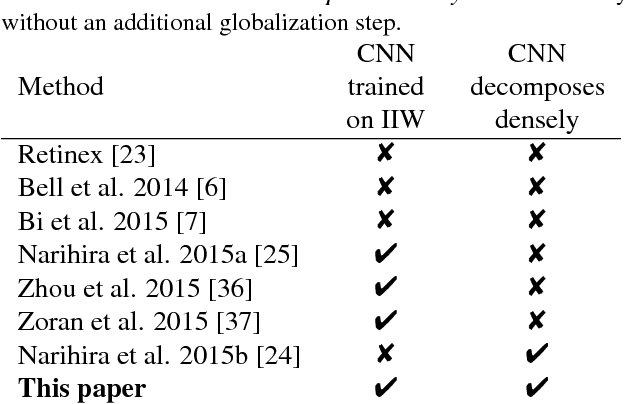
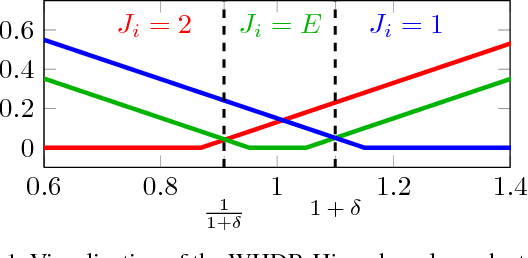
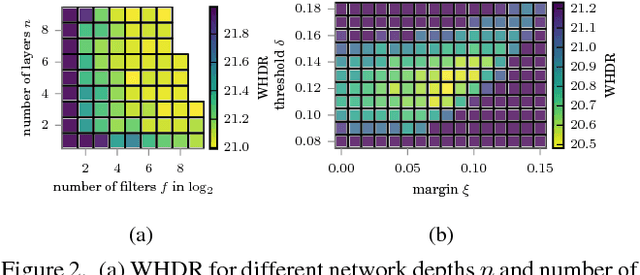

Separating an image into reflectance and shading layers poses a challenge for learning approaches because no large corpus of precise and realistic ground truth decompositions exists. The Intrinsic Images in the Wild~(IIW) dataset provides a sparse set of relative human reflectance judgments, which serves as a standard benchmark for intrinsic images. A number of methods use IIW to learn statistical dependencies between the images and their reflectance layer. Although learning plays an important role for high performance, we show that a standard signal processing technique achieves performance on par with current state-of-the-art. We propose a loss function for CNN learning of dense reflectance predictions. Our results show a simple pixel-wise decision, without any context or prior knowledge, is sufficient to provide a strong baseline on IIW. This sets a competitive baseline which only two other approaches surpass. We then develop a joint bilateral filtering method that implements strong prior knowledge about reflectance constancy. This filtering operation can be applied to any intrinsic image algorithm and we improve several previous results achieving a new state-of-the-art on IIW. Our findings suggest that the effect of learning-based approaches may have been over-estimated so far. Explicit prior knowledge is still at least as important to obtain high performance in intrinsic image decompositions.
Video Propagation Networks
Apr 11, 2017
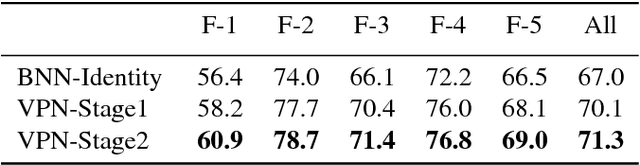
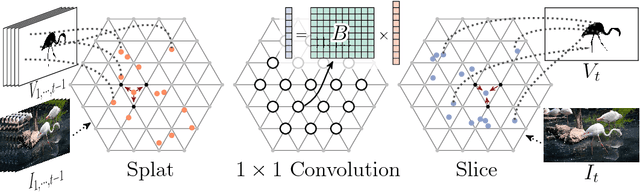
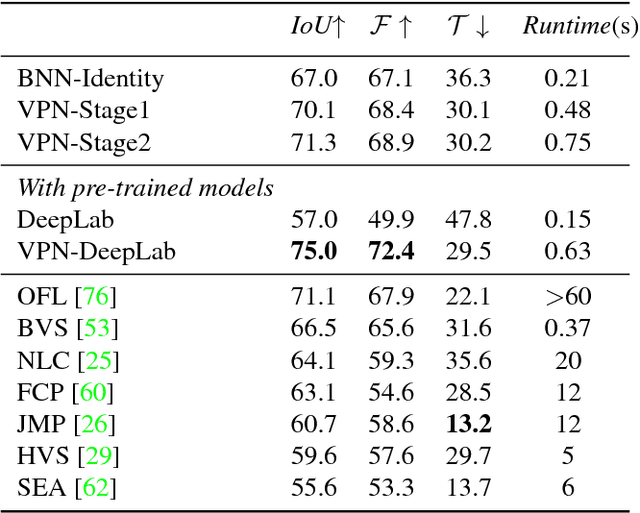
We propose a technique that propagates information forward through video data. The method is conceptually simple and can be applied to tasks that require the propagation of structured information, such as semantic labels, based on video content. We propose a 'Video Propagation Network' that processes video frames in an adaptive manner. The model is applied online: it propagates information forward without the need to access future frames. In particular we combine two components, a temporal bilateral network for dense and video adaptive filtering, followed by a spatial network to refine features and increased flexibility. We present experiments on video object segmentation and semantic video segmentation and show increased performance comparing to the best previous task-specific methods, while having favorable runtime. Additionally we demonstrate our approach on an example regression task of color propagation in a grayscale video.
Superpixel Convolutional Networks using Bilateral Inceptions
Aug 08, 2016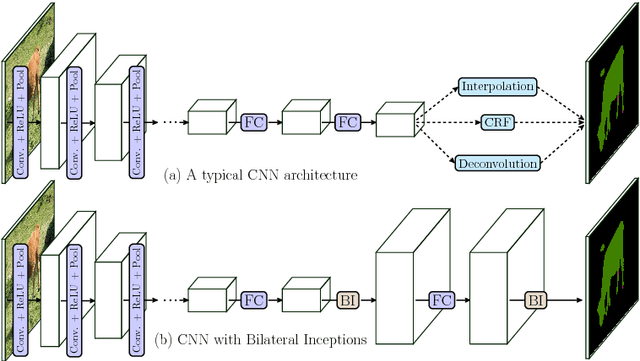
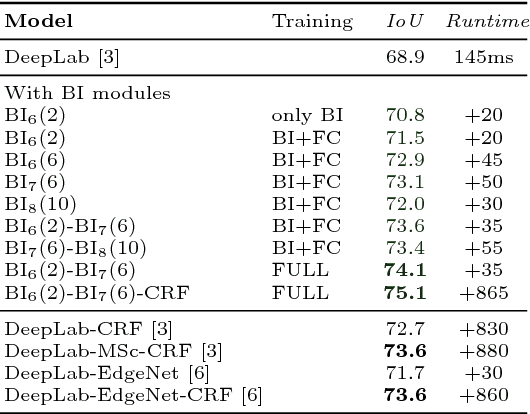
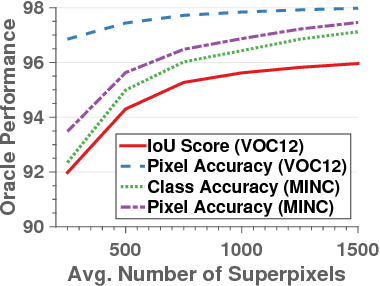

In this paper we propose a CNN architecture for semantic image segmentation. We introduce a new 'bilateral inception' module that can be inserted in existing CNN architectures and performs bilateral filtering, at multiple feature-scales, between superpixels in an image. The feature spaces for bilateral filtering and other parameters of the module are learned end-to-end using standard backpropagation techniques. The bilateral inception module addresses two issues that arise with general CNN segmentation architectures. First, this module propagates information between (super) pixels while respecting image edges, thus using the structured information of the problem for improved results. Second, the layer recovers a full resolution segmentation result from the lower resolution solution of a CNN. In the experiments, we modify several existing CNN architectures by inserting our inception module between the last CNN (1x1 convolution) layers. Empirical results on three different datasets show reliable improvements not only in comparison to the baseline networks, but also in comparison to several dense-pixel prediction techniques such as CRFs, while being competitive in time.
Efficient 2D and 3D Facade Segmentation using Auto-Context
Jun 21, 2016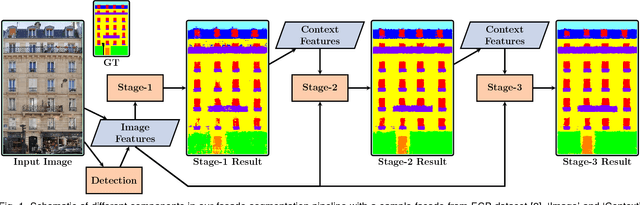
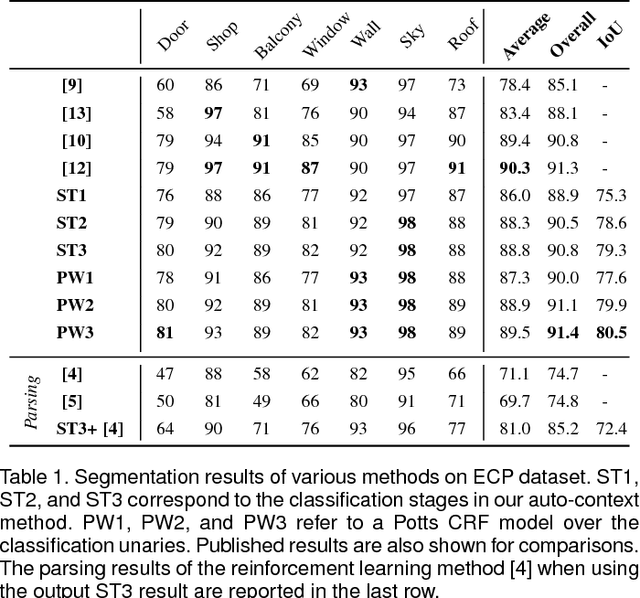


This paper introduces a fast and efficient segmentation technique for 2D images and 3D point clouds of building facades. Facades of buildings are highly structured and consequently most methods that have been proposed for this problem aim to make use of this strong prior information. Contrary to most prior work, we are describing a system that is almost domain independent and consists of standard segmentation methods. We train a sequence of boosted decision trees using auto-context features. This is learned using stacked generalization. We find that this technique performs better, or comparable with all previous published methods and present empirical results on all available 2D and 3D facade benchmark datasets. The proposed method is simple to implement, easy to extend, and very efficient at test-time inference.