 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Task-Specific Generalized Convolutions in the Permutohedral Lattice
Sep 09, 2019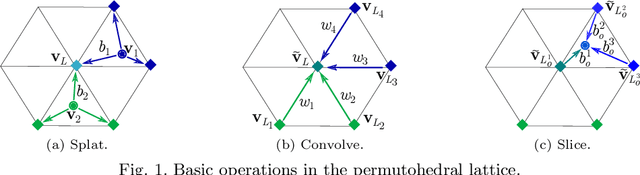
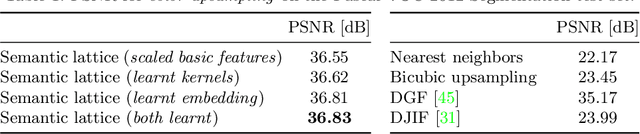
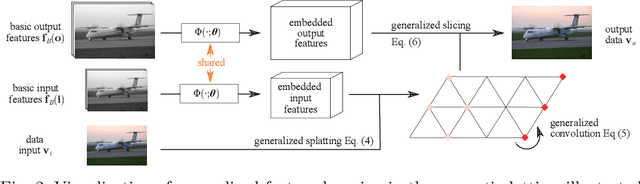

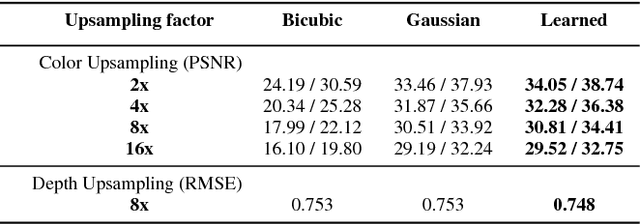
Dense prediction tasks typically employ encoder-decoder architectures, but the prevalent convolutions in the decoder are not image-adaptive and can lead to boundary artifacts. Different generalized convolution operations have been introduced to counteract this. We go beyond these by leveraging guidance data to redefine their inherent notion of proximity. Our proposed network layer builds on the permutohedral lattice, which performs sparse convolutions in a high-dimensional space allowing for powerful non-local operations despite small filters. Multiple features with different characteristics span this permutohedral space. In contrast to prior work, we learn these features in a task-specific manner by generalizing the basic permutohedral operations to learnt feature representations. As the resulting objective is complex, a carefully designed framework and learning procedure are introduced, yielding rich feature embeddings in practice. We demonstrate the general applicability of our approach in different joint upsampling tasks. When adding our network layer to state-of-the-art networks for optical flow and semantic segmentation, boundary artifacts are removed and the accuracy is improved.
Unite the People: Closing the Loop Between 3D and 2D Human Representations
Jul 25, 2017
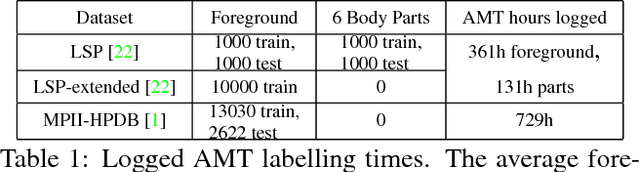


3D models provide a common ground for different representations of human bodies. In turn, robust 2D estimation has proven to be a powerful tool to obtain 3D fits "in-the- wild". However, depending on the level of detail, it can be hard to impossible to acquire labeled data for training 2D estimators on large scale. We propose a hybrid approach to this problem: with an extended version of the recently introduced SMPLify method, we obtain high quality 3D body model fits for multiple human pose datasets. Human annotators solely sort good and bad fits. This procedure leads to an initial dataset, UP-3D, with rich annotations. With a comprehensive set of experiments, we show how this data can be used to train discriminative models that produce results with an unprecedented level of detail: our models predict 31 segments and 91 landmark locations on the body. Using the 91 landmark pose estimator, we present state-of-the art results for 3D human pose and shape estimation using an order of magnitude less training data and without assumptions about gender or pose in the fitting procedure. We show that UP-3D can be enhanced with these improved fits to grow in quantity and quality, which makes the system deployable on large scale. The data, code and models are available for research purposes.
Superpixel Convolutional Networks using Bilateral Inceptions
Aug 08, 2016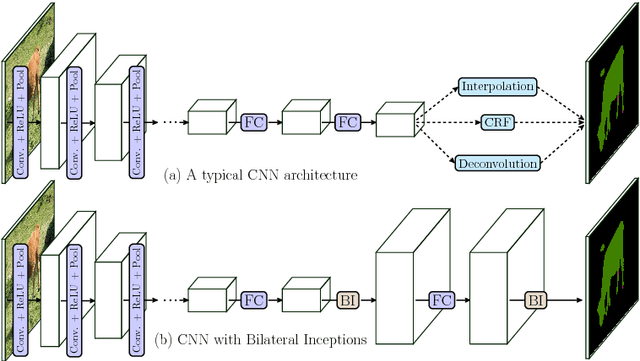
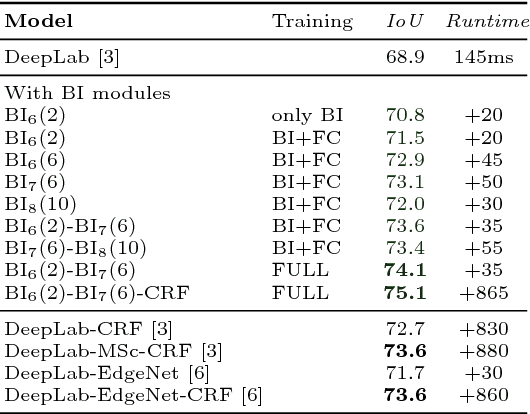
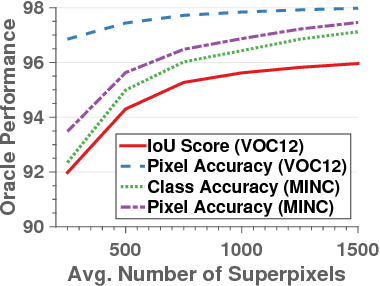

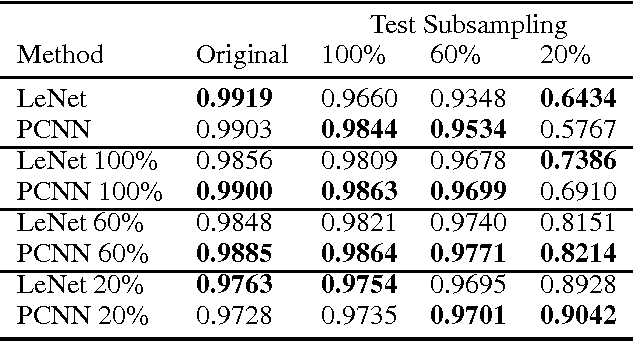
In this paper we propose a CNN architecture for semantic image segmentation. We introduce a new 'bilateral inception' module that can be inserted in existing CNN architectures and performs bilateral filtering, at multiple feature-scales, between superpixels in an image. The feature spaces for bilateral filtering and other parameters of the module are learned end-to-end using standard backpropagation techniques. The bilateral inception module addresses two issues that arise with general CNN segmentation architectures. First, this module propagates information between (super) pixels while respecting image edges, thus using the structured information of the problem for improved results. Second, the layer recovers a full resolution segmentation result from the lower resolution solution of a CNN. In the experiments, we modify several existing CNN architectures by inserting our inception module between the last CNN (1x1 convolution) layers. Empirical results on three different datasets show reliable improvements not only in comparison to the baseline networks, but also in comparison to several dense-pixel prediction techniques such as CRFs, while being competitive in time.
Semantic Instance Annotation of Street Scenes by 3D to 2D Label Transfer
Apr 12, 2016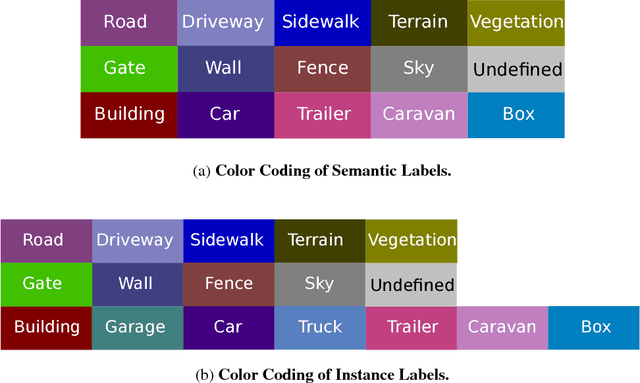

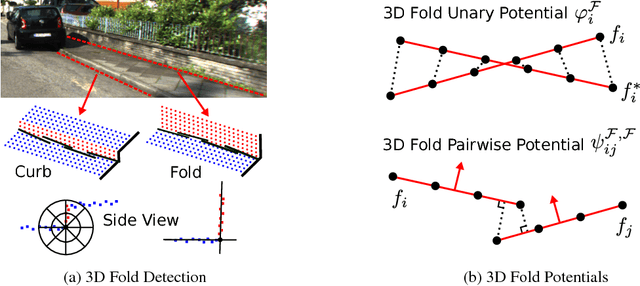
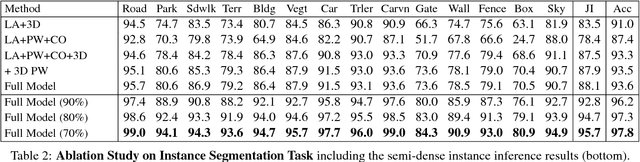
Semantic annotations are vital for training models for object recognition, semantic segmentation or scene understanding. Unfortunately, pixelwise annotation of images at very large scale is labor-intensive and only little labeled data is available, particularly at instance level and for street scenes. In this paper, we propose to tackle this problem by lifting the semantic instance labeling task from 2D into 3D. Given reconstructions from stereo or laser data, we annotate static 3D scene elements with rough bounding primitives and develop a model which transfers this information into the image domain. We leverage our method to obtain 2D labels for a novel suburban video dataset which we have collected, resulting in 400k semantic and instance image annotations. A comparison of our method to state-of-the-art label transfer baselines reveals that 3D information enables more efficient annotation while at the same time resulting in improved accuracy and time-coherent labels.
Learning Sparse High Dimensional Filters: Image Filtering, Dense CRFs and Bilateral Neural Networks
Nov 25, 2015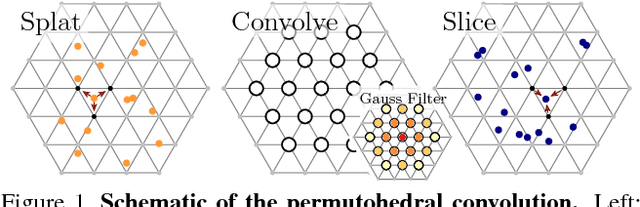


Bilateral filters have wide spread use due to their edge-preserving properties. The common use case is to manually choose a parametric filter type, usually a Gaussian filter. In this paper, we will generalize the parametrization and in particular derive a gradient descent algorithm so the filter parameters can be learned from data. This derivation allows to learn high dimensional linear filters that operate in sparsely populated feature spaces. We build on the permutohedral lattice construction for efficient filtering. The ability to learn more general forms of high-dimensional filters can be used in several diverse applications. First, we demonstrate the use in applications where single filter applications are desired for runtime reasons. Further, we show how this algorithm can be used to learn the pairwise potentials in densely connected conditional random fields and apply these to different image segmentation tasks. Finally, we introduce layers of bilateral filters in CNNs and propose bilateral neural networks for the use of high-dimensional sparse data. This view provides new ways to encode model structure into network architectures. A diverse set of experiments empirically validates the usage of general forms of filters.
Permutohedral Lattice CNNs
May 03, 2015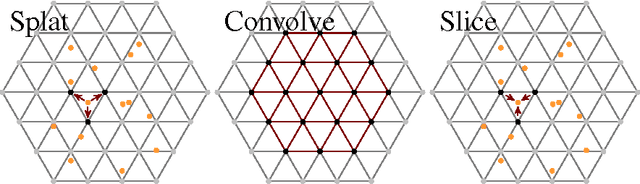

This paper presents a convolutional layer that is able to process sparse input features. As an example, for image recognition problems this allows an efficient filtering of signals that do not lie on a dense grid (like pixel position), but of more general features (such as color values). The presented algorithm makes use of the permutohedral lattice data structure. The permutohedral lattice was introduced to efficiently implement a bilateral filter, a commonly used image processing operation. Its use allows for a generalization of the convolution type found in current (spatial) convolutional network architectures.
Quasi-Newton Methods: A New Direction
Jun 18, 2012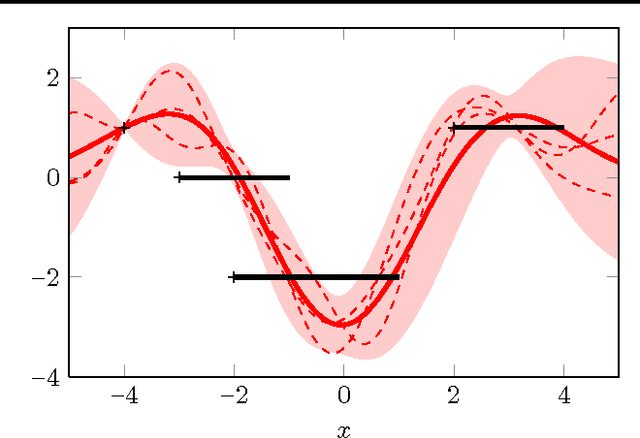
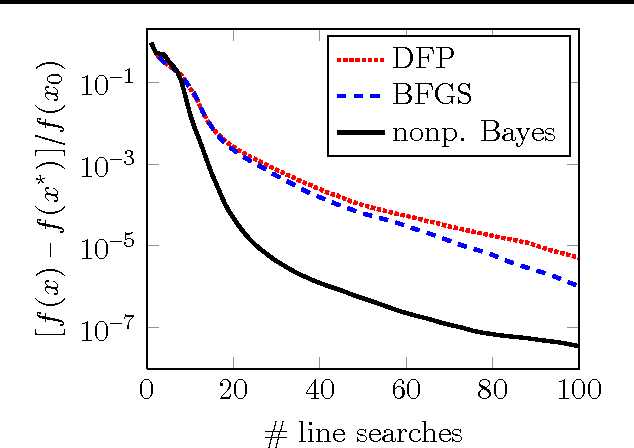
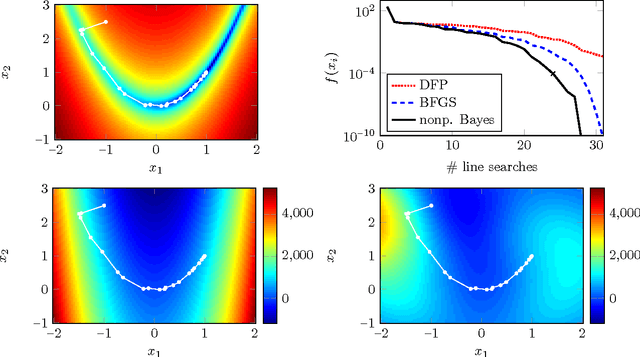
Four decades after their invention, quasi-Newton methods are still state of the art in unconstrained numerical optimization. Although not usually interpreted thus, these are learning algorithms that fit a local quadratic approximation to the objective function. We show that many, including the most popular, quasi-Newton methods can be interpreted as approximations of Bayesian linear regression under varying prior assumptions. This new notion elucidates some shortcomings of classical algorithms, and lights the way to a novel nonparametric quasi-Newton method, which is able to make more efficient use of available information at computational cost similar to its predecessors.