 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextualized Perturbation for Textual Adversarial Attack
Sep 16, 2020
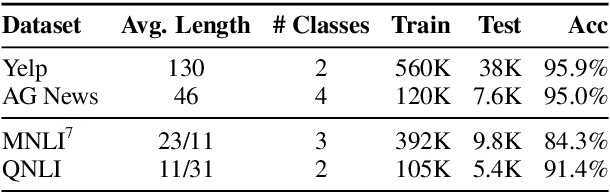
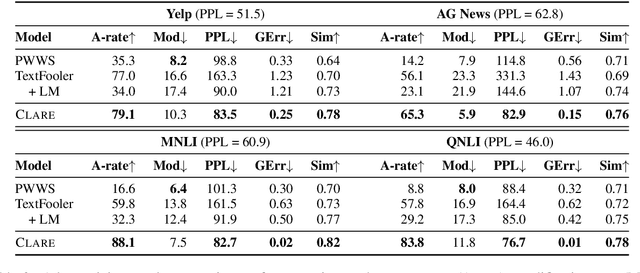
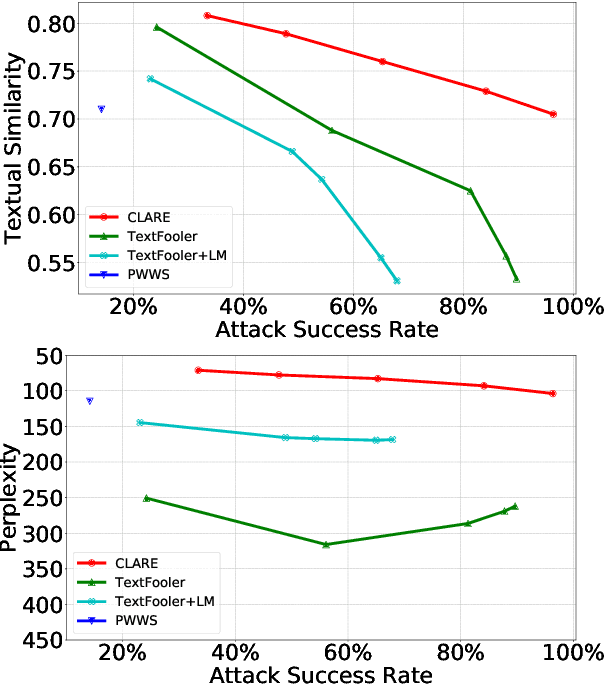
Adversarial examples expose the vulnerabilities of natural language processing (NLP) models, and can be used to evaluate and improve their robustness. Existing techniques of generating such examples are typically driven by local heuristic rules that are agnostic to the context, often resulting in unnatural and ungrammatical outputs. This paper presents CLARE, a ContextuaLized AdversaRial Example generation model that produces fluent and grammatical outputs through a mask-then-infill procedure. CLARE builds on a pre-trained masked language model and modifies the inputs in a context-aware manner. We propose three contextualized perturbations, Replace, Insert and Merge, allowing for generating outputs of varied lengths. With a richer range of available strategies, CLARE is able to attack a victim model more efficiently with fewer edits. Extensive experiments and human evaluation demonstrate that CLARE outperforms the baselines in terms of attack success rate, textual similarity, fluency and grammaticality.
Learning Nonparametric Human Mesh Reconstruction from a Single Image without Ground Truth Meshes
Feb 28, 2020
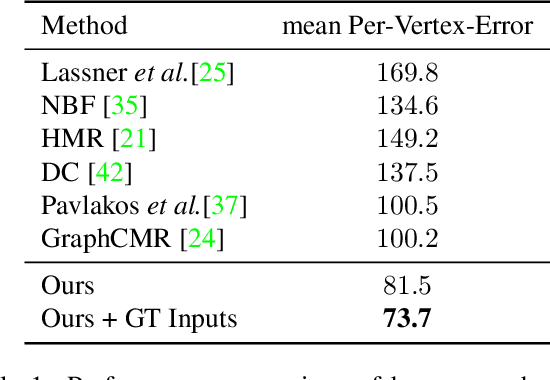
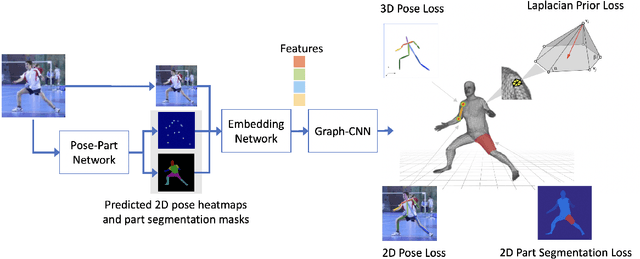

Nonparametric approaches have shown promising results on reconstructing 3D human mesh from a single monocular image. Unlike previous approaches that use a parametric human model like skinned multi-person linear model (SMPL), and attempt to regress the model parameters, nonparametric approaches relax the heavy reliance on the parametric space. However, existing nonparametric methods require ground truth meshes as their regression target for each vertex, and obtaining ground truth mesh labels is very expensive. In this paper, we propose a novel approach to learn human mesh reconstruction without any ground truth meshes. This is made possible by introducing two new terms into the loss function of a graph convolutional neural network (Graph CNN). The first term is the Laplacian prior that acts as a regularizer on the reconstructed mesh. The second term is the part segmentation loss that forces the projected region of the reconstructed mesh to match the part segmentation. Experimental results on multiple public datasets show that without using 3D ground truth meshes, the proposed approach outperforms the previous state-of-the-art approaches that require ground truth meshes for training.
Learning to Generate Multiple Style Transfer Outputs for an Input Sentence
Feb 16, 2020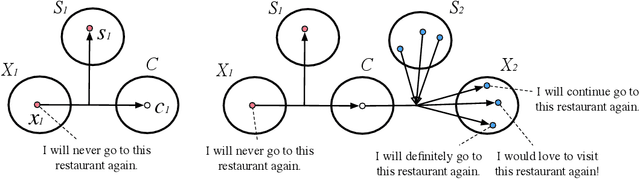
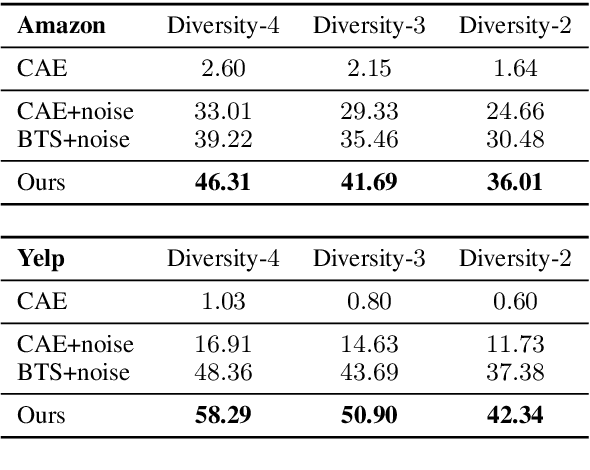
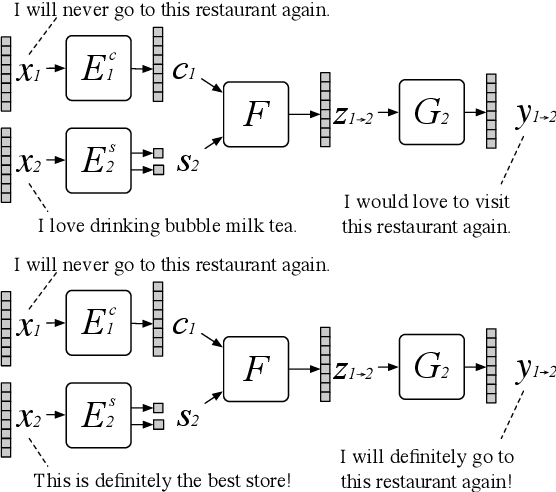
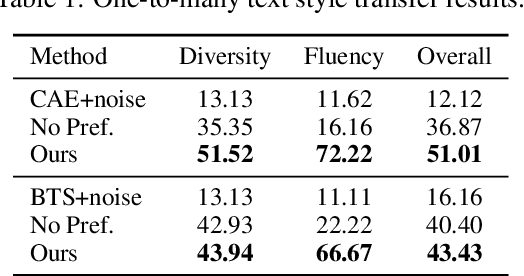
Text style transfer refers to the task of rephrasing a given text in a different style. While various methods have been proposed to advance the state of the art, they often assume the transfer output follows a delta distribution, and thus their models cannot generate different style transfer results for a given input text. To address the limitation, we propose a one-to-many text style transfer framework. In contrast to prior works that learn a one-to-one mapping that converts an input sentence to one output sentence, our approach learns a one-to-many mapping that can convert an input sentence to multiple different output sentences, while preserving the input content. This is achieved by applying adversarial training with a latent decomposition scheme. Specifically, we decompose the latent representation of the input sentence to a style code that captures the language style variation and a content code that encodes the language style-independent content. We then combine the content code with the style code for generating a style transfer output. By combining the same content code with a different style code, we generate a different style transfer output. Extensive experimental results with comparisons to several text style transfer approaches on multiple public datasets using a diverse set of performance metrics validate effectiveness of the proposed approach.
Domain Adaptive Text Style Transfer
Aug 25, 2019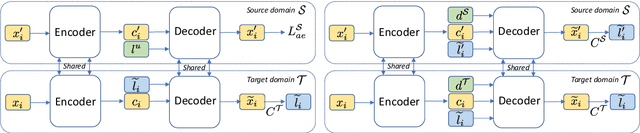
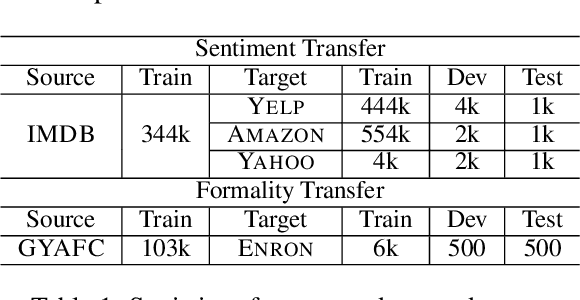
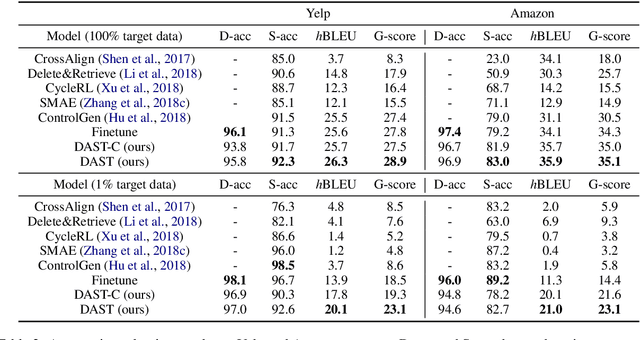
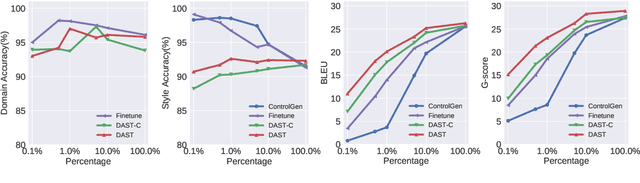
Text style transfer without parallel data has achieved some practical success. However, in the scenario where less data is available, these methods may yield poor performance. In this paper, we examine domain adaptation for text style transfer to leverage massively available data from other domains. These data may demonstrate domain shift, which impedes the benefits of utilizing such data for training. To address this challenge, we propose simple yet effective domain adaptive text style transfer models, enabling domain-adaptive information exchange. The proposed models presumably learn from the source domain to: (i) distinguish stylized information and generic content information; (ii) maximally preserve content information; and (iii) adaptively transfer the styles in a domain-aware manner. We evaluate the proposed models on two style transfer tasks (sentiment and formality) over multiple target domains where only limited non-parallel data is available. Extensive experiments demonstrate the effectiveness of the proposed model compared to the baselines.
Cross-Domain Complementary Learning with Synthetic Data for Multi-Person Part Segmentation
Jul 11, 2019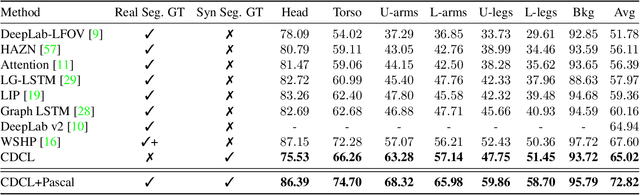


The success of supervised deep learning depends on the training labels. However, data labeling at pixel-level is very expensive, and people have been exploring synthetic data as an alternative. Even though it is easy to generate labels for synthetic data, the quality gap makes it challenging to transfer knowledge from synthetic data to real data. In this paper, we propose a novel technique, called cross-domain complementary learning that takes advantage of the rich variations of real data and the easily obtainable labels of synthetic data to learn multi-person part segmentation on real images without any human-annotated segmentation labels. To make sure the synthetic data and real data are aligned in a common latent space, we use an auxiliary task of human pose estimation to bridge the two domains. Without any real part segmentation training data, our method performs comparably to several supervised state-of-the-art approaches which require real part segmentation training data on Pascal-Person-Parts and COCO-DensePose datasets. We further demonstrate the generalizability of our method on predicting novel keypoints in the wild where no real data labels are available for the novel keypoints.
Adversarial Ranking for Language Generation
Apr 16, 2018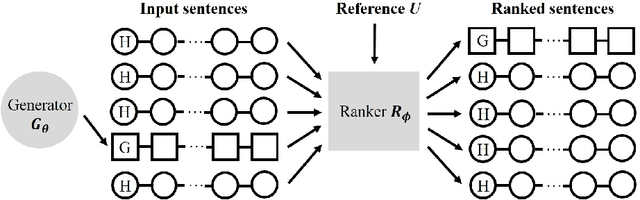
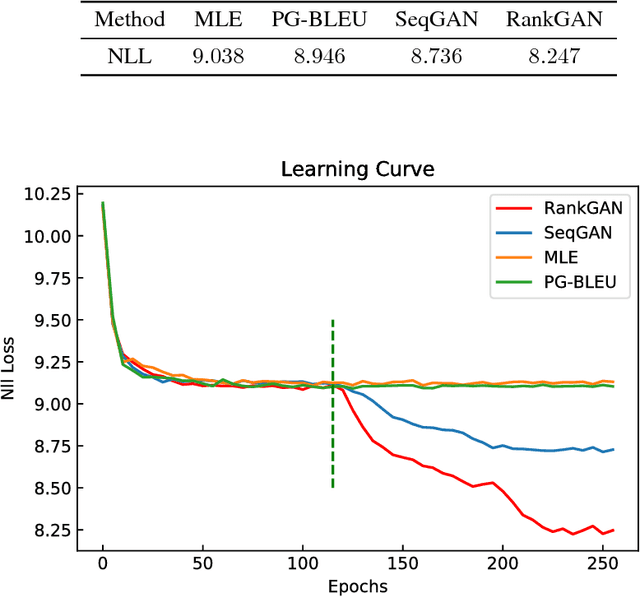


Generative adversarial networks (GANs) have great successes on synthesizing data. However, the existing GANs restrict the discriminator to be a binary classifier, and thus limit their learning capacity for tasks that need to synthesize output with rich structures such as natural language descriptions. In this paper, we propose a novel generative adversarial network, RankGAN, for generating high-quality language descriptions. Rather than training the discriminator to learn and assign absolute binary predicate for individual data sample, the proposed RankGAN is able to analyze and rank a collection of human-written and machine-written sentences by giving a reference group. By viewing a set of data samples collectively and evaluating their quality through relative ranking scores, the discriminator is able to make better assessment which in turn helps to learn a better generator. The proposed RankGAN is optimized through the policy gradient technique. Experimental results on multiple public datasets clearly demonstrate the effectiveness of the proposed approach.
Generating Diverse and Accurate Visual Captions by Comparative Adversarial Learning
Apr 11, 2018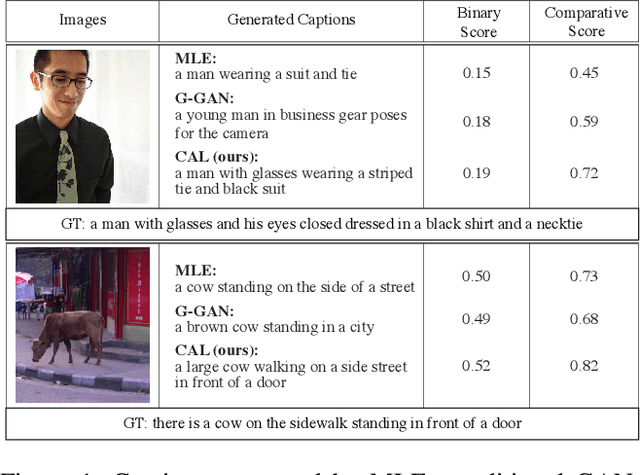
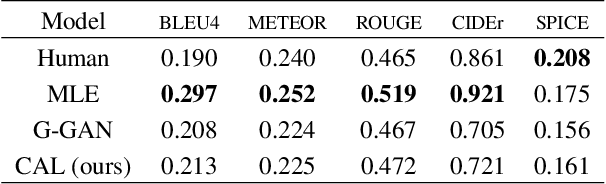
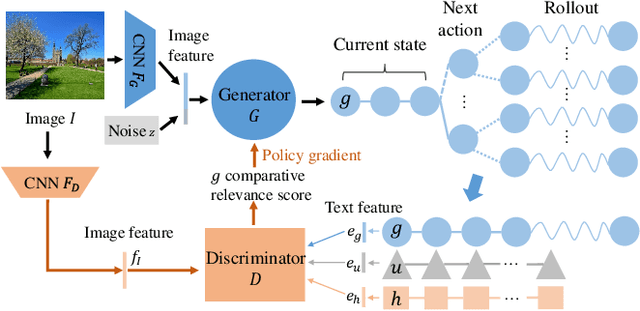
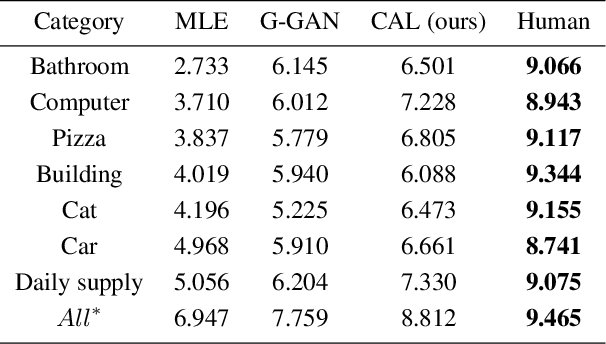
We study how to generate captions that are not only accurate in describing an image but also discriminative across different images. The problem is both fundamental and interesting, as most machine-generated captions, despite phenomenal research progresses in the past several years, are expressed in a very monotonic and featureless format. While such captions are normally accurate, they often lack important characteristics in human languages - distinctiveness for each caption and diversity for different images. To address this problem, we propose a novel conditional generative adversarial network for generating diverse captions across images. Instead of estimating the quality of a caption solely on one image, the proposed comparative adversarial learning framework better assesses the quality of captions by comparing a set of captions within the image-caption joint space. By contrasting with human-written captions and image-mismatched captions, the caption generator effectively exploits the inherent characteristics of human languages, and generates more discriminative captions. We show that our proposed network is capable of producing accurate and diverse captions across images.
Hole Filling with Multiple Reference Views in DIBR View Synthesis
Feb 08, 2018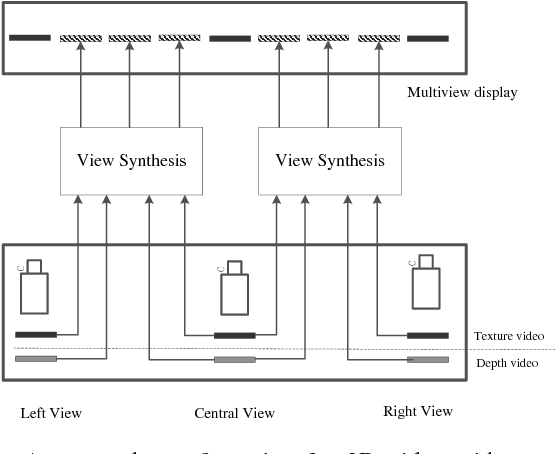
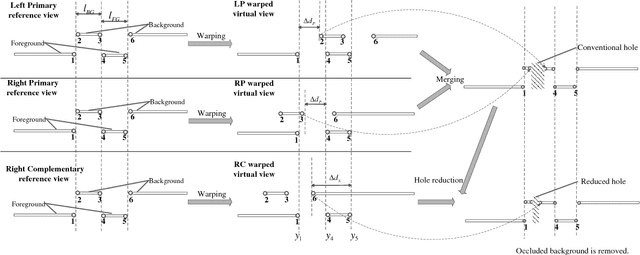
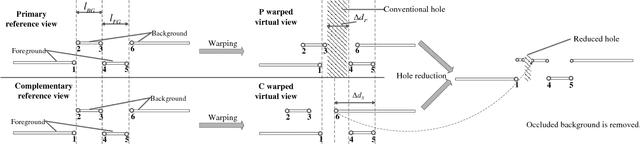
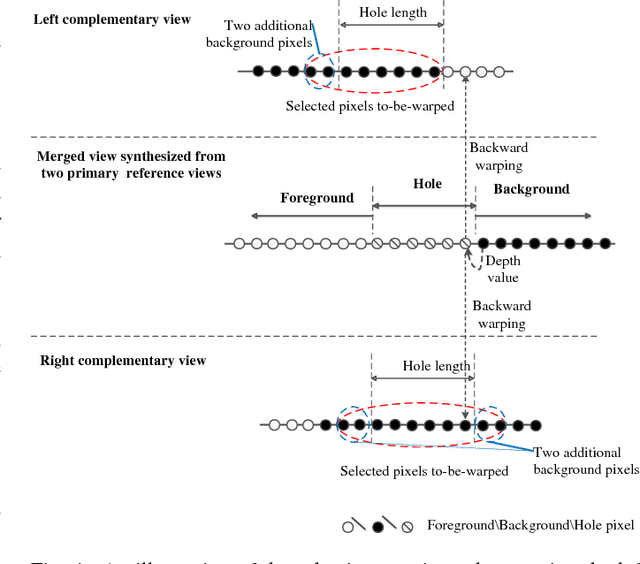
Depth-image-based rendering (DIBR) oriented view synthesis has been widely employed in the current depth-based 3D video systems by synthesizing a virtual view from an arbitrary viewpoint. However, holes may appear in the synthesized view due to disocclusion, thus significantly degrading the quality. Consequently, efforts have been made on developing effective and efficient hole filling algorithms. Current hole filling techniques generally extrapolate/interpolate the hole regions with the neighboring information based on an assumption that the texture pattern in the holes is similar to that of the neighboring background information. However, in many scenarios especially of complex texture, the assumption may not hold. In other words, hole filling techniques can only provide an estimation for a hole which may not be good enough or may even be erroneous considering a wide variety of complex scene of images. In this paper, we first examine the view interpolation with multiple reference views, demonstrating that the problem of emerging holes in a target virtual view can be greatly alleviated by making good use of other neighboring complementary views in addition to its two (commonly used) most neighboring primary views. The effects of using multiple views for view extrapolation in reducing holes are also investigated in this paper. In view of the 3D Video and ongoing free-viewpoint TV standardization, we propose a new view synthesis framework which employs multiple views to synthesize output virtual views. Furthermore, a scheme of selective warping of complementary views is developed by efficiently locating a small number of useful pixels in the complementary views for hole reduction, to avoid a full warping of additional complementary views thus lowering greatly the warping complexity.
Semantic Instance Annotation of Street Scenes by 3D to 2D Label Transfer
Apr 12, 2016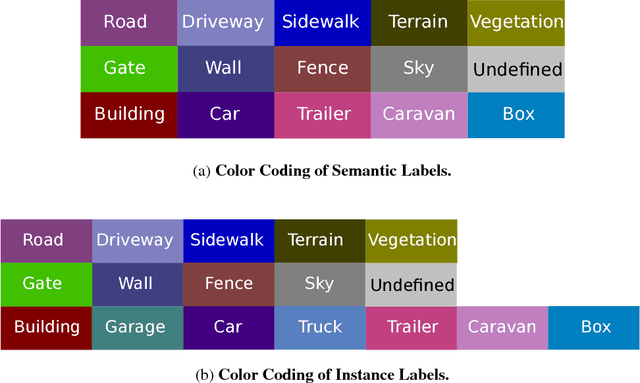

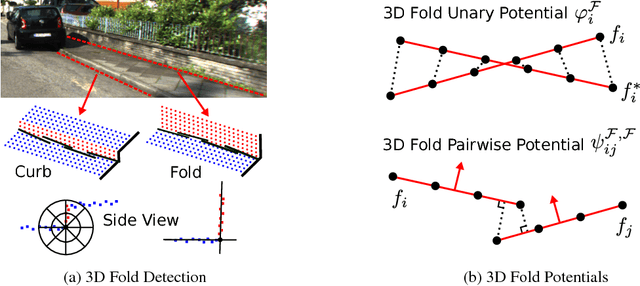
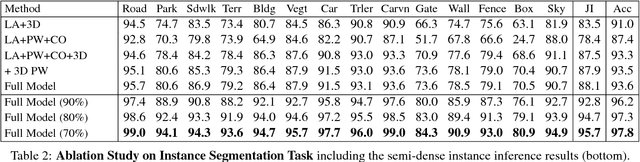
Semantic annotations are vital for training models for object recognition, semantic segmentation or scene understanding. Unfortunately, pixelwise annotation of images at very large scale is labor-intensive and only little labeled data is available, particularly at instance level and for street scenes. In this paper, we propose to tackle this problem by lifting the semantic instance labeling task from 2D into 3D. Given reconstructions from stereo or laser data, we annotate static 3D scene elements with rough bounding primitives and develop a model which transfers this information into the image domain. We leverage our method to obtain 2D labels for a novel suburban video dataset which we have collected, resulting in 400k semantic and instance image annotations. A comparison of our method to state-of-the-art label transfer baselines reveals that 3D information enables more efficient annotation while at the same time resulting in improved accuracy and time-coherent labels.
Macroblock Classification Method for Video Applications Involving Motions
Feb 28, 2015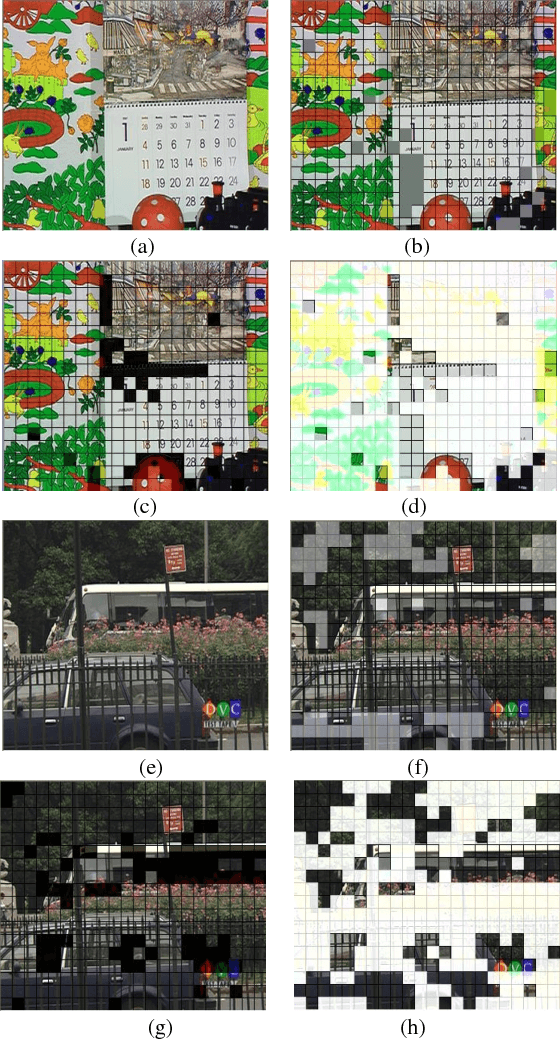
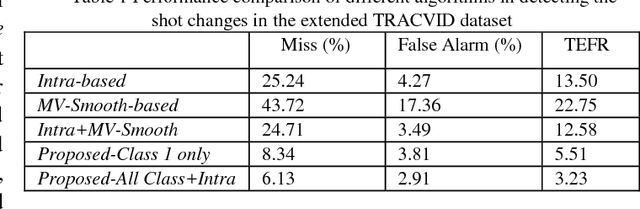
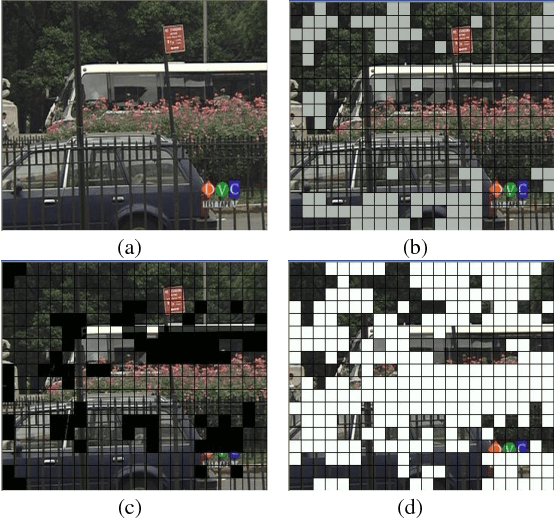
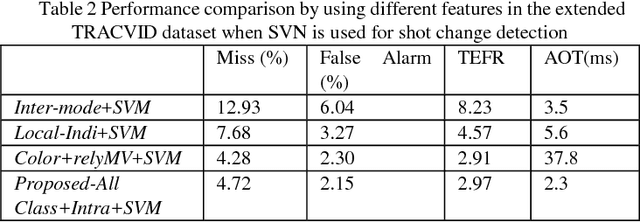
In this paper, a macroblock classification method is proposed for various video processing applications involving motions. Based on the analysis of the Motion Vector field in the compressed video, we propose to classify Macroblocks of each video frame into different classes and use this class information to describe the frame content. We demonstrate that this low-computation-complexity method can efficiently catch the characteristics of the frame. Based on the proposed macroblock classification, we further propose algorithms for different video processing applications, including shot change detection, motion discontinuity detection, and outlier rejection for global motion estimation. Experimental results demonstrate that the methods based on the proposed approach can work effectively on these applications.
* This manuscript is the accepted version for TB (IEEE Transactions on Broadcasting)