 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMergeVQ: A Unified Framework for Visual Generation and Representation with Disentangled Token Merging and Quantization
Apr 01, 2025Masked Image Modeling (MIM) with Vector Quantization (VQ) has achieved great success in both self-supervised pre-training and image generation. However, most existing methods struggle to address the trade-off in shared latent space for generation quality vs. representation learning and efficiency. To push the limits of this paradigm, we propose MergeVQ, which incorporates token merging techniques into VQ-based generative models to bridge the gap between image generation and visual representation learning in a unified architecture. During pre-training, MergeVQ decouples top-k semantics from latent space with the token merge module after self-attention blocks in the encoder for subsequent Look-up Free Quantization (LFQ) and global alignment and recovers their fine-grained details through cross-attention in the decoder for reconstruction. As for the second-stage generation, we introduce MergeAR, which performs KV Cache compression for efficient raster-order prediction. Extensive experiments on ImageNet verify that MergeVQ as an AR generative model achieves competitive performance in both visual representation learning and image generation tasks while maintaining favorable token efficiency and inference speed. The code and model will be available at https://apexgen-x.github.io/MergeVQ.
Self-Taught Agentic Long Context Understanding
Feb 21, 2025Answering complex, long-context questions remains a major challenge for large language models (LLMs) as it requires effective question clarifications and context retrieval. We propose Agentic Long-Context Understanding (AgenticLU), a framework designed to enhance an LLM's understanding of such queries by integrating targeted self-clarification with contextual grounding within an agentic workflow. At the core of AgenticLU is Chain-of-Clarifications (CoC), where models refine their understanding through self-generated clarification questions and corresponding contextual groundings. By scaling inference as a tree search where each node represents a CoC step, we achieve 97.8% answer recall on NarrativeQA with a search depth of up to three and a branching factor of eight. To amortize the high cost of this search process to training, we leverage the preference pairs for each step obtained by the CoC workflow and perform two-stage model finetuning: (1) supervised finetuning to learn effective decomposition strategies, and (2) direct preference optimization to enhance reasoning quality. This enables AgenticLU models to generate clarifications and retrieve relevant context effectively and efficiently in a single inference pass. Extensive experiments across seven long-context tasks demonstrate that AgenticLU significantly outperforms state-of-the-art prompting methods and specialized long-context LLMs, achieving robust multi-hop reasoning while sustaining consistent performance as context length grows.
Life-Code: Central Dogma Modeling with Multi-Omics Sequence Unification
Feb 11, 2025The interactions between DNA, RNA, and proteins are fundamental to biological processes, as illustrated by the central dogma of molecular biology. While modern biological pre-trained models have achieved great success in analyzing these macromolecules individually, their interconnected nature remains under-explored. In this paper, we follow the guidance of the central dogma to redesign both the data and model pipeline and offer a comprehensive framework, Life-Code, that spans different biological functions. As for data flow, we propose a unified pipeline to integrate multi-omics data by reverse-transcribing RNA and reverse-translating amino acids into nucleotide-based sequences. As for the model, we design a codon tokenizer and a hybrid long-sequence architecture to encode the interactions of both coding and non-coding regions with masked modeling pre-training. To model the translation and folding process with coding sequences, Life-Code learns protein structures of the corresponding amino acids by knowledge distillation from off-the-shelf protein language models. Such designs enable Life-Code to capture complex interactions within genetic sequences, providing a more comprehensive understanding of multi-omics with the central dogma. Extensive Experiments show that Life-Code achieves state-of-the-art performance on various tasks across three omics, highlighting its potential for advancing multi-omics analysis and interpretation.
Masked Autoencoders Are Effective Tokenizers for Diffusion Models
Feb 05, 2025Recent advances in latent diffusion models have demonstrated their effectiveness for high-resolution image synthesis. However, the properties of the latent space from tokenizer for better learning and generation of diffusion models remain under-explored. Theoretically and empirically, we find that improved generation quality is closely tied to the latent distributions with better structure, such as the ones with fewer Gaussian Mixture modes and more discriminative features. Motivated by these insights, we propose MAETok, an autoencoder (AE) leveraging mask modeling to learn semantically rich latent space while maintaining reconstruction fidelity. Extensive experiments validate our analysis, demonstrating that the variational form of autoencoders is not necessary, and a discriminative latent space from AE alone enables state-of-the-art performance on ImageNet generation using only 128 tokens. MAETok achieves significant practical improvements, enabling a gFID of 1.69 with 76x faster training and 31x higher inference throughput for 512x512 generation. Our findings show that the structure of the latent space, rather than variational constraints, is crucial for effective diffusion models. Code and trained models are released.
Agent Laboratory: Using LLM Agents as Research Assistants
Jan 08, 2025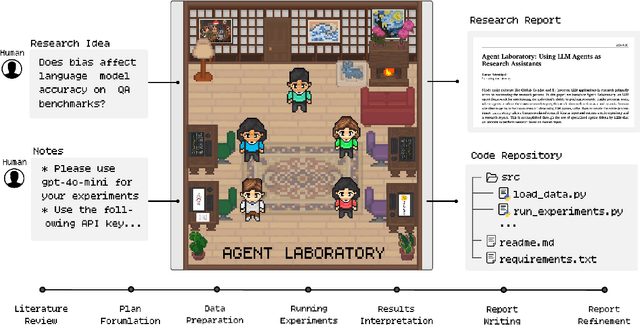



Historically, scientific discovery has been a lengthy and costly process, demanding substantial time and resources from initial conception to final results. To accelerate scientific discovery, reduce research costs, and improve research quality, we introduce Agent Laboratory, an autonomous LLM-based framework capable of completing the entire research process. This framework accepts a human-provided research idea and progresses through three stages--literature review, experimentation, and report writing to produce comprehensive research outputs, including a code repository and a research report, while enabling users to provide feedback and guidance at each stage. We deploy Agent Laboratory with various state-of-the-art LLMs and invite multiple researchers to assess its quality by participating in a survey, providing human feedback to guide the research process, and then evaluate the final paper. We found that: (1) Agent Laboratory driven by o1-preview generates the best research outcomes; (2) The generated machine learning code is able to achieve state-of-the-art performance compared to existing methods; (3) Human involvement, providing feedback at each stage, significantly improves the overall quality of research; (4) Agent Laboratory significantly reduces research expenses, achieving an 84% decrease compared to previous autonomous research methods. We hope Agent Laboratory enables researchers to allocate more effort toward creative ideation rather than low-level coding and writing, ultimately accelerating scientific discovery.
SoftVQ-VAE: Efficient 1-Dimensional Continuous Tokenizer
Dec 14, 2024



Efficient image tokenization with high compression ratios remains a critical challenge for training generative models. We present SoftVQ-VAE, a continuous image tokenizer that leverages soft categorical posteriors to aggregate multiple codewords into each latent token, substantially increasing the representation capacity of the latent space. When applied to Transformer-based architectures, our approach compresses 256x256 and 512x512 images using as few as 32 or 64 1-dimensional tokens. Not only does SoftVQ-VAE show consistent and high-quality reconstruction, more importantly, it also achieves state-of-the-art and significantly faster image generation results across different denoising-based generative models. Remarkably, SoftVQ-VAE improves inference throughput by up to 18x for generating 256x256 images and 55x for 512x512 images while achieving competitive FID scores of 1.78 and 2.21 for SiT-XL. It also improves the training efficiency of the generative models by reducing the number of training iterations by 2.3x while maintaining comparable performance. With its fully-differentiable design and semantic-rich latent space, our experiment demonstrates that SoftVQ-VQE achieves efficient tokenization without compromising generation quality, paving the way for more efficient generative models. Code and model are released.
B-VLLM: A Vision Large Language Model with Balanced Spatio-Temporal Tokens
Dec 13, 2024



Recently, Vision Large Language Models (VLLMs) integrated with vision encoders have shown promising performance in vision understanding. The key of VLLMs is to encode visual content into sequences of visual tokens, enabling VLLMs to simultaneously process both visual and textual content. However, understanding videos, especially long videos, remain a challenge to VLLMs as the number of visual tokens grows rapidly when encoding videos, resulting in the risk of exceeding the context window of VLLMs and introducing heavy computation burden. To restrict the number of visual tokens, existing VLLMs either: (1) uniformly downsample videos into a fixed number of frames or (2) reducing the number of visual tokens encoded from each frame. We argue the former solution neglects the rich temporal cue in videos and the later overlooks the spatial details in each frame. In this work, we present Balanced-VLLM (B-VLLM): a novel VLLM framework that aims to effectively leverage task relevant spatio-temporal cues while restricting the number of visual tokens under the VLLM context window length. At the core of our method, we devise a text-conditioned adaptive frame selection module to identify frames relevant to the visual understanding task. The selected frames are then de-duplicated using a temporal frame token merging technique. The visual tokens of the selected frames are processed through a spatial token sampling module and an optional spatial token merging strategy to achieve precise control over the token count. Experimental results show that B-VLLM is effective in balancing the number of frames and visual tokens in video understanding, yielding superior performance on various video understanding benchmarks. Our code is available at https://github.com/zhuqiangLu/B-VLLM.
Conditional Text-to-Image Generation with Reference Guidance
Nov 22, 2024Text-to-image diffusion models have demonstrated tremendous success in synthesizing visually stunning images given textual instructions. Despite remarkable progress in creating high-fidelity visuals, text-to-image models can still struggle with precisely rendering subjects, such as text spelling. To address this challenge, this paper explores using additional conditions of an image that provides visual guidance of the particular subjects for diffusion models to generate. In addition, this reference condition empowers the model to be conditioned in ways that the vocabularies of the text tokenizer cannot adequately represent, and further extends the model's generalization to novel capabilities such as generating non-English text spellings. We develop several small-scale expert plugins that efficiently endow a Stable Diffusion model with the capability to take different references. Each plugin is trained with auxiliary networks and loss functions customized for applications such as English scene-text generation, multi-lingual scene-text generation, and logo-image generation. Our expert plugins demonstrate superior results than the existing methods on all tasks, each containing only 28.55M trainable parameters.
Unveiling the Backbone-Optimizer Coupling Bias in Visual Representation Learning
Oct 08, 2024



This paper delves into the interplay between vision backbones and optimizers, unvealing an inter-dependent phenomenon termed \textit{\textbf{b}ackbone-\textbf{o}ptimizer \textbf{c}oupling \textbf{b}ias} (BOCB). We observe that canonical CNNs, such as VGG and ResNet, exhibit a marked co-dependency with SGD families, while recent architectures like ViTs and ConvNeXt share a tight coupling with the adaptive learning rate ones. We further show that BOCB can be introduced by both optimizers and certain backbone designs and may significantly impact the pre-training and downstream fine-tuning of vision models. Through in-depth empirical analysis, we summarize takeaways on recommended optimizers and insights into robust vision backbone architectures. We hope this work can inspire the community to question long-held assumptions on backbones and optimizers, stimulate further explorations, and thereby contribute to more robust vision systems. The source code and models are publicly available at https://bocb-ai.github.io/.
Tuning Timestep-Distilled Diffusion Model Using Pairwise Sample Optimization
Oct 04, 2024



Recent advancements in timestep-distilled diffusion models have enabled high-quality image generation that rivals non-distilled multi-step models, but with significantly fewer inference steps. While such models are attractive for applications due to the low inference cost and latency, fine-tuning them with a naive diffusion objective would result in degraded and blurry outputs. An intuitive alternative is to repeat the diffusion distillation process with a fine-tuned teacher model, which produces good results but is cumbersome and computationally intensive; the distillation training usually requires magnitude higher of training compute compared to fine-tuning for specific image styles. In this paper, we present an algorithm named pairwise sample optimization (PSO), which enables the direct fine-tuning of an arbitrary timestep-distilled diffusion model. PSO introduces additional reference images sampled from the current time-step distilled model, and increases the relative likelihood margin between the training images and reference images. This enables the model to retain its few-step generation ability, while allowing for fine-tuning of its output distribution. We also demonstrate that PSO is a generalized formulation which can be flexibly extended to both offline-sampled and online-sampled pairwise data, covering various popular objectives for diffusion model preference optimization. We evaluate PSO in both preference optimization and other fine-tuning tasks, including style transfer and concept customization. We show that PSO can directly adapt distilled models to human-preferred generation with both offline and online-generated pairwise preference image data. PSO also demonstrates effectiveness in style transfer and concept customization by directly tuning timestep-distilled diffusion models.