 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgenticLab: A Real-World Robot Agent Platform that Can See, Think, and Act
Feb 02, 2026Recent advances in large vision-language models (VLMs) have demonstrated generalizable open-vocabulary perception and reasoning, yet their real-robot manipulation capability remains unclear for long-horizon, closed-loop execution in unstructured, in-the-wild environments. Prior VLM-based manipulation pipelines are difficult to compare across different research groups' setups, and many evaluations rely on simulation, privileged state, or specially designed setups. We present AgenticLab, a model-agnostic robot agent platform and benchmark for open-world manipulation. AgenticLab provides a closed-loop agent pipeline for perception, task decomposition, online verification, and replanning. Using AgenticLab, we benchmark state-of-the-art VLM-based agents on real-robot tasks in unstructured environments. Our benchmark reveals several failure modes that offline vision-language tests (e.g., VQA and static image understanding) fail to capture, including breakdowns in multi-step grounding consistency, object grounding under occlusion and scene changes, and insufficient spatial reasoning for reliable manipulation. We will release the full hardware and software stack to support reproducible evaluation and accelerate research on general-purpose robot agents.
TALENT: Table VQA via Augmented Language-Enhanced Natural-text Transcription
Oct 08, 2025Table Visual Question Answering (Table VQA) is typically addressed by large vision-language models (VLMs). While such models can answer directly from images, they often miss fine-grained details unless scaled to very large sizes, which are computationally prohibitive, especially for mobile deployment. A lighter alternative is to have a small VLM perform OCR and then use a large language model (LLM) to reason over structured outputs such as Markdown tables. However, these representations are not naturally optimized for LLMs and still introduce substantial errors. We propose TALENT (Table VQA via Augmented Language-Enhanced Natural-text Transcription), a lightweight framework that leverages dual representations of tables. TALENT prompts a small VLM to produce both OCR text and natural language narration, then combines them with the question for reasoning by an LLM. This reframes Table VQA as an LLM-centric multimodal reasoning task, where the VLM serves as a perception-narration module rather than a monolithic solver. Additionally, we construct ReTabVQA, a more challenging Table VQA dataset requiring multi-step quantitative reasoning over table images. Experiments show that TALENT enables a small VLM-LLM combination to match or surpass a single large VLM at significantly lower computational cost on both public datasets and ReTabVQA.
DiffOG: Differentiable Policy Trajectory Optimization with Generalizability
Apr 18, 2025Imitation learning-based visuomotor policies excel at manipulation tasks but often produce suboptimal action trajectories compared to model-based methods. Directly mapping camera data to actions via neural networks can result in jerky motions and difficulties in meeting critical constraints, compromising safety and robustness in real-world deployment. For tasks that require high robustness or strict adherence to constraints, ensuring trajectory quality is crucial. However, the lack of interpretability in neural networks makes it challenging to generate constraint-compliant actions in a controlled manner. This paper introduces differentiable policy trajectory optimization with generalizability (DiffOG), a learning-based trajectory optimization framework designed to enhance visuomotor policies. By leveraging the proposed differentiable formulation of trajectory optimization with transformer, DiffOG seamlessly integrates policies with a generalizable optimization layer. Visuomotor policies enhanced by DiffOG generate smoother, constraint-compliant action trajectories in a more interpretable way. DiffOG exhibits strong generalization capabilities and high flexibility. We evaluated DiffOG across 11 simulated tasks and 2 real-world tasks. The results demonstrate that DiffOG significantly enhances the trajectory quality of visuomotor policies while having minimal impact on policy performance, outperforming trajectory processing baselines such as greedy constraint clipping and penalty-based trajectory optimization. Furthermore, DiffOG achieves superior performance compared to existing constrained visuomotor policy.
Tuning Timestep-Distilled Diffusion Model Using Pairwise Sample Optimization
Oct 04, 2024



Recent advancements in timestep-distilled diffusion models have enabled high-quality image generation that rivals non-distilled multi-step models, but with significantly fewer inference steps. While such models are attractive for applications due to the low inference cost and latency, fine-tuning them with a naive diffusion objective would result in degraded and blurry outputs. An intuitive alternative is to repeat the diffusion distillation process with a fine-tuned teacher model, which produces good results but is cumbersome and computationally intensive; the distillation training usually requires magnitude higher of training compute compared to fine-tuning for specific image styles. In this paper, we present an algorithm named pairwise sample optimization (PSO), which enables the direct fine-tuning of an arbitrary timestep-distilled diffusion model. PSO introduces additional reference images sampled from the current time-step distilled model, and increases the relative likelihood margin between the training images and reference images. This enables the model to retain its few-step generation ability, while allowing for fine-tuning of its output distribution. We also demonstrate that PSO is a generalized formulation which can be flexibly extended to both offline-sampled and online-sampled pairwise data, covering various popular objectives for diffusion model preference optimization. We evaluate PSO in both preference optimization and other fine-tuning tasks, including style transfer and concept customization. We show that PSO can directly adapt distilled models to human-preferred generation with both offline and online-generated pairwise preference image data. PSO also demonstrates effectiveness in style transfer and concept customization by directly tuning timestep-distilled diffusion models.
Large Convolutional Model Tuning via Filter Subspace
Mar 11, 2024



Efficient fine-tuning methods are critical to address the high computational and parameter complexity while adapting large pre-trained models to downstream tasks. Our study is inspired by prior research that represents each convolution filter as a linear combination of a small set of filter subspace elements, referred to as filter atoms. In this paper, we propose to fine-tune pre-trained models by adjusting only filter atoms, which are responsible for spatial-only convolution, while preserving spatially-invariant channel combination knowledge in atom coefficients. In this way, we bring a new filter subspace view for model tuning. Furthermore, each filter atom can be recursively decomposed as a combination of another set of atoms, which naturally expands the number of tunable parameters in the filter subspace. By only adapting filter atoms constructed by a small number of parameters, while maintaining the rest of model parameters constant, the proposed approach is highly parameter-efficient. It effectively preserves the capabilities of pre-trained models and prevents overfitting to downstream tasks. Extensive experiments show that such a simple scheme surpasses previous tuning baselines for both discriminate and generative tasks.
Training Bayesian Neural Networks with Sparse Subspace Variational Inference
Feb 16, 2024



Bayesian neural networks (BNNs) offer uncertainty quantification but come with the downside of substantially increased training and inference costs. Sparse BNNs have been investigated for efficient inference, typically by either slowly introducing sparsity throughout the training or by post-training compression of dense BNNs. The dilemma of how to cut down massive training costs remains, particularly given the requirement to learn about the uncertainty. To solve this challenge, we introduce Sparse Subspace Variational Inference (SSVI), the first fully sparse BNN framework that maintains a consistently highly sparse Bayesian model throughout the training and inference phases. Starting from a randomly initialized low-dimensional sparse subspace, our approach alternately optimizes the sparse subspace basis selection and its associated parameters. While basis selection is characterized as a non-differentiable problem, we approximate the optimal solution with a removal-and-addition strategy, guided by novel criteria based on weight distribution statistics. Our extensive experiments show that SSVI sets new benchmarks in crafting sparse BNNs, achieving, for instance, a 10-20x compression in model size with under 3\% performance drop, and up to 20x FLOPs reduction during training compared with dense VI training. Remarkably, SSVI also demonstrates enhanced robustness to hyperparameters, reducing the need for intricate tuning in VI and occasionally even surpassing VI-trained dense BNNs on both accuracy and uncertainty metrics.
Adaptive Convolutions with Per-pixel Dynamic Filter Atom
Aug 17, 2021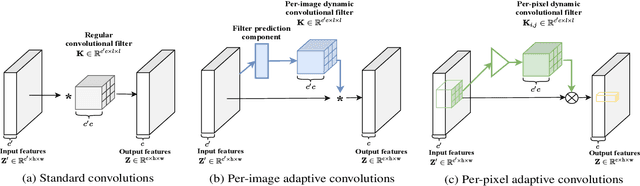

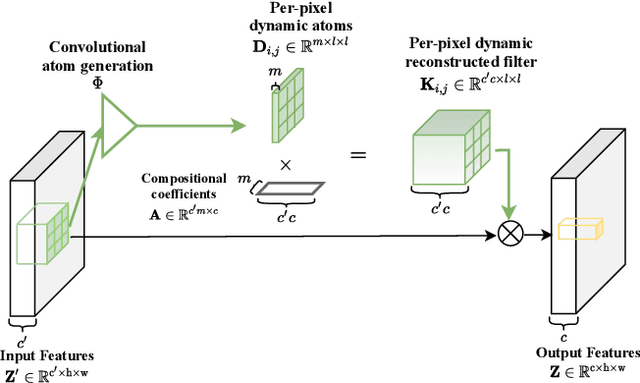

Applying feature dependent network weights have been proved to be effective in many fields. However, in practice, restricted by the enormous size of model parameters and memory footprints, scalable and versatile dynamic convolutions with per-pixel adapted filters are yet to be fully explored. In this paper, we address this challenge by decomposing filters, adapted to each spatial position, over dynamic filter atoms generated by a light-weight network from local features. Adaptive receptive fields can be supported by further representing each filter atom over sets of pre-fixed multi-scale bases. As plug-and-play replacements to convolutional layers, the introduced adaptive convolutions with per-pixel dynamic atoms enable explicit modeling of intra-image variance, while avoiding heavy computation, parameters, and memory cost. Our method preserves the appealing properties of conventional convolutions as being translation-equivariant and parametrically efficient. We present experiments to show that, the proposed method delivers comparable or even better performance across tasks, and are particularly effective on handling tasks with significant intra-image variance.
Graph Neural Networks with Low-rank Learnable Local Filters
Aug 04, 2020
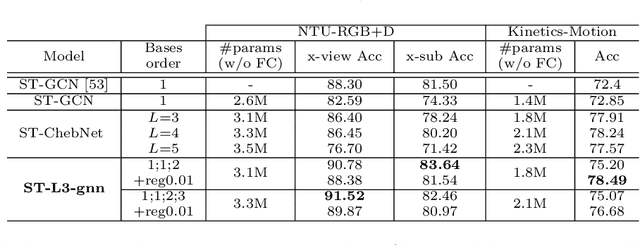

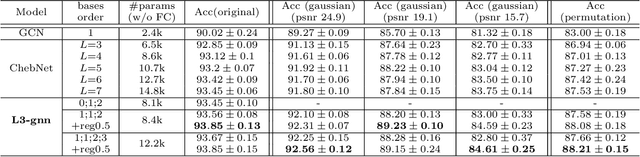
For the classification of graph data consisting of features sampled on an irregular coarse mesh like landmark points on face and human body, graph neural network (gnn) models based on global graph Laplacians may lack expressiveness to capture local features on graph. The current paper introduces a new gnn layer type with learnable low-rank local graph filters, which significantly reduces the complexity of traditional locally connected gnn. The architecture provides a unified framework for both spectral and spatial convolutional gnn constructions. The new gnn layer is provably more expressive than gnn based on global graph Laplacians, and to improve model robustness, regularization by local graph Laplacians is introduced. The representation stability against input graph data perturbation is theoretically proved, making use of the graph filter locality and the local graph regularization. Experiments on spherical mesh data, real-world facial expression recognition/skeleton-based action recognition data, and data with simulated graph noise show the empirical advantage of the proposed model.
AED-Net: An Abnormal Event Detection Network
Mar 28, 2019
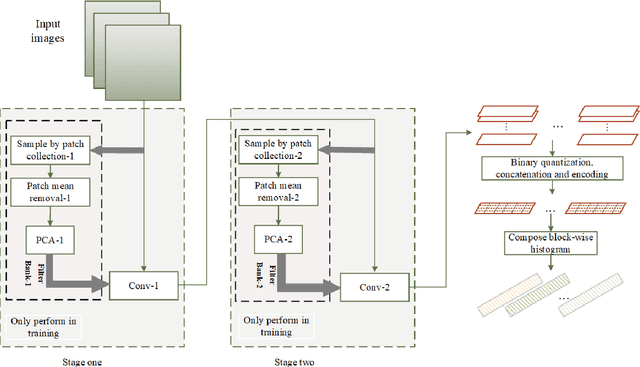
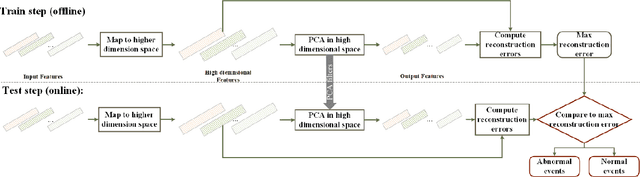
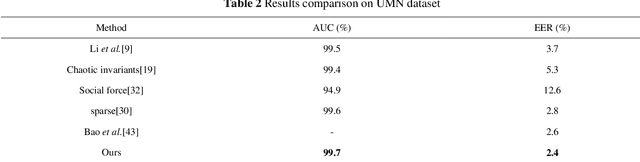
It is challenging to detect the anomaly in crowded scenes for quite a long time. In this paper, a self-supervised framework, abnormal event detection network (AED-Net), which is composed of PCAnet and kernel principal component analysis (kPCA), is proposed to address this problem. Using surveillance video sequences of different scenes as raw data, PCAnet is trained to extract high-level semantics of crowd's situation. Next, kPCA,a one-class classifier, is trained to determine anomaly of the scene. In contrast to some prevailing deep learning methods,the framework is completely self-supervised because it utilizes only video sequences in a normal situation. Experiments of global and local abnormal event detection are carried out on UMN and UCSD datasets, and competitive results with higher EER and AUC compared to other state-of-the-art methods are observed. Furthermore, by adding local response normalization (LRN) layer, we propose an improvement to original AED-Net. And it is proved to perform better by promoting the framework's generalization capacity according to the experiments.
* 14 pages, 7 figures