 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models to Enhance Multi-task Drone Operations in Simulated Environments
Jan 13, 2026Benefiting from the rapid advancements in large language models (LLMs), human-drone interaction has reached unprecedented opportunities. In this paper, we propose a method that integrates a fine-tuned CodeT5 model with the Unreal Engine-based AirSim drone simulator to efficiently execute multi-task operations using natural language commands. This approach enables users to interact with simulated drones through prompts or command descriptions, allowing them to easily access and control the drone's status, significantly lowering the operational threshold. In the AirSim simulator, we can flexibly construct visually realistic dynamic environments to simulate drone applications in complex scenarios. By combining a large dataset of (natural language, program code) command-execution pairs generated by ChatGPT with developer-written drone code as training data, we fine-tune the CodeT5 to achieve automated translation from natural language to executable code for drone tasks. Experimental results demonstrate that the proposed method exhibits superior task execution efficiency and command understanding capabilities in simulated environments. In the future, we plan to extend the model functionality in a modular manner, enhancing its adaptability to complex scenarios and driving the application of drone technologies in real-world environments.
Edge-Optimized Multimodal Learning for UAV Video Understanding via BLIP-2
Jan 13, 2026The demand for real-time visual understanding and interaction in complex scenarios is increasingly critical for unmanned aerial vehicles. However, a significant challenge arises from the contradiction between the high computational cost of large Vision language models and the limited computing resources available on UAV edge devices. To address this challenge, this paper proposes a lightweight multimodal task platform based on BLIP-2, integrated with YOLO-World and YOLOv8-Seg models. This integration extends the multi-task capabilities of BLIP-2 for UAV applications with minimal adaptation and without requiring task-specific fine-tuning on drone data. Firstly, the deep integration of BLIP-2 with YOLO models enables it to leverage the precise perceptual results of YOLO for fundamental tasks like object detection and instance segmentation, thereby facilitating deeper visual-attention understanding and reasoning. Secondly, a content-aware key frame sampling mechanism based on K-Means clustering is designed, which incorporates intelligent frame selection and temporal feature concatenation. This equips the lightweight BLIP-2 architecture with the capability to handle video-level interactive tasks effectively. Thirdly, a unified prompt optimization scheme for multi-task adaptation is implemented. This scheme strategically injects structured event logs from the YOLO models as contextual information into BLIP-2's input. Combined with output constraints designed to filter out technical details, this approach effectively guides the model to generate accurate and contextually relevant outputs for various tasks.
Hybrid Distillation with CoT Guidance for Edge-Drone Control Code Generation
Jan 13, 2026With large language models demonstrating significant potential in code generation tasks, their application to onboard control of resource-constrained Unmanned Aerial Vehicles has emerged as an important research direction. However, a notable contradiction exists between the high resource consumption of large models and the real-time, lightweight requirements of UAV platforms. This paper proposes an integrated approach that combines knowledge distillation, chain-of-thought guidance, and supervised fine-tuning for UAV multi-SDK control tasks, aiming to efficiently transfer complex reasoning and code generation capabilities to smaller models. Firstly, a high-quality dataset covering various mainstream UAV SDKs is constructed, featuring instruction-code-reasoning chains, and incorporates counterfactual negative samples for data augmentation, guiding the model to learn the end-to-end logic from instruction parsing to code generation. Secondly, leveraging DeepSeek-Coder-V2-Lite quantized via QLoRA as the teacher model, and based on a hybrid black-box and white-box distillation strategy, high-quality chain-of-thought soft labels are generated. These are combined with a weighted cross-entropy loss using hard labels to transfer complex reasoning capabilities to the smaller student model. Finally, through prompt tuning engineering optimized for the UAV control scenario, the model performance on core tasks such as SDK type recognition and function call matching is enhanced. Experimental results indicate that the distilled lightweight model maintains high code generation accuracy while achieving significant improvements in deployment and inference efficiency, effectively demonstrating the feasibility and superiority of our approach in achieving precise and lightweight intelligent control for UAVs
Vision-Language Model for Accurate Crater Detection
Jan 12, 2026The European Space Agency (ESA), driven by its ambitions on planned lunar missions with the Argonaut lander, has a profound interest in reliable crater detection, since craters pose a risk to safe lunar landings. This task is usually addressed with automated crater detection algorithms (CDA) based on deep learning techniques. It is non-trivial due to the vast amount of craters of various sizes and shapes, as well as challenging conditions such as varying illumination and rugged terrain. Therefore, we propose a deep-learning CDA based on the OWLv2 model, which is built on a Vision Transformer, that has proven highly effective in various computer vision tasks. For fine-tuning, we utilize a manually labeled dataset fom the IMPACT project, that provides crater annotations on high-resolution Lunar Reconnaissance Orbiter Camera Calibrated Data Record images. We insert trainable parameters using a parameter-efficient fine-tuning strategy with Low-Rank Adaptation, and optimize a combined loss function consisting of Complete Intersection over Union (CIoU) for localization and a contrastive loss for classification. We achieve satisfactory visual results, along with a maximum recall of 94.0% and a maximum precision of 73.1% on a test dataset from IMPACT. Our method achieves reliable crater detection across challenging lunar imaging conditions, paving the way for robust crater analysis in future lunar exploration.
Detector-Augmented SAMURAI for Long-Duration Drone Tracking
Jan 08, 2026Robust long-term tracking of drone is a critical requirement for modern surveillance systems, given their increasing threat potential. While detector-based approaches typically achieve strong frame-level accuracy, they often suffer from temporal inconsistencies caused by frequent detection dropouts. Despite its practical relevance, research on RGB-based drone tracking is still limited and largely reliant on conventional motion models. Meanwhile, foundation models like SAMURAI have established their effectiveness across other domains, exhibiting strong category-agnostic tracking performance. However, their applicability in drone-specific scenarios has not been investigated yet. Motivated by this gap, we present the first systematic evaluation of SAMURAI's potential for robust drone tracking in urban surveillance settings. Furthermore, we introduce a detector-augmented extension of SAMURAI to mitigate sensitivity to bounding-box initialization and sequence length. Our findings demonstrate that the proposed extension significantly improves robustness in complex urban environments, with pronounced benefits in long-duration sequences - especially under drone exit-re-entry events. The incorporation of detector cues yields consistent gains over SAMURAI's zero-shot performance across datasets and metrics, with success rate improvements of up to +0.393 and FNR reductions of up to -0.475.
CSE: Surface Anomaly Detection with Contrastively Selected Embedding
Mar 04, 2024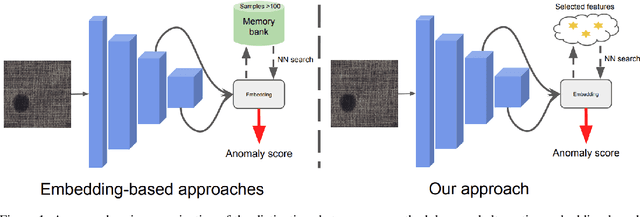



Detecting surface anomalies of industrial materials poses a significant challenge within a myriad of industrial manufacturing processes. In recent times, various methodologies have emerged, capitalizing on the advantages of employing a network pre-trained on natural images for the extraction of representative features. Subsequently, these features are subjected to processing through a diverse range of techniques including memory banks, normalizing flow, and knowledge distillation, which have exhibited exceptional accuracy. This paper revisits approaches based on pre-trained features by introducing a novel method centered on target-specific embedding. To capture the most representative features of the texture under consideration, we employ a variant of a contrastive training procedure that incorporates both artificially generated defective samples and anomaly-free samples during training. Exploiting the intrinsic properties of surfaces, we derived a meaningful representation from the defect-free samples during training, facilitating a straightforward yet effective calculation of anomaly scores. The experiments conducted on the MVTEC AD and TILDA datasets demonstrate the competitiveness of our approach compared to state-of-the-art methods.
Distillation-based fabric anomaly detection
Jan 04, 2024Unsupervised texture anomaly detection has been a concerning topic in a vast amount of industrial processes. Patterned textures inspection, particularly in the context of fabric defect detection, is indeed a widely encountered use case. This task involves handling a diverse spectrum of colors and textile types, encompassing a wide range of fabrics. Given the extensive variability in colors, textures, and defect types, fabric defect detection poses a complex and challenging problem in the field of patterned textures inspection. In this article, we propose a knowledge distillation-based approach tailored specifically for addressing the challenge of unsupervised anomaly detection in textures resembling fabrics. Our method aims to redefine the recently introduced reverse distillation approach, which advocates for an encoder-decoder design to mitigate classifier bias and to prevent the student from reconstructing anomalies. In this study, we present a new reverse distillation technique for the specific task of fabric defect detection. Our approach involves a meticulous design selection that strategically highlights high-level features. To demonstrate the capabilities of our approach both in terms of performance and inference speed, we conducted a series of experiments on multiple texture datasets, including MVTEC AD, AITEX, and TILDA, alongside conducting experiments on a dataset acquired from a textile manufacturing facility. The main contributions of this paper are the following: a robust texture anomaly detector utilizing a reverse knowledge-distillation technique suitable for both anomaly detection and domain generalization and a novel dataset encompassing a diverse range of fabrics and defects.
MixedTeacher : Knowledge Distillation for fast inference textural anomaly detection
Jun 16, 2023



For a very long time, unsupervised learning for anomaly detection has been at the heart of image processing research and a stepping stone for high performance industrial automation process. With the emergence of CNN, several methods have been proposed such as Autoencoders, GAN, deep feature extraction, etc. In this paper, we propose a new method based on the promising concept of knowledge distillation which consists of training a network (the student) on normal samples while considering the output of a larger pretrained network (the teacher). The main contributions of this paper are twofold: First, a reduced student architecture with optimal layer selection is proposed, then a new Student-Teacher architecture with network bias reduction combining two teachers is proposed in order to jointly enhance the performance of anomaly detection and its localization accuracy. The proposed texture anomaly detector has an outstanding capability to detect defects in any texture and a fast inference time compared to the SOTA methods.
FABLE : Fabric Anomaly Detection Automation Process
Jun 16, 2023Unsupervised anomaly in industry has been a concerning topic and a stepping stone for high performance industrial automation process. The vast majority of industry-oriented methods focus on learning from good samples to detect anomaly notwithstanding some specific industrial scenario requiring even less specific training and therefore a generalization for anomaly detection. The obvious use case is the fabric anomaly detection, where we have to deal with a really wide range of colors and types of textile and a stoppage of the production line for training could not be considered. In this paper, we propose an automation process for industrial fabric texture defect detection with a specificity-learning process during the domain-generalized anomaly detection. Combining the ability to generalize and the learning process offer a fast and precise anomaly detection and segmentation. The main contributions of this paper are the following: A domain-generalization texture anomaly detection method achieving the state-of-the-art performances, a fast specific training on good samples extracted by the proposed method, a self-evaluation method based on custom defect creation and an automatic detection of already seen fabric to prevent re-training.
Bi-level Doubly Variational Learning for Energy-based Latent Variable Models
Mar 24, 2022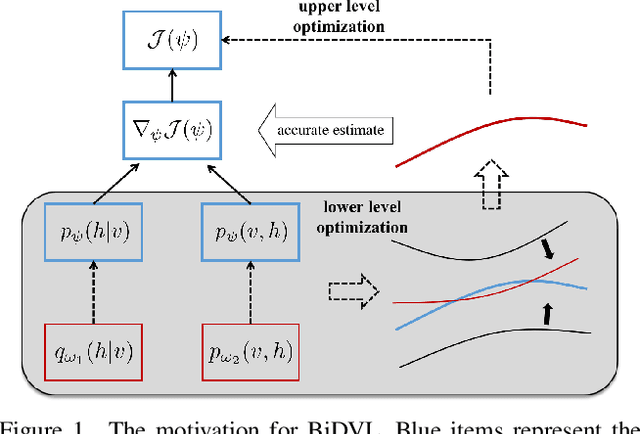

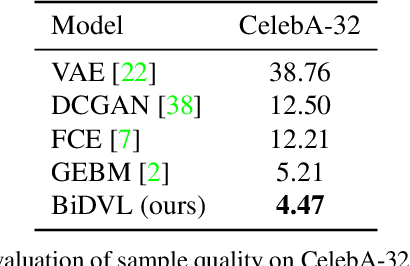

Energy-based latent variable models (EBLVMs) are more expressive than conventional energy-based models. However, its potential on visual tasks are limited by its training process based on maximum likelihood estimate that requires sampling from two intractable distributions. In this paper, we propose Bi-level doubly variational learning (BiDVL), which is based on a new bi-level optimization framework and two tractable variational distributions to facilitate learning EBLVMs. Particularly, we lead a decoupled EBLVM consisting of a marginal energy-based distribution and a structural posterior to handle the difficulties when learning deep EBLVMs on images. By choosing a symmetric KL divergence in the lower level of our framework, a compact BiDVL for visual tasks can be obtained. Our model achieves impressive image generation performance over related works. It also demonstrates the significant capacity of testing image reconstruction and out-of-distribution detection.