 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Modeling of Single-cell perturbation Responses to Novel Drugs Using Cycle Consistence Learning
Nov 17, 2023Phenotype-based screening has attracted much attention for identifying cell-active compounds. Transcriptional and proteomic profiles of cell population or single cells are informative phenotypic measures of cellular responses to perturbations. In this paper, we proposed a deep learning framework based on encoder-decoder architecture that maps the initial cellular states to a latent space, in which we assume the effects of drug perturbation on cellular states follow linear additivity. Next, we introduced the cycle consistency constraints to enforce that initial cellular state subjected to drug perturbations would produce the perturbed cellular responses, and, conversely, removal of drug perturbation from the perturbed cellular states would restore the initial cellular states. The cycle consistency constraints and linear modeling in latent space enable to learn interpretable and transferable drug perturbation representations, so that our model can predict cellular response to unseen drugs. We validated our model on three different types of datasets, including bulk transcriptional responses, bulk proteomic responses, and single-cell transcriptional responses to drug perturbations. The experimental results show that our model achieves better performance than existing state-of-the-art methods.
TVPR: Text-to-Video Person Retrieval and a New Benchmark
Jul 14, 2023Most existing methods for text-based person retrieval focus on text-to-image person retrieval. Nevertheless, due to the lack of dynamic information provided by isolated frames, the performance is hampered when the person is obscured in isolated frames or variable motion details are given in the textual description. In this paper, we propose a new task called Text-to-Video Person Retrieval(TVPR) which aims to effectively overcome the limitations of isolated frames. Since there is no dataset or benchmark that describes person videos with natural language, we construct a large-scale cross-modal person video dataset containing detailed natural language annotations, such as person's appearance, actions and interactions with environment, etc., termed as Text-to-Video Person Re-identification (TVPReid) dataset, which will be publicly available. To this end, a Text-to-Video Person Retrieval Network (TVPRN) is proposed. Specifically, TVPRN acquires video representations by fusing visual and motion representations of person videos, which can deal with temporal occlusion and the absence of variable motion details in isolated frames. Meanwhile, we employ the pre-trained BERT to obtain caption representations and the relationship between caption and video representations to reveal the most relevant person videos. To evaluate the effectiveness of the proposed TVPRN, extensive experiments have been conducted on TVPReid dataset. To the best of our knowledge, TVPRN is the first successful attempt to use video for text-based person retrieval task and has achieved state-of-the-art performance on TVPReid dataset. The TVPReid dataset will be publicly available to benefit future research.
Look Before You Leap: Improving Text-based Person Retrieval by Learning A Consistent Cross-modal Common Manifold
Sep 13, 2022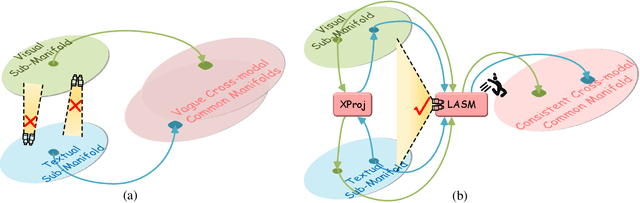
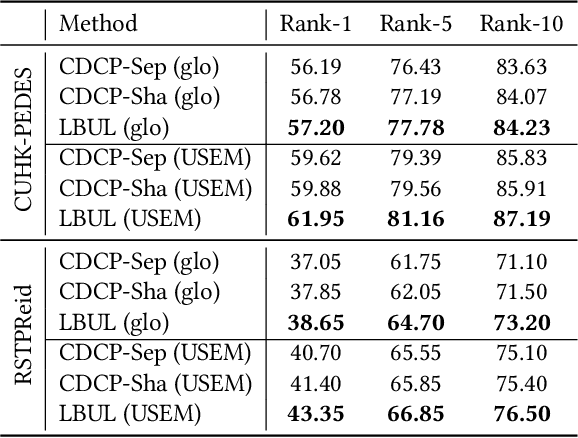
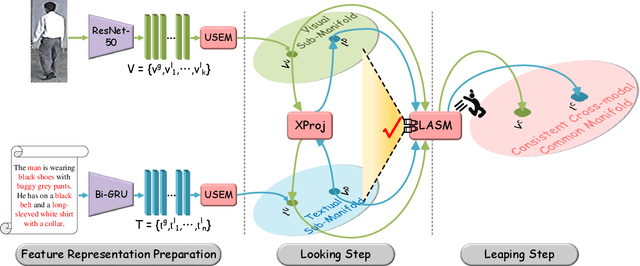
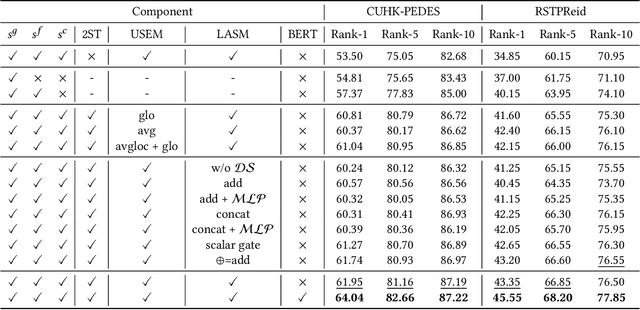
The core problem of text-based person retrieval is how to bridge the heterogeneous gap between multi-modal data. Many previous approaches contrive to learning a latent common manifold mapping paradigm following a \textbf{cross-modal distribution consensus prediction (CDCP)} manner. When mapping features from distribution of one certain modality into the common manifold, feature distribution of the opposite modality is completely invisible. That is to say, how to achieve a cross-modal distribution consensus so as to embed and align the multi-modal features in a constructed cross-modal common manifold all depends on the experience of the model itself, instead of the actual situation. With such methods, it is inevitable that the multi-modal data can not be well aligned in the common manifold, which finally leads to a sub-optimal retrieval performance. To overcome this \textbf{CDCP dilemma}, we propose a novel algorithm termed LBUL to learn a Consistent Cross-modal Common Manifold (C$^{3}$M) for text-based person retrieval. The core idea of our method, just as a Chinese saying goes, is to `\textit{san si er hou xing}', namely, to \textbf{Look Before yoU Leap (LBUL)}. The common manifold mapping mechanism of LBUL contains a looking step and a leaping step. Compared to CDCP-based methods, LBUL considers distribution characteristics of both the visual and textual modalities before embedding data from one certain modality into C$^{3}$M to achieve a more solid cross-modal distribution consensus, and hence achieve a superior retrieval accuracy. We evaluate our proposed method on two text-based person retrieval datasets CUHK-PEDES and RSTPReid. Experimental results demonstrate that the proposed LBUL outperforms previous methods and achieves the state-of-the-art performance.
CAIBC: Capturing All-round Information Beyond Color for Text-based Person Retrieval
Sep 13, 2022
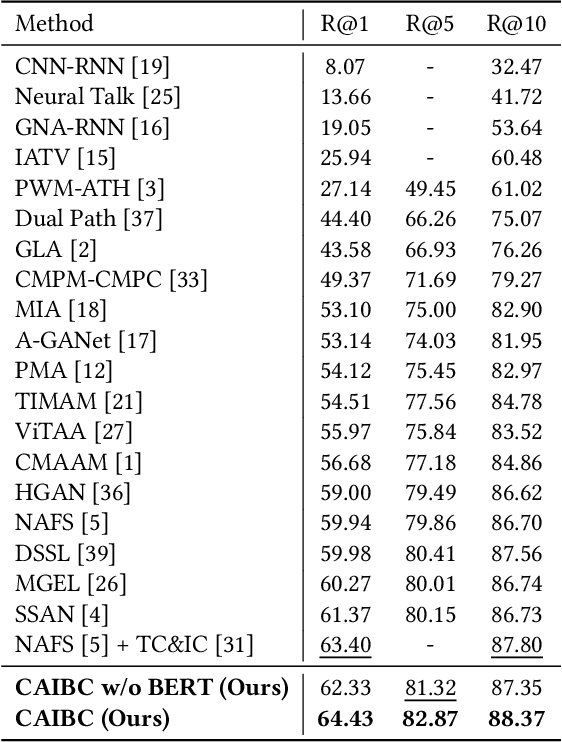
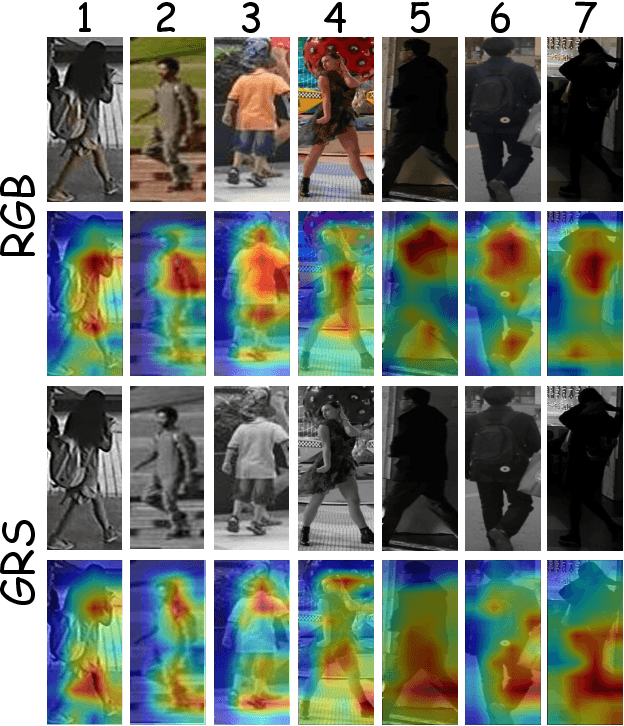
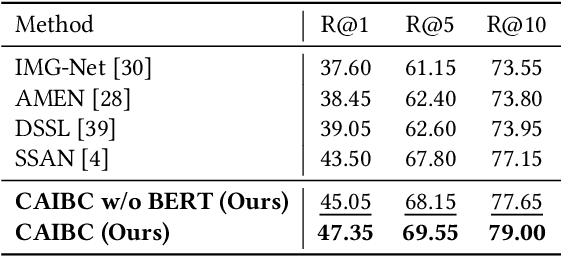
Given a natural language description, text-based person retrieval aims to identify images of a target person from a large-scale person image database. Existing methods generally face a \textbf{color over-reliance problem}, which means that the models rely heavily on color information when matching cross-modal data. Indeed, color information is an important decision-making accordance for retrieval, but the over-reliance on color would distract the model from other key clues (e.g. texture information, structural information, etc.), and thereby lead to a sub-optimal retrieval performance. To solve this problem, in this paper, we propose to \textbf{C}apture \textbf{A}ll-round \textbf{I}nformation \textbf{B}eyond \textbf{C}olor (\textbf{CAIBC}) via a jointly optimized multi-branch architecture for text-based person retrieval. CAIBC contains three branches including an RGB branch, a grayscale (GRS) branch and a color (CLR) branch. Besides, with the aim of making full use of all-round information in a balanced and effective way, a mutual learning mechanism is employed to enable the three branches which attend to varied aspects of information to communicate with and learn from each other. Extensive experimental analysis is carried out to evaluate our proposed CAIBC method on the CUHK-PEDES and RSTPReid datasets in both \textbf{supervised} and \textbf{weakly supervised} text-based person retrieval settings, which demonstrates that CAIBC significantly outperforms existing methods and achieves the state-of-the-art performance on all the three tasks.
Bi-level Doubly Variational Learning for Energy-based Latent Variable Models
Mar 24, 2022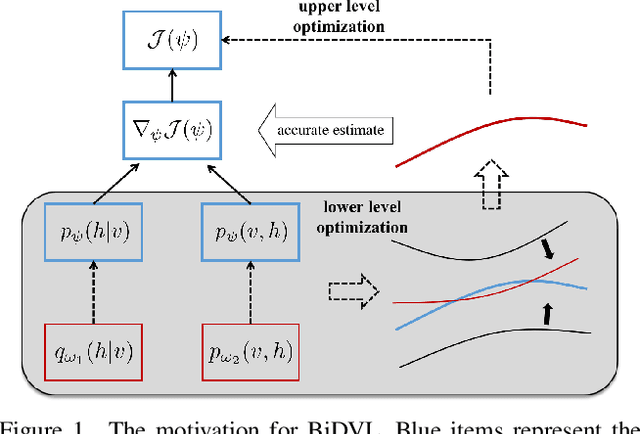

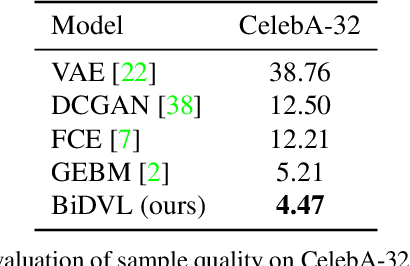

Energy-based latent variable models (EBLVMs) are more expressive than conventional energy-based models. However, its potential on visual tasks are limited by its training process based on maximum likelihood estimate that requires sampling from two intractable distributions. In this paper, we propose Bi-level doubly variational learning (BiDVL), which is based on a new bi-level optimization framework and two tractable variational distributions to facilitate learning EBLVMs. Particularly, we lead a decoupled EBLVM consisting of a marginal energy-based distribution and a structural posterior to handle the difficulties when learning deep EBLVMs on images. By choosing a symmetric KL divergence in the lower level of our framework, a compact BiDVL for visual tasks can be obtained. Our model achieves impressive image generation performance over related works. It also demonstrates the significant capacity of testing image reconstruction and out-of-distribution detection.
DSSL: Deep Surroundings-person Separation Learning for Text-based Person Retrieval
Sep 12, 2021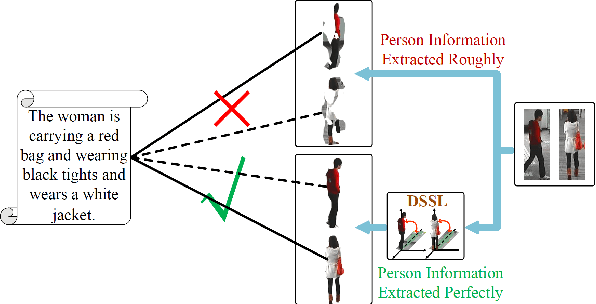
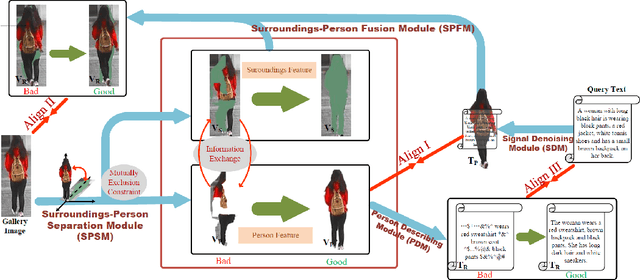
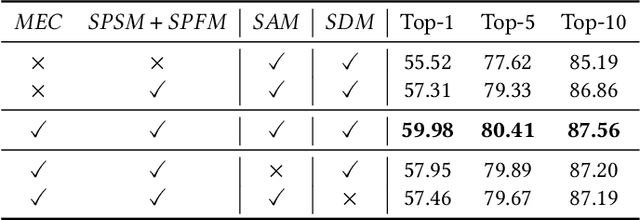
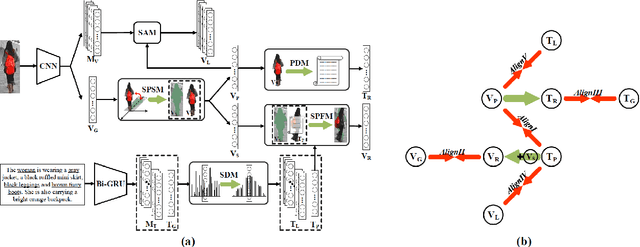
Many previous methods on text-based person retrieval tasks are devoted to learning a latent common space mapping, with the purpose of extracting modality-invariant features from both visual and textual modality. Nevertheless, due to the complexity of high-dimensional data, the unconstrained mapping paradigms are not able to properly catch discriminative clues about the corresponding person while drop the misaligned information. Intuitively, the information contained in visual data can be divided into person information (PI) and surroundings information (SI), which are mutually exclusive from each other. To this end, we propose a novel Deep Surroundings-person Separation Learning (DSSL) model in this paper to effectively extract and match person information, and hence achieve a superior retrieval accuracy. A surroundings-person separation and fusion mechanism plays the key role to realize an accurate and effective surroundings-person separation under a mutually exclusion constraint. In order to adequately utilize multi-modal and multi-granular information for a higher retrieval accuracy, five diverse alignment paradigms are adopted. Extensive experiments are carried out to evaluate the proposed DSSL on CUHK-PEDES, which is currently the only accessible dataset for text-base person retrieval task. DSSL achieves the state-of-the-art performance on CUHK-PEDES. To properly evaluate our proposed DSSL in the real scenarios, a Real Scenarios Text-based Person Reidentification (RSTPReid) dataset is constructed to benefit future research on text-based person retrieval, which will be publicly available.