 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTVPR: Text-to-Video Person Retrieval and a New Benchmark
Jul 14, 2023Most existing methods for text-based person retrieval focus on text-to-image person retrieval. Nevertheless, due to the lack of dynamic information provided by isolated frames, the performance is hampered when the person is obscured in isolated frames or variable motion details are given in the textual description. In this paper, we propose a new task called Text-to-Video Person Retrieval(TVPR) which aims to effectively overcome the limitations of isolated frames. Since there is no dataset or benchmark that describes person videos with natural language, we construct a large-scale cross-modal person video dataset containing detailed natural language annotations, such as person's appearance, actions and interactions with environment, etc., termed as Text-to-Video Person Re-identification (TVPReid) dataset, which will be publicly available. To this end, a Text-to-Video Person Retrieval Network (TVPRN) is proposed. Specifically, TVPRN acquires video representations by fusing visual and motion representations of person videos, which can deal with temporal occlusion and the absence of variable motion details in isolated frames. Meanwhile, we employ the pre-trained BERT to obtain caption representations and the relationship between caption and video representations to reveal the most relevant person videos. To evaluate the effectiveness of the proposed TVPRN, extensive experiments have been conducted on TVPReid dataset. To the best of our knowledge, TVPRN is the first successful attempt to use video for text-based person retrieval task and has achieved state-of-the-art performance on TVPReid dataset. The TVPReid dataset will be publicly available to benefit future research.
Kinship Verification Based on Cross-Generation Feature Interaction Learning
Sep 07, 2021
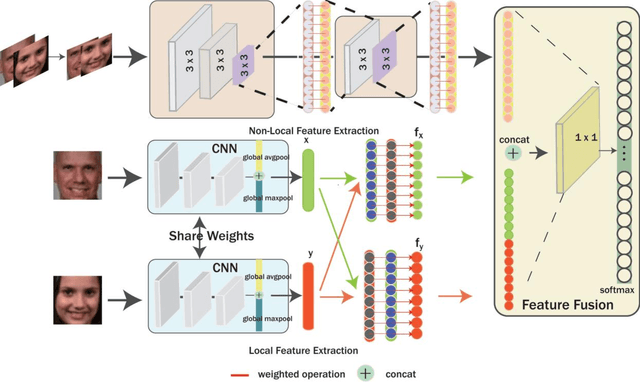

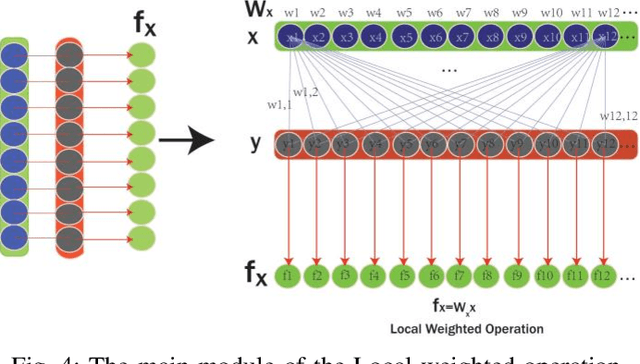
Kinship verification from facial images has been recognized as an emerging yet challenging technique in many potential computer vision applications. In this paper, we propose a novel cross-generation feature interaction learning (CFIL) framework for robust kinship verification. Particularly, an effective collaborative weighting strategy is constructed to explore the characteristics of cross-generation relations by corporately extracting features of both parents and children image pairs. Specifically, we take parents and children as a whole to extract the expressive local and non-local features. Different from the traditional works measuring similarity by distance, we interpolate the similarity calculations as the interior auxiliary weights into the deep CNN architecture to learn the whole and natural features. These similarity weights not only involve corresponding single points but also excavate the multiple relationships cross points, where local and non-local features are calculated by using these two kinds of distance measurements. Importantly, instead of separately conducting similarity computation and feature extraction, we integrate similarity learning and feature extraction into one unified learning process. The integrated representations deduced from local and non-local features can comprehensively express the informative semantics embedded in images and preserve abundant correlation knowledge from image pairs. Extensive experiments demonstrate the efficiency and superiority of the proposed model compared to some state-of-the-art kinship verification methods.
Deep Collaborative Multi-Modal Learning for Unsupervised Kinship Estimation
Sep 07, 2021



Kinship verification is a long-standing research challenge in computer vision. The visual differences presented to the face have a significant effect on the recognition capabilities of the kinship systems. We argue that aggregating multiple visual knowledge can better describe the characteristics of the subject for precise kinship identification. Typically, the age-invariant features can represent more natural facial details. Such age-related transformations are essential for face recognition due to the biological effects of aging. However, the existing methods mainly focus on employing the single-view image features for kinship identification, while more meaningful visual properties such as race and age are directly ignored in the feature learning step. To this end, we propose a novel deep collaborative multi-modal learning (DCML) to integrate the underlying information presented in facial properties in an adaptive manner to strengthen the facial details for effective unsupervised kinship verification. Specifically, we construct a well-designed adaptive feature fusion mechanism, which can jointly leverage the complementary properties from different visual perspectives to produce composite features and draw greater attention to the most informative components of spatial feature maps. Particularly, an adaptive weighting strategy is developed based on a novel attention mechanism, which can enhance the dependencies between different properties by decreasing the information redundancy in channels in a self-adaptive manner. To validate the effectiveness of the proposed method, extensive experimental evaluations conducted on four widely-used datasets show that our DCML method is always superior to some state-of-the-art kinship verification methods.