 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook Before You Leap: Improving Text-based Person Retrieval by Learning A Consistent Cross-modal Common Manifold
Paper and Code
Sep 13, 2022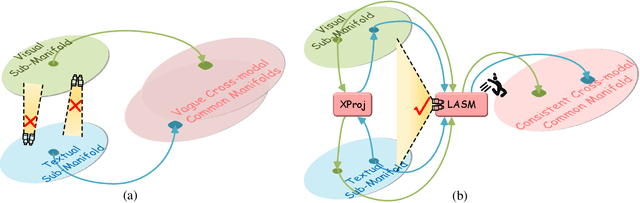
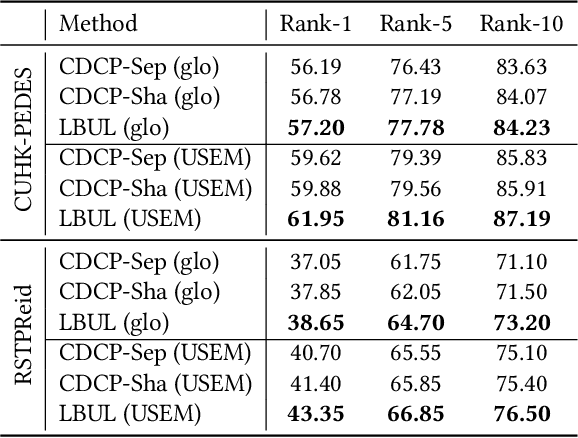
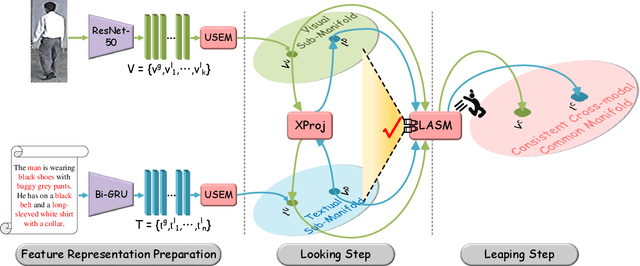
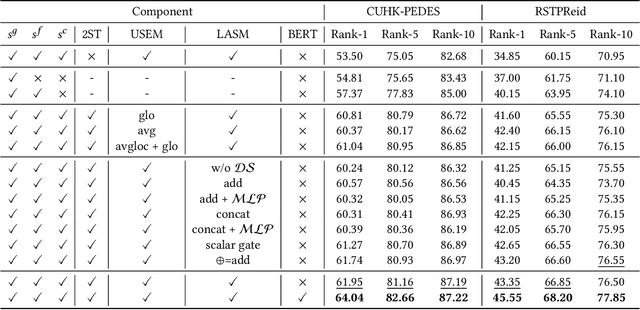
The core problem of text-based person retrieval is how to bridge the heterogeneous gap between multi-modal data. Many previous approaches contrive to learning a latent common manifold mapping paradigm following a \textbf{cross-modal distribution consensus prediction (CDCP)} manner. When mapping features from distribution of one certain modality into the common manifold, feature distribution of the opposite modality is completely invisible. That is to say, how to achieve a cross-modal distribution consensus so as to embed and align the multi-modal features in a constructed cross-modal common manifold all depends on the experience of the model itself, instead of the actual situation. With such methods, it is inevitable that the multi-modal data can not be well aligned in the common manifold, which finally leads to a sub-optimal retrieval performance. To overcome this \textbf{CDCP dilemma}, we propose a novel algorithm termed LBUL to learn a Consistent Cross-modal Common Manifold (C$^{3}$M) for text-based person retrieval. The core idea of our method, just as a Chinese saying goes, is to `\textit{san si er hou xing}', namely, to \textbf{Look Before yoU Leap (LBUL)}. The common manifold mapping mechanism of LBUL contains a looking step and a leaping step. Compared to CDCP-based methods, LBUL considers distribution characteristics of both the visual and textual modalities before embedding data from one certain modality into C$^{3}$M to achieve a more solid cross-modal distribution consensus, and hence achieve a superior retrieval accuracy. We evaluate our proposed method on two text-based person retrieval datasets CUHK-PEDES and RSTPReid. Experimental results demonstrate that the proposed LBUL outperforms previous methods and achieves the state-of-the-art performance.