 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld Models as Group Actions
May 23, 2026Video world models have achieved strong visual realism, but this does not ensure that their dynamics are truly governed by actions. In this work, we argue that action faithfulness should be understood through the compositional structure of actions, which in many embodied settings follows a group structure (e.g., SE(2) for navigation). Based on this insight, we formalize action-conditioned world modeling as realizing a group action on the state space, providing a principled criterion for evaluating dynamics beyond visual quality. To operationalize this framework, we propose a unified approach that enforces identity, inverse, and composition consistency via latent-space regularization with synthesized supervision, avoiding additional data collection. We further introduce two metrics: Group-Action Consistency (GAC) and Group-Action Robustness (GAR), to evaluate structural correctness and rollout stability. Extensive experimental results show that our method consistently improves both GAC and GAR in state-of-the-art video world models without degrading perceptual quality.
Commonsense Knowledge with Negation: A Resource to Enhance Negation Understanding
Apr 21, 2026Negation is a common and important semantic feature in natural language, yet Large Language Models (LLMs) struggle when negation is involved in natural language understanding tasks. Commonsense knowledge, on the other hand, despite being a well-studied topic, lacks investigations involving negation. In this work, we show that commonsense knowledge with negation is challenging for models to understand. We present a novel approach to automatically augment existing commonsense knowledge corpora with negation, yielding two new corpora containing over 2M triples with if-then relations. In addition, pre-training LLMs on our corpora benefits negation understanding.
Seedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
AdapTools: Adaptive Tool-based Indirect Prompt Injection Attacks on Agentic LLMs
Feb 24, 2026The integration of external data services (e.g., Model Context Protocol, MCP) has made large language model-based agents increasingly powerful for complex task execution. However, this advancement introduces critical security vulnerabilities, particularly indirect prompt injection (IPI) attacks. Existing attack methods are limited by their reliance on static patterns and evaluation on simple language models, failing to address the fast-evolving nature of modern AI agents. We introduce AdapTools, a novel adaptive IPI attack framework that selects stealthier attack tools and generates adaptive attack prompts to create a rigorous security evaluation environment. Our approach comprises two key components: (1) Adaptive Attack Strategy Construction, which develops transferable adversarial strategies for prompt optimization, and (2) Attack Enhancement, which identifies stealthy tools capable of circumventing task-relevance defenses. Comprehensive experimental evaluation shows that AdapTools achieves a 2.13 times improvement in attack success rate while degrading system utility by a factor of 1.78. Notably, the framework maintains its effectiveness even against state-of-the-art defense mechanisms. Our method advances the understanding of IPI attacks and provides a useful reference for future research.
MIRNet: Integrating Constrained Graph-Based Reasoning with Pre-training for Diagnostic Medical Imaging
Nov 13, 2025Automated interpretation of medical images demands robust modeling of complex visual-semantic relationships while addressing annotation scarcity, label imbalance, and clinical plausibility constraints. We introduce MIRNet (Medical Image Reasoner Network), a novel framework that integrates self-supervised pre-training with constrained graph-based reasoning. Tongue image diagnosis is a particularly challenging domain that requires fine-grained visual and semantic understanding. Our approach leverages self-supervised masked autoencoder (MAE) to learn transferable visual representations from unlabeled data; employs graph attention networks (GAT) to model label correlations through expert-defined structured graphs; enforces clinical priors via constraint-aware optimization using KL divergence and regularization losses; and mitigates imbalance using asymmetric loss (ASL) and boosting ensembles. To address annotation scarcity, we also introduce TongueAtlas-4K, a comprehensive expert-curated benchmark comprising 4,000 images annotated with 22 diagnostic labels--representing the largest public dataset in tongue analysis. Validation shows our method achieves state-of-the-art performance. While optimized for tongue diagnosis, the framework readily generalizes to broader diagnostic medical imaging tasks.
LaneDiffusion: Improving Centerline Graph Learning via Prior Injected BEV Feature Generation
Nov 09, 2025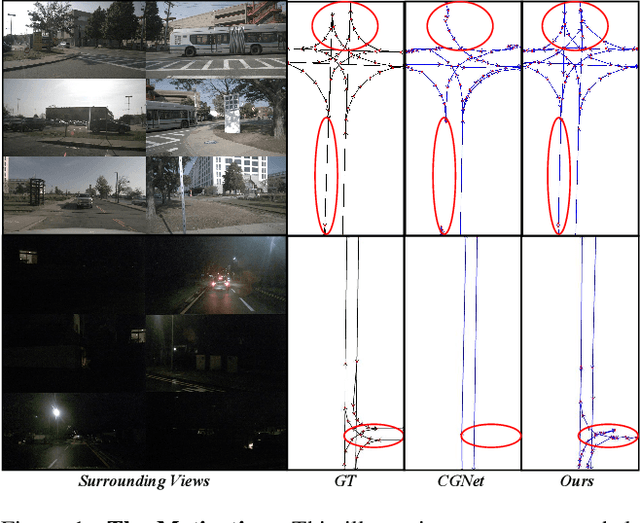
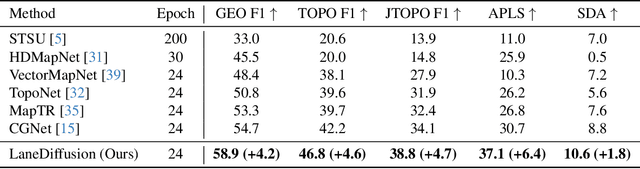
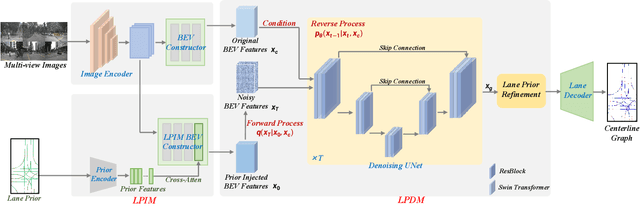
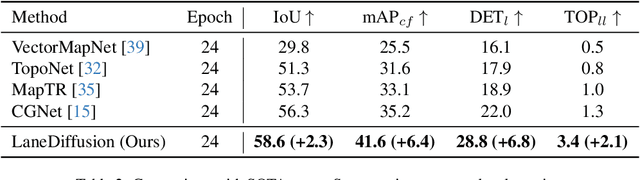
Centerline graphs, crucial for path planning in autonomous driving, are traditionally learned using deterministic methods. However, these methods often lack spatial reasoning and struggle with occluded or invisible centerlines. Generative approaches, despite their potential, remain underexplored in this domain. We introduce LaneDiffusion, a novel generative paradigm for centerline graph learning. LaneDiffusion innovatively employs diffusion models to generate lane centerline priors at the Bird's Eye View (BEV) feature level, instead of directly predicting vectorized centerlines. Our method integrates a Lane Prior Injection Module (LPIM) and a Lane Prior Diffusion Module (LPDM) to effectively construct diffusion targets and manage the diffusion process. Furthermore, vectorized centerlines and topologies are then decoded from these prior-injected BEV features. Extensive evaluations on the nuScenes and Argoverse2 datasets demonstrate that LaneDiffusion significantly outperforms existing methods, achieving improvements of 4.2%, 4.6%, 4.7%, 6.4% and 1.8% on fine-grained point-level metrics (GEO F1, TOPO F1, JTOPO F1, APLS and SDA) and 2.3%, 6.4%, 6.8% and 2.1% on segment-level metrics (IoU, mAP_cf, DET_l and TOP_ll). These results establish state-of-the-art performance in centerline graph learning, offering new insights into generative models for this task.
Identifying and Answering Questions with False Assumptions: An Interpretable Approach
Aug 21, 2025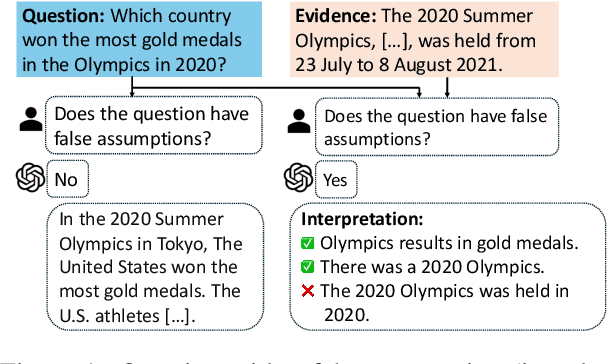

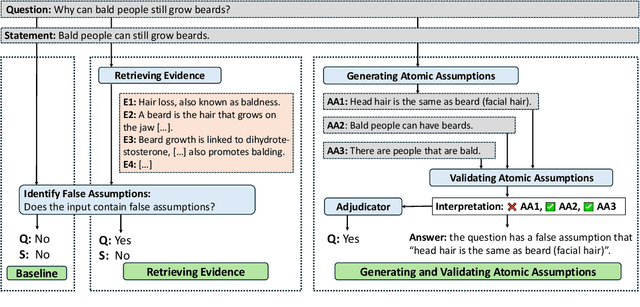
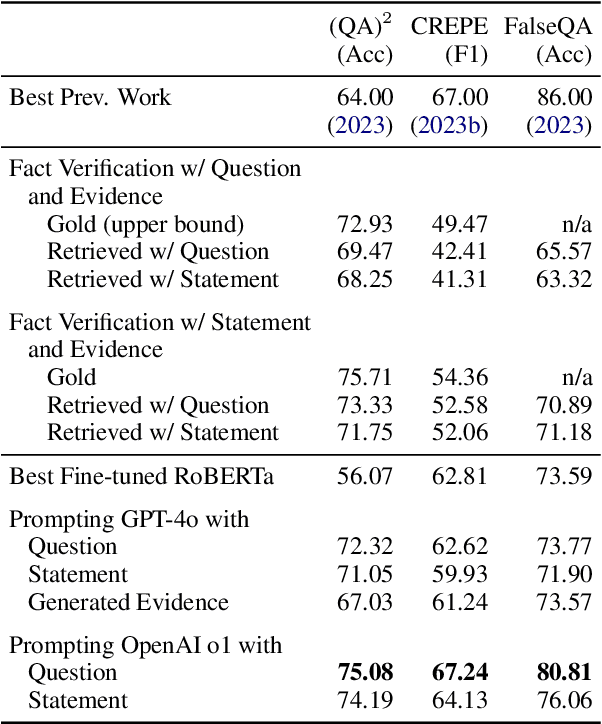
People often ask questions with false assumptions, a type of question that does not have regular answers. Answering such questions require first identifying the false assumptions. Large Language Models (LLMs) often generate misleading answers because of hallucinations. In this paper, we focus on identifying and answering questions with false assumptions in several domains. We first investigate to reduce the problem to fact verification. Then, we present an approach leveraging external evidence to mitigate hallucinations. Experiments with five LLMs demonstrate that (1) incorporating retrieved evidence is beneficial and (2) generating and validating atomic assumptions yields more improvements and provides an interpretable answer by specifying the false assumptions.
Construction of an Organ Shape Atlas Using a Hierarchical Mesh Variational Autoencoder
Jun 18, 2025



An organ shape atlas, which represents the shape and position of the organs and skeleton of a living body using a small number of parameters, is expected to have a wide range of clinical applications, including intraoperative guidance and radiotherapy. Because the shape and position of soft organs vary greatly among patients, it is difficult for linear models to reconstruct shapes that have large local variations. Because it is difficult for conventional nonlinear models to control and interpret the organ shapes obtained, deep learning has been attracting attention in three-dimensional shape representation. In this study, we propose an organ shape atlas based on a mesh variational autoencoder (MeshVAE) with hierarchical latent variables. To represent the complex shapes of biological organs and nonlinear shape differences between individuals, the proposed method maintains the performance of organ shape reconstruction by hierarchizing latent variables and enables shape representation using lower-dimensional latent variables. Additionally, templates that define vertex correspondence between different resolutions enable hierarchical representation in mesh data and control the global and local features of the organ shape. We trained the model using liver and stomach organ meshes obtained from 124 cases and confirmed that the model reconstructed the position and shape with an average distance between vertices of 1.5 mm and mean distance of 0.7 mm for the liver shape, and an average distance between vertices of 1.4 mm and mean distance of 0.8 mm for the stomach shape on test data from 19 of cases. The proposed method continuously represented interpolated shapes, and by changing latent variables at different hierarchical levels, the proposed method hierarchically separated shape features compared with PCA.
Fundamental MMSE-Rate Performance Limits of Integrated Sensing and Communication Systems
Jan 02, 2025



Integrated sensing and communication (ISAC) demonstrates promise for 6G networks; yet its performance limits, which require addressing functional Pareto stochastic optimizations, remain underexplored. Existing works either overlook the randomness of ISAC signals or approximate ISAC limits from sensing and communication (SAC) optimum-achieving strategies, leading to loose bounds. In this paper, ISAC limits are investigated by considering a random ISAC signal designated to simultaneously estimate the sensing channel and convey information over the communication channel, adopting the modified minimum-mean-square-error (MMSE), a metric defined in accordance with the randomness of ISAC signals, and the Shannon rate as respective SAC metrics. First, conditions for optimal channel input and output distributions on the MMSE-Rate limit are derived employing variational approaches, leading to high-dimensional convolutional equations. Second, leveraging variational conditions, a Blahut-Arimoto-type algorithm is proposed to numerically determine optimal distributions and SAC performance, with its convergence to the limit proven. Third, closed-form SAC-optimal waveforms are derived, characterized by power allocation according to channel statistics/realization and waveform selection; existing methods to establish looser ISAC bounds are rectified. Finally, a compound signaling strategy is introduced for coincided SAC channels, which employs sequential SAC-optimal waveforms for channel estimation and data transmission, showcasing significant rate improvements over non-coherent "capacity". This study systematically investigates ISAC performance limits from joint estimation- and information-theoretic perspectives, highlighting key SAC tradeoffs and potential ISAC design benefits. The methodology readily extends to various metrics, such as estimation rate and the Cramer-Rao Bound.
Interpreting Indirect Answers to Yes-No Questions in Multiple Languages
Oct 20, 2023
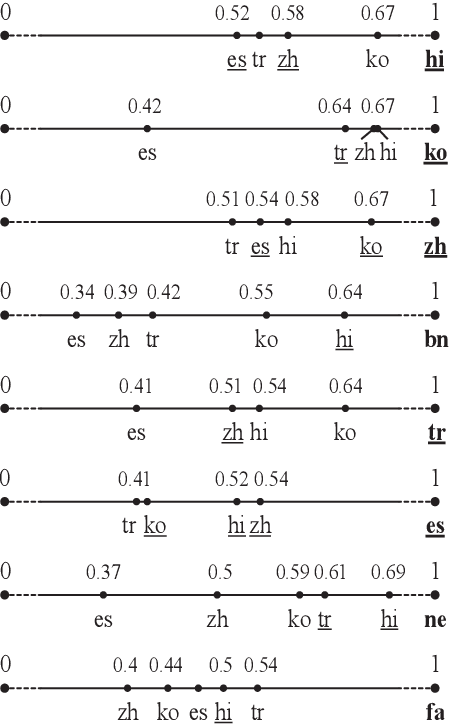
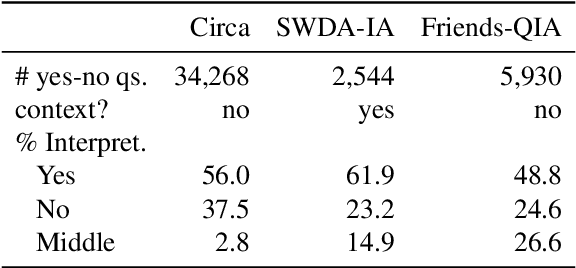

Yes-no questions expect a yes or no for an answer, but people often skip polar keywords. Instead, they answer with long explanations that must be interpreted. In this paper, we focus on this challenging problem and release new benchmarks in eight languages. We present a distant supervision approach to collect training data. We also demonstrate that direct answers (i.e., with polar keywords) are useful to train models to interpret indirect answers (i.e., without polar keywords). Experimental results demonstrate that monolingual fine-tuning is beneficial if training data can be obtained via distant supervision for the language of interest (5 languages). Additionally, we show that cross-lingual fine-tuning is always beneficial (8 languages).