 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Meets Brain: Memory Systems from Cognitive Neuroscience to Autonomous Agents
Dec 29, 2025Memory serves as the pivotal nexus bridging past and future, providing both humans and AI systems with invaluable concepts and experience to navigate complex tasks. Recent research on autonomous agents has increasingly focused on designing efficient memory workflows by drawing on cognitive neuroscience. However, constrained by interdisciplinary barriers, existing works struggle to assimilate the essence of human memory mechanisms. To bridge this gap, we systematically synthesizes interdisciplinary knowledge of memory, connecting insights from cognitive neuroscience with LLM-driven agents. Specifically, we first elucidate the definition and function of memory along a progressive trajectory from cognitive neuroscience through LLMs to agents. We then provide a comparative analysis of memory taxonomy, storage mechanisms, and the complete management lifecycle from both biological and artificial perspectives. Subsequently, we review the mainstream benchmarks for evaluating agent memory. Additionally, we explore memory security from dual perspectives of attack and defense. Finally, we envision future research directions, with a focus on multimodal memory systems and skill acquisition.
ByteComposer: a Human-like Melody Composition Method based on Language Model Agent
Mar 07, 2024Large Language Models (LLM) have shown encouraging progress in multimodal understanding and generation tasks. However, how to design a human-aligned and interpretable melody composition system is still under-explored. To solve this problem, we propose ByteComposer, an agent framework emulating a human's creative pipeline in four separate steps : "Conception Analysis - Draft Composition - Self-Evaluation and Modification - Aesthetic Selection". This framework seamlessly blends the interactive and knowledge-understanding features of LLMs with existing symbolic music generation models, thereby achieving a melody composition agent comparable to human creators. We conduct extensive experiments on GPT4 and several open-source large language models, which substantiate our framework's effectiveness. Furthermore, professional music composers were engaged in multi-dimensional evaluations, the final results demonstrated that across various facets of music composition, ByteComposer agent attains the level of a novice melody composer.
ByteCover3: Accurate Cover Song Identification on Short Queries
Mar 21, 2023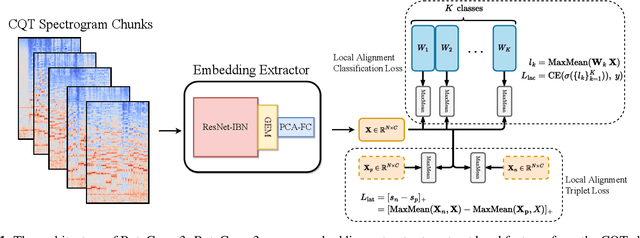
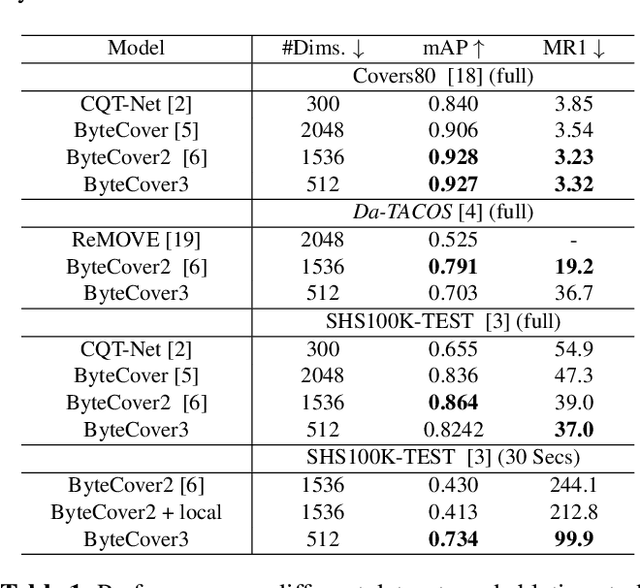
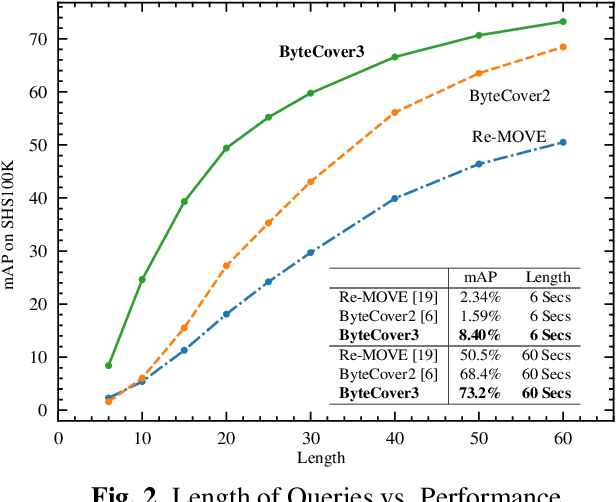
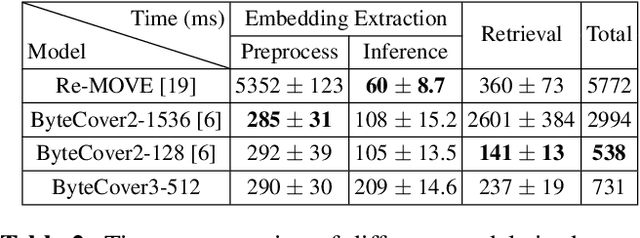
Deep learning based methods have become a paradigm for cover song identification (CSI) in recent years, where the ByteCover systems have achieved state-of-the-art results on all the mainstream datasets of CSI. However, with the burgeon of short videos, many real-world applications require matching short music excerpts to full-length music tracks in the database, which is still under-explored and waiting for an industrial-level solution. In this paper, we upgrade the previous ByteCover systems to ByteCover3 that utilizes local features to further improve the identification performance of short music queries. ByteCover3 is designed with a local alignment loss (LAL) module and a two-stage feature retrieval pipeline, allowing the system to perform CSI in a more precise and efficient way. We evaluated ByteCover3 on multiple datasets with different benchmark settings, where ByteCover3 beat all the compared methods including its previous versions.
Attention-based cross-modal fusion for audio-visual voice activity detection in musical video streams
Jun 21, 2021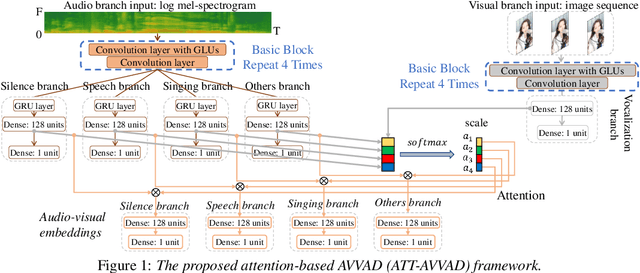

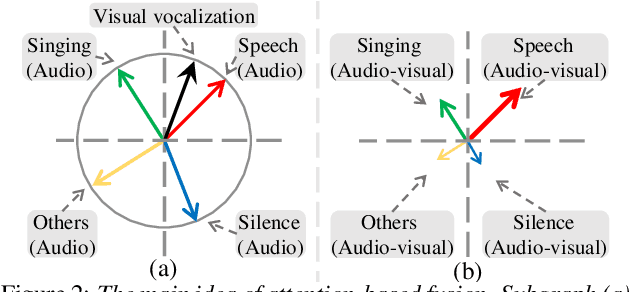
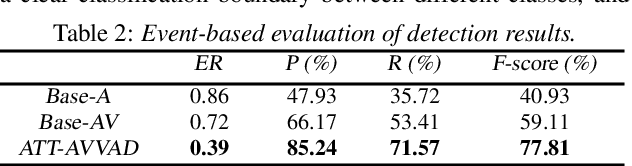
Many previous audio-visual voice-related works focus on speech, ignoring the singing voice in the growing number of musical video streams on the Internet. For processing diverse musical video data, voice activity detection is a necessary step. This paper attempts to detect the speech and singing voices of target performers in musical video streams using audiovisual information. To integrate information of audio and visual modalities, a multi-branch network is proposed to learn audio and image representations, and the representations are fused by attention based on semantic similarity to shape the acoustic representations through the probability of anchor vocalization. Experiments show the proposed audio-visual multi-branch network far outperforms the audio-only model in challenging acoustic environments, indicating the cross-modal information fusion based on semantic correlation is sensible and successful.
MIDI-Sandwich2: RNN-based Hierarchical Multi-modal Fusion Generation VAE networks for multi-track symbolic music generation
Sep 08, 2019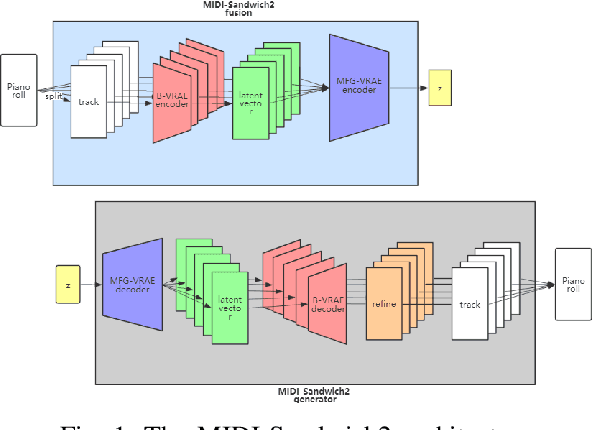

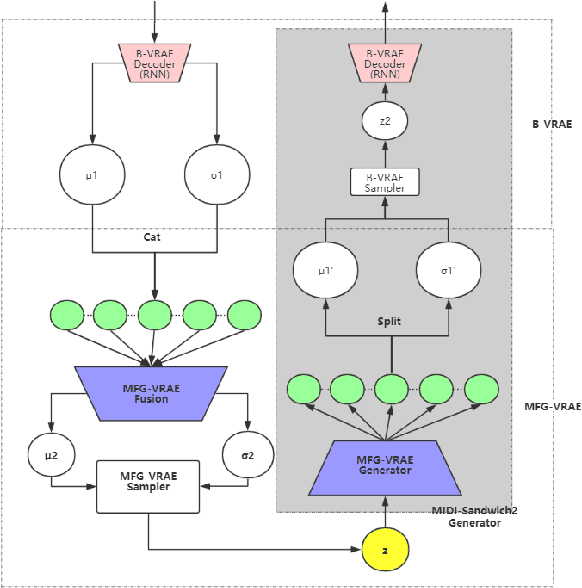
Currently, almost all the multi-track music generation models use the Convolutional Neural Network (CNN) to build the generative model, while the Recurrent Neural Network (RNN) based models can not be applied in this task. In view of the above problem, this paper proposes a RNN-based Hierarchical Multi-modal Fusion Generation Variational Autoencoder (VAE) network, MIDI-Sandwich2, for multi-track symbolic music generation. Inspired by VQ-VAE2, MIDI-Sandwich2 expands the dimension of the original hierarchical model by using multiple independent Binary Variational Autoencoder (BVAE) models without sharing weights to process the information of each track. Then, with multi-modal fusion technology, the upper layer named Multi-modal Fusion Generation VAE (MFG-VAE) combines the latent space vectors generated by the respective tracks, and uses the decoder to perform the ascending dimension reconstruction to simulate the inverse operation of multi-modal fusion, multi-modal generation, so as to realize the RNN-based multi-track symbolic music generation. For the multi-track format pianoroll, we also improve the output binarization method of MuseGAN, which solves the problem that the refinement step of the original scheme is difficult to differentiate and the gradient is hard to descent, making the generated song more expressive. The model is validated on the Lakh Pianoroll Dataset (LPD) multi-track dataset. Compared to the MuseGAN, MIDI-Sandwich2 can not only generate harmonious multi-track music, the generation quality is also close to the state of the art level. At the same time, by using the VAE to restore songs, the semi-generated songs reproduced by the MIDI-Sandwich2 are more beautiful than the pure autogeneration music generated by MuseGAN. Both the code and the audition audio samples are open source on https://github.com/LiangHsia/MIDI-S2.
MIDI-Sandwich: Multi-model Multi-task Hierarchical Conditional VAE-GAN networks for Symbolic Single-track Music Generation
Jul 04, 2019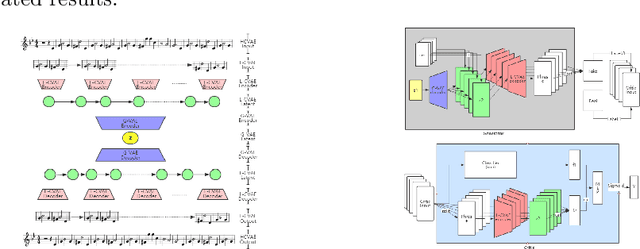
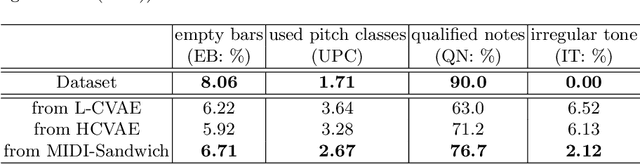
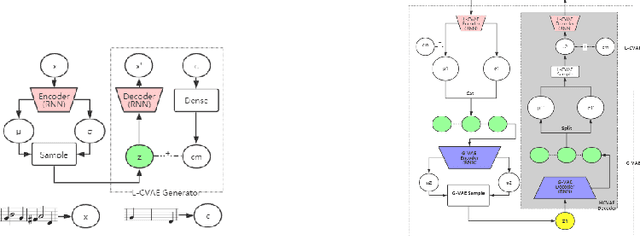
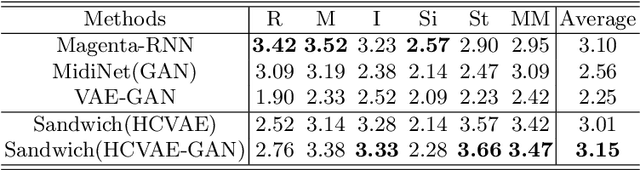
Most existing neural network models for music generation explore how to generate music bars, then directly splice the music bars into a song. However, these methods do not explore the relationship between the bars, and the connected song as a whole has no musical form structure and sense of musical direction. To address this issue, we propose a Multi-model Multi-task Hierarchical Conditional VAE-GAN (Variational Autoencoder-Generative adversarial networks) networks, named MIDI-Sandwich, which combines musical knowledge, such as musical form, tonic, and melodic motion. The MIDI-Sandwich has two submodels: Hierarchical Conditional Variational Autoencoder (HCVAE) and Hierarchical Conditional Generative Adversarial Network (HCGAN). The HCVAE uses hierarchical structure. The underlying layer of HCVAE uses Local Conditional Variational Autoencoder (L-CVAE) to generate a music bar which is pre-specified by the First and Last Notes (FLN). The upper layer of HCVAE uses Global Variational Autoencoder(G-VAE) to analyze the latent vector sequence generated by the L-CVAE encoder, to explore the musical relationship between the bars, and to produce the song pieced together by multiple music bars generated by the L-CVAE decoder, which makes the song both have musical structure and sense of direction. At the same time, the HCVAE shares a part of itself with the HCGAN to further improve the performance of the generated music. The MIDI-Sandwich is validated on the Nottingham dataset and is able to generate a single-track melody sequence (17x8 beats), which is superior to the length of most of the generated models (8 to 32 beats). Meanwhile, by referring to the experimental methods of many classical kinds of literature, the quality evaluation of the generated music is performed. The above experiments prove the validity of the model.