 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio Mamba: Pretrained Audio State Space Model For Audio Tagging
May 22, 2024



Audio tagging is an important task of mapping audio samples to their corresponding categories. Recently endeavours that exploit transformer models in this field have achieved great success. However, the quadratic self-attention cost limits the scaling of audio transformer models and further constrains the development of more universal audio models. In this paper, we attempt to solve this problem by proposing Audio Mamba, a self-attention-free approach that captures long audio spectrogram dependency with state space models. Our experimental results on two audio-tagging datasets demonstrate the parameter efficiency of Audio Mamba, it achieves comparable results to SOTA audio spectrogram transformers with one third parameters.
ByteComposer: a Human-like Melody Composition Method based on Language Model Agent
Mar 07, 2024Large Language Models (LLM) have shown encouraging progress in multimodal understanding and generation tasks. However, how to design a human-aligned and interpretable melody composition system is still under-explored. To solve this problem, we propose ByteComposer, an agent framework emulating a human's creative pipeline in four separate steps : "Conception Analysis - Draft Composition - Self-Evaluation and Modification - Aesthetic Selection". This framework seamlessly blends the interactive and knowledge-understanding features of LLMs with existing symbolic music generation models, thereby achieving a melody composition agent comparable to human creators. We conduct extensive experiments on GPT4 and several open-source large language models, which substantiate our framework's effectiveness. Furthermore, professional music composers were engaged in multi-dimensional evaluations, the final results demonstrated that across various facets of music composition, ByteComposer agent attains the level of a novice melody composer.
Joint Music and Language Attention Models for Zero-shot Music Tagging
Oct 16, 2023



Music tagging is a task to predict the tags of music recordings. However, previous music tagging research primarily focuses on close-set music tagging tasks which can not be generalized to new tags. In this work, we propose a zero-shot music tagging system modeled by a joint music and language attention (JMLA) model to address the open-set music tagging problem. The JMLA model consists of an audio encoder modeled by a pretrained masked autoencoder and a decoder modeled by a Falcon7B. We introduce preceiver resampler to convert arbitrary length audio into fixed length embeddings. We introduce dense attention connections between encoder and decoder layers to improve the information flow between the encoder and decoder layers. We collect a large-scale music and description dataset from the internet. We propose to use ChatGPT to convert the raw descriptions into formalized and diverse descriptions to train the JMLA models. Our proposed JMLA system achieves a zero-shot audio tagging accuracy of $ 64.82\% $ on the GTZAN dataset, outperforming previous zero-shot systems and achieves comparable results to previous systems on the FMA and the MagnaTagATune datasets.
AgentSims: An Open-Source Sandbox for Large Language Model Evaluation
Aug 08, 2023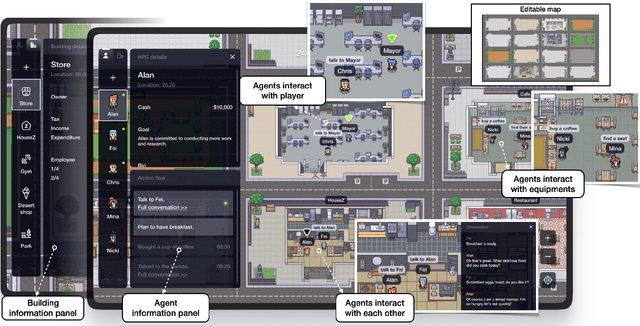
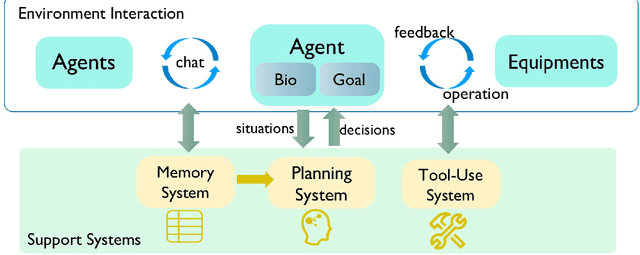
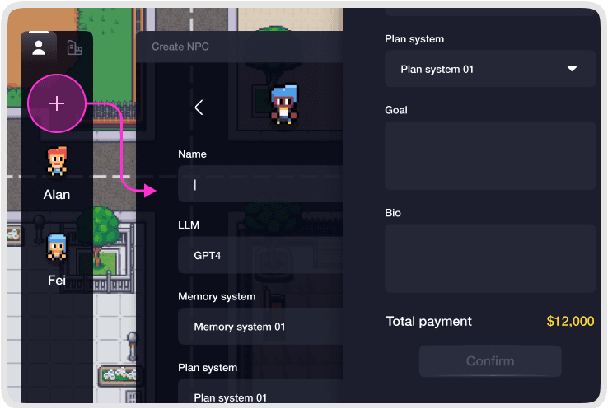
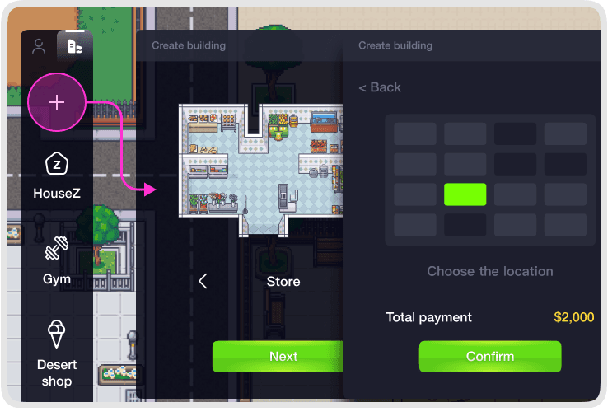
With ChatGPT-like large language models (LLM) prevailing in the community, how to evaluate the ability of LLMs is an open question. Existing evaluation methods suffer from following shortcomings: (1) constrained evaluation abilities, (2) vulnerable benchmarks, (3) unobjective metrics. We suggest that task-based evaluation, where LLM agents complete tasks in a simulated environment, is a one-for-all solution to solve above problems. We present AgentSims, an easy-to-use infrastructure for researchers from all disciplines to test the specific capacities they are interested in. Researchers can build their evaluation tasks by adding agents and buildings on an interactive GUI or deploy and test new support mechanisms, i.e. memory, planning and tool-use systems, by a few lines of codes. Our demo is available at https://agentsims.com .
EduChat: A Large-Scale Language Model-based Chatbot System for Intelligent Education
Aug 05, 2023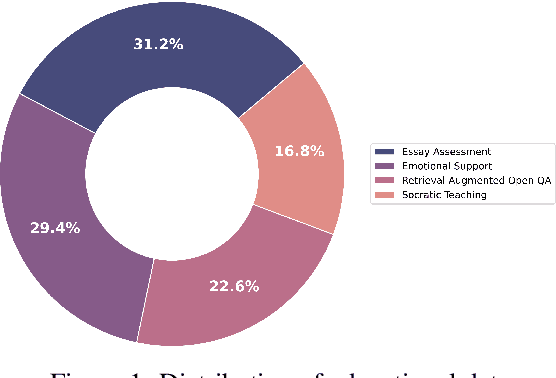



EduChat (https://www.educhat.top/) is a large-scale language model (LLM)-based chatbot system in the education domain. Its goal is to support personalized, fair, and compassionate intelligent education, serving teachers, students, and parents. Guided by theories from psychology and education, it further strengthens educational functions such as open question answering, essay assessment, Socratic teaching, and emotional support based on the existing basic LLMs. Particularly, we learn domain-specific knowledge by pre-training on the educational corpus and stimulate various skills with tool use by fine-tuning on designed system prompts and instructions. Currently, EduChat is available online as an open-source project, with its code, data, and model parameters available on platforms (e.g., GitHub https://github.com/icalk-nlp/EduChat, Hugging Face https://huggingface.co/ecnu-icalk ). We also prepare a demonstration of its capabilities online (https://vimeo.com/851004454). This initiative aims to promote research and applications of LLMs for intelligent education.
Causal Intervention-based Prompt Debiasing for Event Argument Extraction
Oct 04, 2022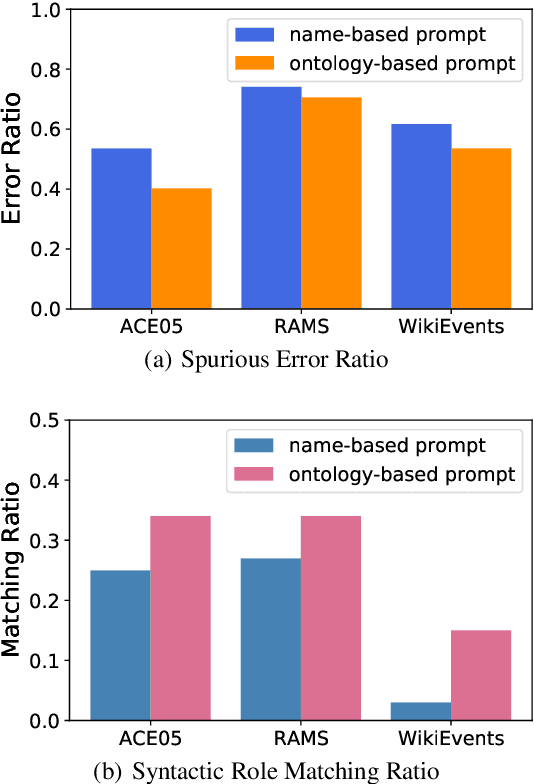
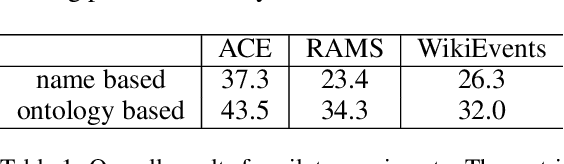

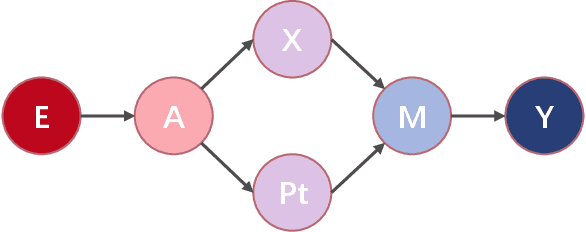
Prompt-based methods have become increasingly popular among information extraction tasks, especially in low-data scenarios. By formatting a finetune task into a pre-training objective, prompt-based methods resolve the data scarce problem effectively. However, seldom do previous research investigate the discrepancy among different prompt formulating strategies. In this work, we compare two kinds of prompts, name-based prompt and ontology-base prompt, and reveal how ontology-base prompt methods exceed its counterpart in zero-shot event argument extraction (EAE) . Furthermore, we analyse the potential risk in ontology-base prompts via a causal view and propose a debias method by causal intervention. Experiments on two benchmarks demonstrate that modified by our debias method, the baseline model becomes both more effective and robust, with significant improvement in the resistance to adversarial attacks.
CUP: Curriculum Learning based Prompt Tuning for Implicit Event Argument Extraction
May 01, 2022
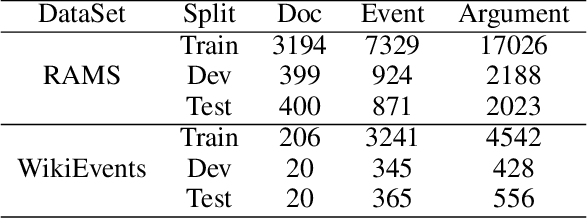
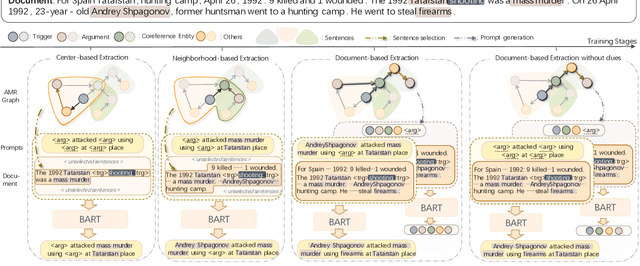
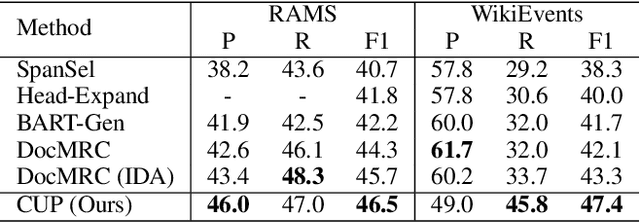
Implicit event argument extraction (EAE) aims to identify arguments that could scatter over the document. Most previous work focuses on learning the direct relations between arguments and the given trigger, while the implicit relations with long-range dependency are not well studied. Moreover, recent neural network based approaches rely on a large amount of labeled data for training, which is unavailable due to the high labelling cost. In this paper, we propose a Curriculum learning based Prompt tuning (CUP) approach, which resolves implicit EAE by four learning stages. The stages are defined according to the relations with the trigger node in a semantic graph, which well captures the long-range dependency between arguments and the trigger. In addition, we integrate a prompt-based encoder-decoder model to elicit related knowledge from pre-trained language models (PLMs) in each stage, where the prompt templates are adapted with the learning progress to enhance the reasoning for arguments. Experimental results on two well-known benchmark datasets show the great advantages of our proposed approach. In particular, we outperform the state-of-the-art models in both fully-supervised and low-data scenarios.
Eliciting Knowledge from Language Models for Event Extraction
Sep 11, 2021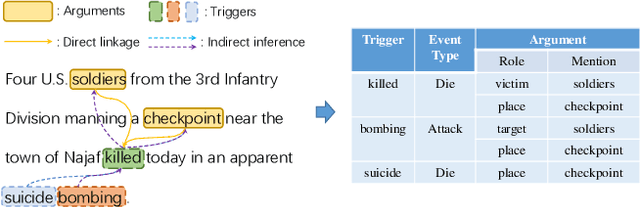
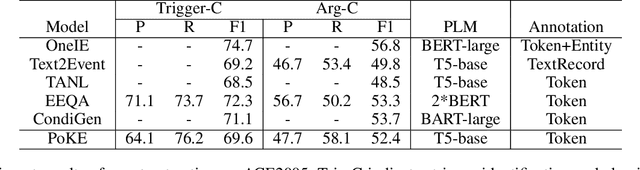
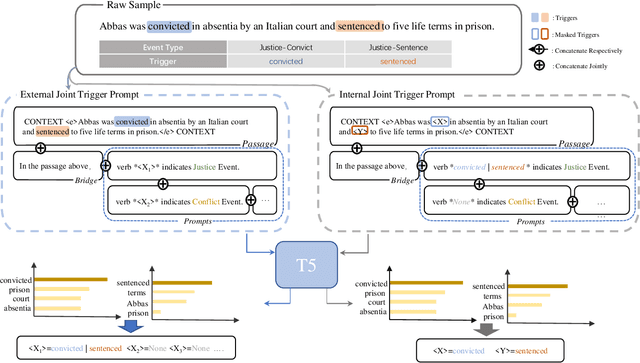
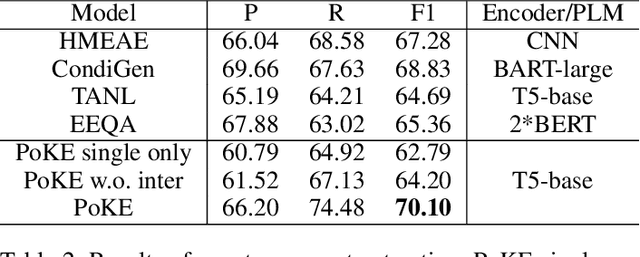
Eliciting knowledge contained in language models via prompt-based learning has shown great potential in many natural language processing tasks, such as text classification and generation. Whereas, the applications for more complex tasks such as event extraction are less studied, since the design of prompt is not straightforward due to the complicated types and arguments. In this paper, we explore to elicit the knowledge from pre-trained language models for event trigger detection and argument extraction. Specifically, we present various joint trigger/argument prompt methods, which can elicit more complementary knowledge by modeling the interactions between different triggers or arguments. The experimental results on the benchmark dataset, namely ACE2005, show the great advantages of our proposed approach. In particular, our approach is superior to the recent advanced methods in the few-shot scenario where only a few samples are used for training.