 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Missing Becomes Structure: Intent-Preserving Policy Completion from Financial KOL Discourse
Apr 15, 2026Key Opinion Leader (KOL) discourse on social media is widely consumed as investment guidance, yet turning it into executable trading strategies without injecting assumptions about unspecified execution decisions remains an open problem. We observe that the gaps in KOL statements are not random deficiencies but a structured separation: KOLs express directional intent (what to buy or sell and why) while leaving execution decisions (when, how much, how long) systematically unspecified. Building on this observation, we propose an intent-preserving policy completion framework that treats KOL discourse as a partial trading policy and uses offline reinforcement learning to complete the missing execution decisions around the KOL-expressed intent. Experiments on multimodal KOL discourse from YouTube and X (2022-2025) show that KICL achieves the best return and Sharpe ratio on both platforms while maintaining zero unsupported entries and zero directional reversals, and ablations confirm that the full framework yields an 18.9% return improvement over the KOL-aligned baseline.
ByteComposer: a Human-like Melody Composition Method based on Language Model Agent
Mar 07, 2024Large Language Models (LLM) have shown encouraging progress in multimodal understanding and generation tasks. However, how to design a human-aligned and interpretable melody composition system is still under-explored. To solve this problem, we propose ByteComposer, an agent framework emulating a human's creative pipeline in four separate steps : "Conception Analysis - Draft Composition - Self-Evaluation and Modification - Aesthetic Selection". This framework seamlessly blends the interactive and knowledge-understanding features of LLMs with existing symbolic music generation models, thereby achieving a melody composition agent comparable to human creators. We conduct extensive experiments on GPT4 and several open-source large language models, which substantiate our framework's effectiveness. Furthermore, professional music composers were engaged in multi-dimensional evaluations, the final results demonstrated that across various facets of music composition, ByteComposer agent attains the level of a novice melody composer.
Semantic Graph Neural Network with Multi-measure Learning for Semi-supervised Classification
Dec 04, 2022


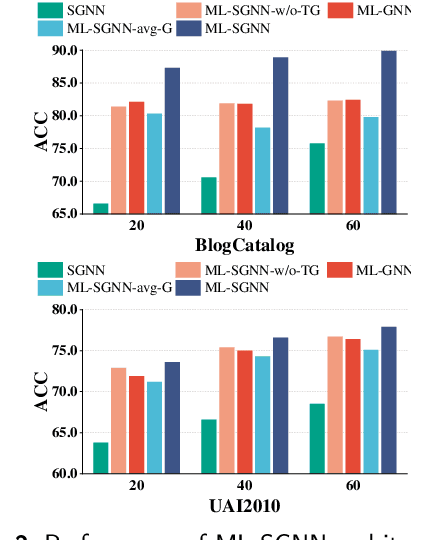
Graph Neural Networks (GNNs) have attracted increasing attention in recent years and have achieved excellent performance in semi-supervised node classification tasks. The success of most GNNs relies on one fundamental assumption, i.e., the original graph structure data is available. However, recent studies have shown that GNNs are vulnerable to the complex underlying structure of the graph, making it necessary to learn comprehensive and robust graph structures for downstream tasks, rather than relying only on the raw graph structure. In light of this, we seek to learn optimal graph structures for downstream tasks and propose a novel framework for semi-supervised classification. Specifically, based on the structural context information of graph and node representations, we encode the complex interactions in semantics and generate semantic graphs to preserve the global structure. Moreover, we develop a novel multi-measure attention layer to optimize the similarity rather than prescribing it a priori, so that the similarity can be adaptively evaluated by integrating measures. These graphs are fused and optimized together with GNN towards semi-supervised classification objective. Extensive experiments and ablation studies on six real-world datasets clearly demonstrate the effectiveness of our proposed model and the contribution of each component.
Towards High-fidelity Singing Voice Conversion with Acoustic Reference and Contrastive Predictive Coding
Oct 10, 2021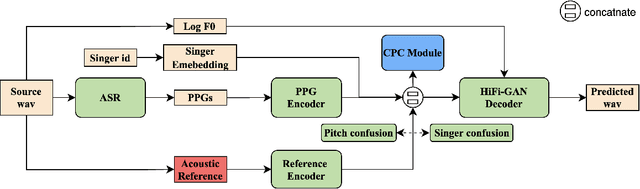
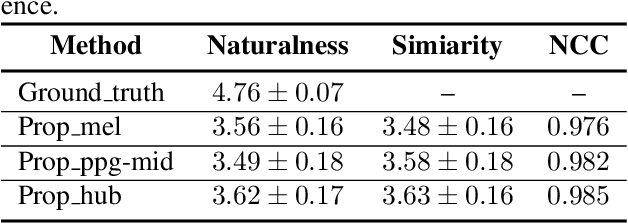
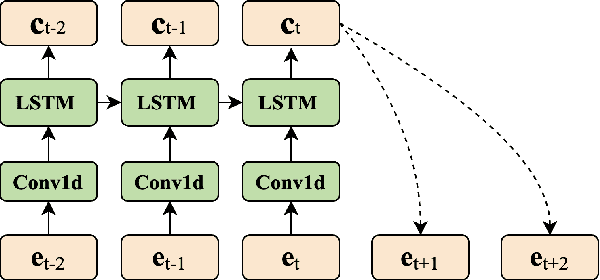

Recently, phonetic posteriorgrams (PPGs) based methods have been quite popular in non-parallel singing voice conversion systems. However, due to the lack of acoustic information in PPGs, style and naturalness of the converted singing voices are still limited. To solve these problems, in this paper, we utilize an acoustic reference encoder to implicitly model singing characteristics. We experiment with different auxiliary features, including mel spectrograms, HuBERT, and the middle hidden feature (PPG-Mid) of pretrained automatic speech recognition (ASR) model, as the input of the reference encoder, and finally find the HuBERT feature is the best choice. In addition, we use contrastive predictive coding (CPC) module to further smooth the voices by predicting future observations in latent space. Experiments show that, compared with the baseline models, our proposed model can significantly improve the naturalness of converted singing voices and the similarity with the target singer. Moreover, our proposed model can also make the speakers with just speech data sing.
PPG-based singing voice conversion with adversarial representation learning
Oct 28, 2020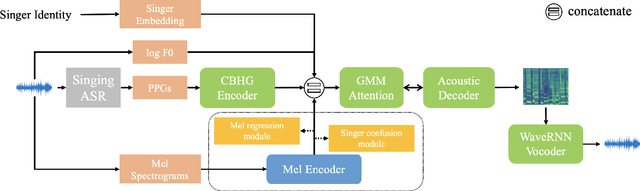
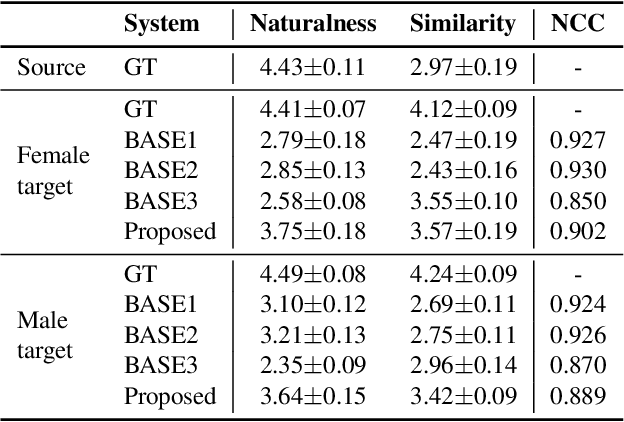
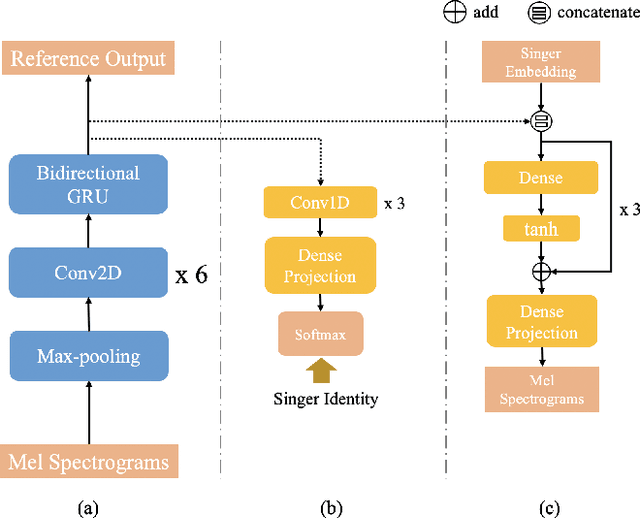
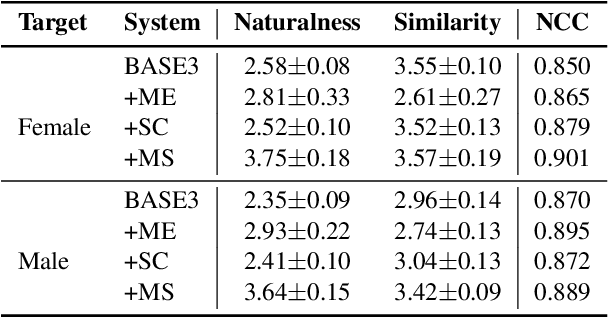
Singing voice conversion (SVC) aims to convert the voice of one singer to that of other singers while keeping the singing content and melody. On top of recent voice conversion works, we propose a novel model to steadily convert songs while keeping their naturalness and intonation. We build an end-to-end architecture, taking phonetic posteriorgrams (PPGs) as inputs and generating mel spectrograms. Specifically, we implement two separate encoders: one encodes PPGs as content, and the other compresses mel spectrograms to supply acoustic and musical information. To improve the performance on timbre and melody, an adversarial singer confusion module and a mel-regressive representation learning module are designed for the model. Objective and subjective experiments are conducted on our private Chinese singing corpus. Comparing with the baselines, our methods can significantly improve the conversion performance in terms of naturalness, melody, and voice similarity. Moreover, our PPG-based method is proved to be robust for noisy sources.
High-resolution Piano Transcription with Pedals by Regressing Onsets and Offsets Times
Oct 05, 2020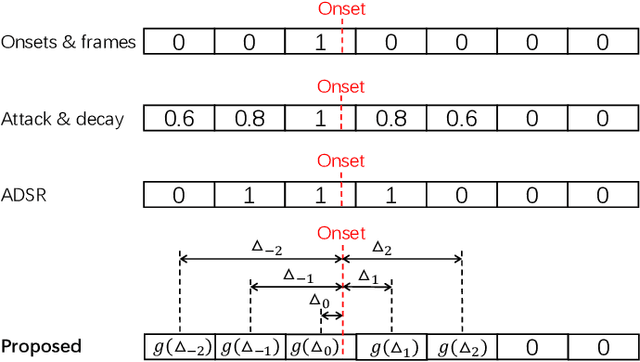
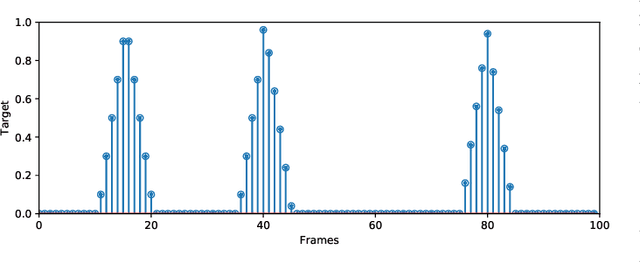
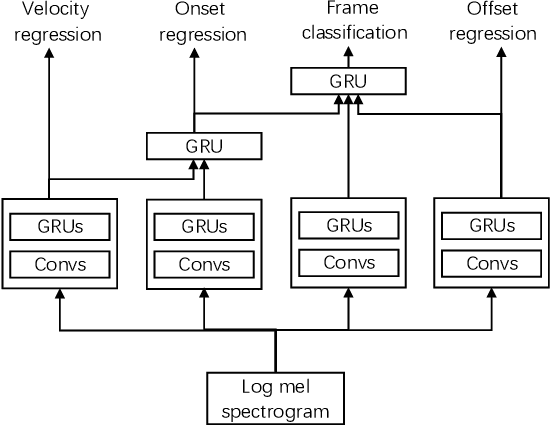

Automatic music transcription (AMT) is the task of transcribing audio recordings into symbolic representations such as Musical Instrument Digital Interface (MIDI). Recently, neural networks based methods have been applied to AMT, and have achieved state-of-the-art result. However, most of previous AMT systems predict the presence or absence of notes in the frames of audio recordings. The transcription resolution of those systems are limited to the hop size time between adjacent frames. In addition, previous AMT systems are sensitive to the misaligned onsets and offsets labels of audio recordings. For high-resolution evaluation, previous works have not investigated AMT systems evaluated with different onsets and offsets tolerances. For piano transcription, there is a lack of research on building AMT systems with both note and pedal transcription. In this article, we propose a high-resolution AMT system trained by regressing precise times of onsets and offsets. In inference, we propose an algorithm to analytically calculate the precise onsets and offsets times of note and pedal events. We build both note and pedal transcription systems with our high-resolution AMT system. We show that our AMT system is robust to misaligned onsets and offsets labels compared to previous systems. Our proposed system achieves an onset F1 of 96.72% on the MAESTRO dataset, outperforming the onsets and frames system from Google of 94.80%. Our system achieves a pedal onset F1 score of 91.86%, and is the first benchmark result on the MAESTRO dataset. We release the source code of our work at https://github.com/bytedance/piano\_transcription.