 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeByteComposer: a Human-like Melody Composition Method based on Language Model Agent
Mar 07, 2024Large Language Models (LLM) have shown encouraging progress in multimodal understanding and generation tasks. However, how to design a human-aligned and interpretable melody composition system is still under-explored. To solve this problem, we propose ByteComposer, an agent framework emulating a human's creative pipeline in four separate steps : "Conception Analysis - Draft Composition - Self-Evaluation and Modification - Aesthetic Selection". This framework seamlessly blends the interactive and knowledge-understanding features of LLMs with existing symbolic music generation models, thereby achieving a melody composition agent comparable to human creators. We conduct extensive experiments on GPT4 and several open-source large language models, which substantiate our framework's effectiveness. Furthermore, professional music composers were engaged in multi-dimensional evaluations, the final results demonstrated that across various facets of music composition, ByteComposer agent attains the level of a novice melody composer.
SLIT: Boosting Audio-Text Pre-Training via Multi-Stage Learning and Instruction Tuning
Feb 20, 2024Audio-text pre-training (ATP) has witnessed remarkable strides across a variety of downstream tasks. Yet, most existing pretrained audio models only specialize in either discriminative tasks or generative tasks. In this study, we develop SLIT, a novel ATP framework which transfers flexibly to both audio-text understanding and generation tasks, bootstrapping audio-text pre-training from frozen pretrained audio encoders and large language models. To bridge the modality gap during pre-training, we leverage Q-Former, which undergoes a multi-stage pre-training process. The first stage enhances audio-text representation learning from a frozen audio encoder, while the second stage boosts audio-to-text generative learning with a frozen language model. Furthermore, we introduce an ATP instruction tuning strategy, which enables flexible and informative feature extraction tailered to the given instructions for different tasks. Experiments show that SLIT achieves superior performances on a variety of audio-text understanding and generation tasks, and even demonstrates strong generalization capabilities when directly applied to zero-shot scenarios.
Joint Music and Language Attention Models for Zero-shot Music Tagging
Oct 16, 2023



Music tagging is a task to predict the tags of music recordings. However, previous music tagging research primarily focuses on close-set music tagging tasks which can not be generalized to new tags. In this work, we propose a zero-shot music tagging system modeled by a joint music and language attention (JMLA) model to address the open-set music tagging problem. The JMLA model consists of an audio encoder modeled by a pretrained masked autoencoder and a decoder modeled by a Falcon7B. We introduce preceiver resampler to convert arbitrary length audio into fixed length embeddings. We introduce dense attention connections between encoder and decoder layers to improve the information flow between the encoder and decoder layers. We collect a large-scale music and description dataset from the internet. We propose to use ChatGPT to convert the raw descriptions into formalized and diverse descriptions to train the JMLA models. Our proposed JMLA system achieves a zero-shot audio tagging accuracy of $ 64.82\% $ on the GTZAN dataset, outperforming previous zero-shot systems and achieves comparable results to previous systems on the FMA and the MagnaTagATune datasets.
ByteCover3: Accurate Cover Song Identification on Short Queries
Mar 21, 2023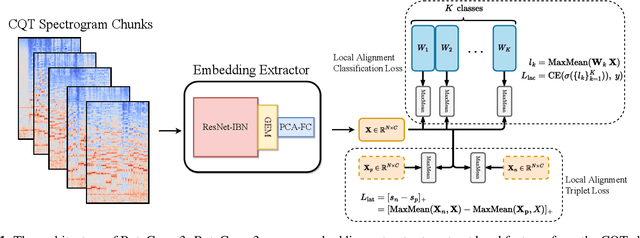
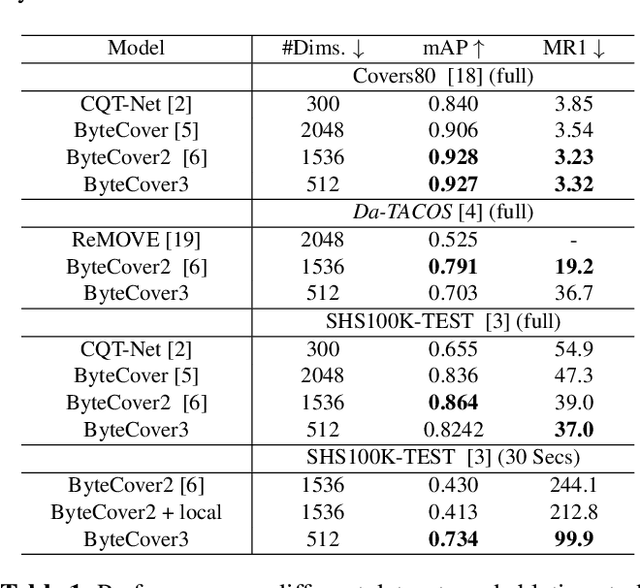
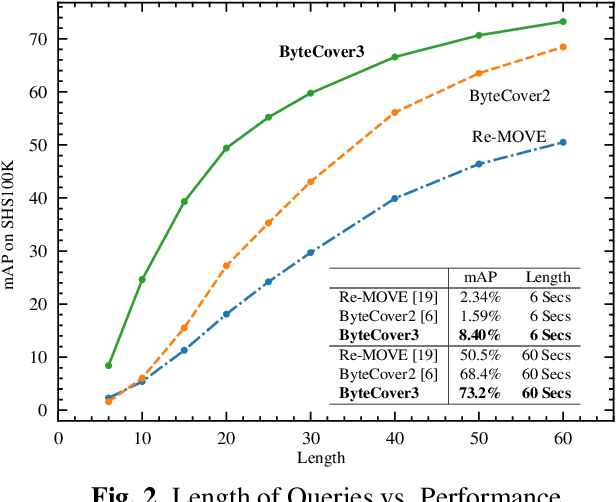
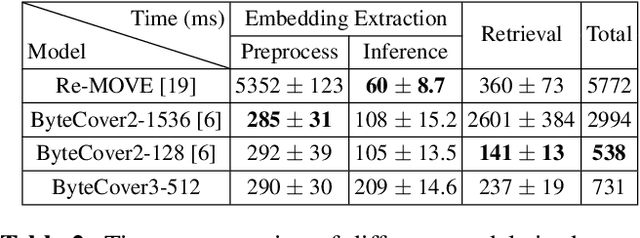
Deep learning based methods have become a paradigm for cover song identification (CSI) in recent years, where the ByteCover systems have achieved state-of-the-art results on all the mainstream datasets of CSI. However, with the burgeon of short videos, many real-world applications require matching short music excerpts to full-length music tracks in the database, which is still under-explored and waiting for an industrial-level solution. In this paper, we upgrade the previous ByteCover systems to ByteCover3 that utilizes local features to further improve the identification performance of short music queries. ByteCover3 is designed with a local alignment loss (LAL) module and a two-stage feature retrieval pipeline, allowing the system to perform CSI in a more precise and efficient way. We evaluated ByteCover3 on multiple datasets with different benchmark settings, where ByteCover3 beat all the compared methods including its previous versions.
Graph Contrastive Learning with Implicit Augmentations
Nov 07, 2022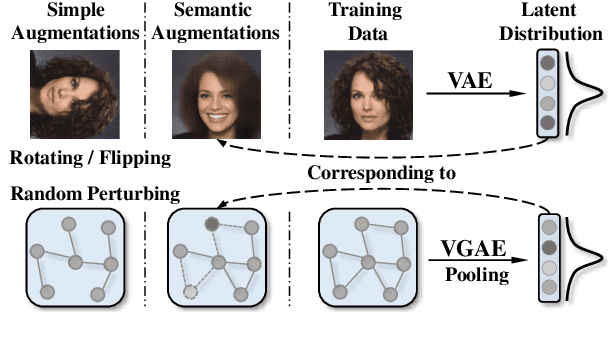
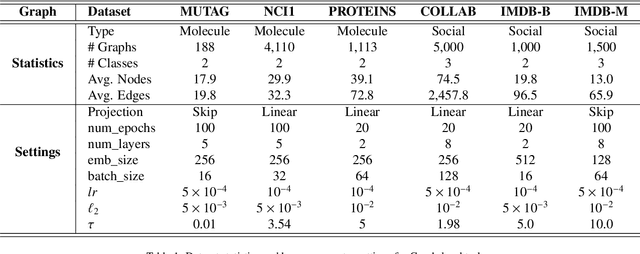
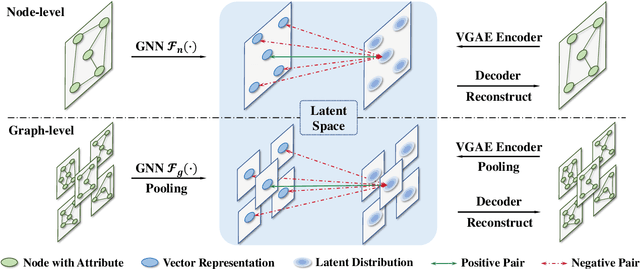
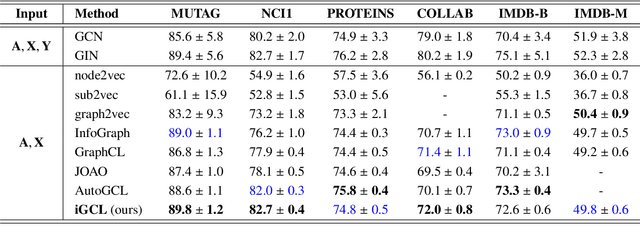
Existing graph contrastive learning methods rely on augmentation techniques based on random perturbations (e.g., randomly adding or dropping edges and nodes). Nevertheless, altering certain edges or nodes can unexpectedly change the graph characteristics, and choosing the optimal perturbing ratio for each dataset requires onerous manual tuning. In this paper, we introduce Implicit Graph Contrastive Learning (iGCL), which utilizes augmentations in the latent space learned from a Variational Graph Auto-Encoder by reconstructing graph topological structure. Importantly, instead of explicitly sampling augmentations from latent distributions, we further propose an upper bound for the expected contrastive loss to improve the efficiency of our learning algorithm. Thus, graph semantics can be preserved within the augmentations in an intelligent way without arbitrary manual design or prior human knowledge. Experimental results on both graph-level and node-level tasks show that the proposed method achieves state-of-the-art performance compared to other benchmarks, where ablation studies in the end demonstrate the effectiveness of modules in iGCL.
HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound Classification and Detection
Feb 02, 2022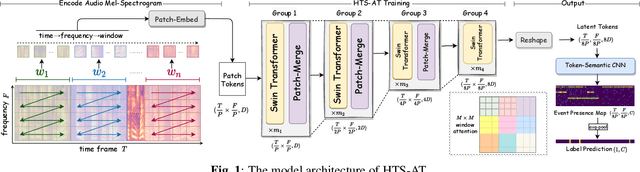
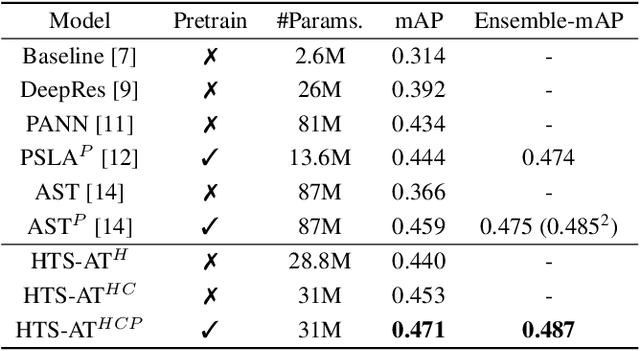
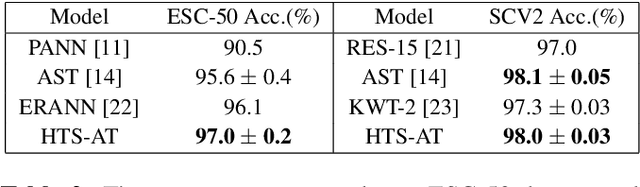

Audio classification is an important task of mapping audio samples into their corresponding labels. Recently, the transformer model with self-attention mechanisms has been adopted in this field. However, existing audio transformers require large GPU memories and long training time, meanwhile relying on pretrained vision models to achieve high performance, which limits the model's scalability in audio tasks. To combat these problems, we introduce HTS-AT: an audio transformer with a hierarchical structure to reduce the model size and training time. It is further combined with a token-semantic module to map final outputs into class featuremaps, thus enabling the model for the audio event detection (i.e. localization in time). We evaluate HTS-AT on three datasets of audio classification where it achieves new state-of-the-art (SOTA) results on AudioSet and ESC-50, and equals the SOTA on Speech Command V2. It also achieves better performance in event localization than the previous CNN-based models. Moreover, HTS-AT requires only 35% model parameters and 15% training time of the previous audio transformer. These results demonstrate the high performance and high efficiency of HTS-AT.
Zero-shot Audio Source Separation through Query-based Learning from Weakly-labeled Data
Jan 12, 2022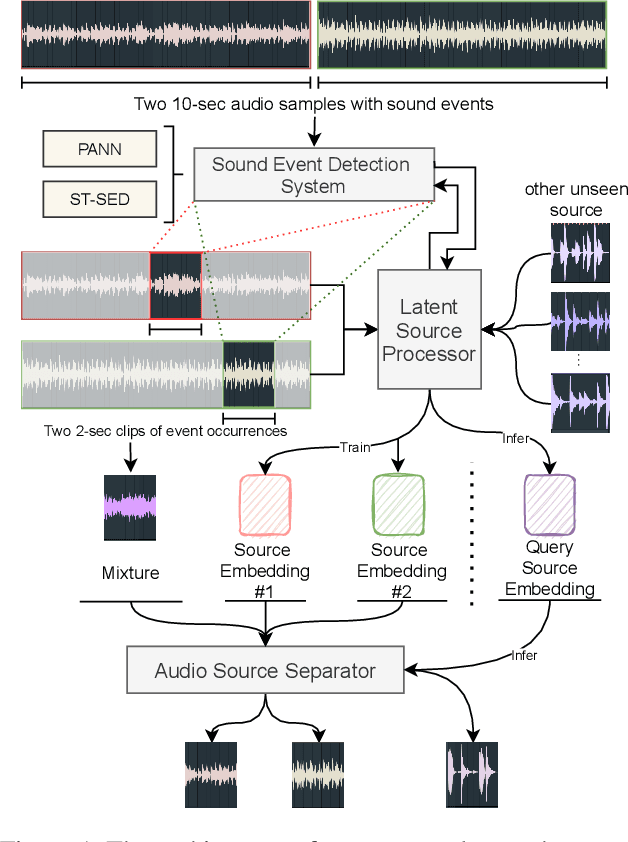
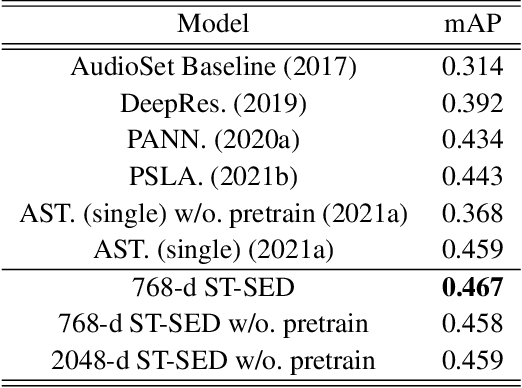
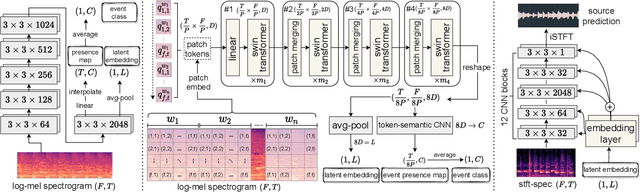
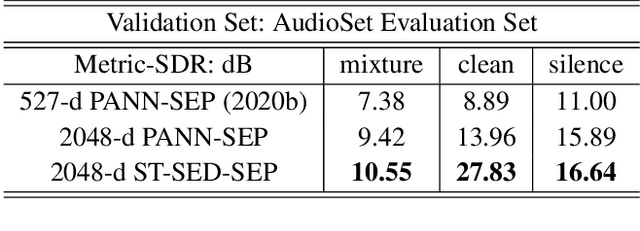
Deep learning techniques for separating audio into different sound sources face several challenges. Standard architectures require training separate models for different types of audio sources. Although some universal separators employ a single model to target multiple sources, they have difficulty generalizing to unseen sources. In this paper, we propose a three-component pipeline to train a universal audio source separator from a large, but weakly-labeled dataset: AudioSet. First, we propose a transformer-based sound event detection system for processing weakly-labeled training data. Second, we devise a query-based audio separation model that leverages this data for model training. Third, we design a latent embedding processor to encode queries that specify audio targets for separation, allowing for zero-shot generalization. Our approach uses a single model for source separation of multiple sound types, and relies solely on weakly-labeled data for training. In addition, the proposed audio separator can be used in a zero-shot setting, learning to separate types of audio sources that were never seen in training. To evaluate the separation performance, we test our model on MUSDB18, while training on the disjoint AudioSet. We further verify the zero-shot performance by conducting another experiment on audio source types that are held-out from training. The model achieves comparable Source-to-Distortion Ratio (SDR) performance to current supervised models in both cases.
Attention-based cross-modal fusion for audio-visual voice activity detection in musical video streams
Jun 21, 2021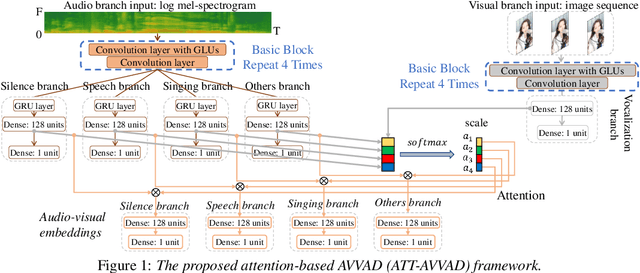

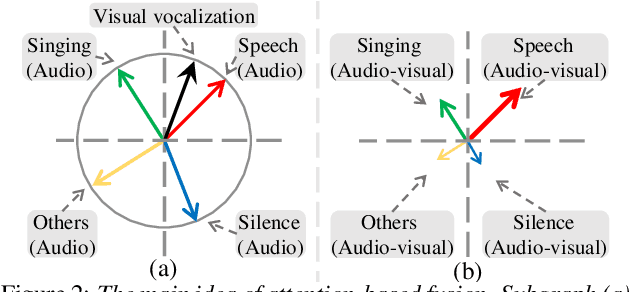
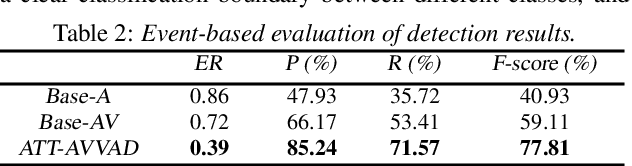
Many previous audio-visual voice-related works focus on speech, ignoring the singing voice in the growing number of musical video streams on the Internet. For processing diverse musical video data, voice activity detection is a necessary step. This paper attempts to detect the speech and singing voices of target performers in musical video streams using audiovisual information. To integrate information of audio and visual modalities, a multi-branch network is proposed to learn audio and image representations, and the representations are fused by attention based on semantic similarity to shape the acoustic representations through the probability of anchor vocalization. Experiments show the proposed audio-visual multi-branch network far outperforms the audio-only model in challenging acoustic environments, indicating the cross-modal information fusion based on semantic correlation is sensible and successful.
ByteCover: Cover Song Identification via Multi-Loss Training
Oct 27, 2020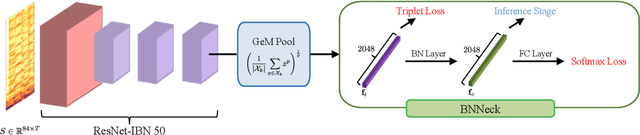
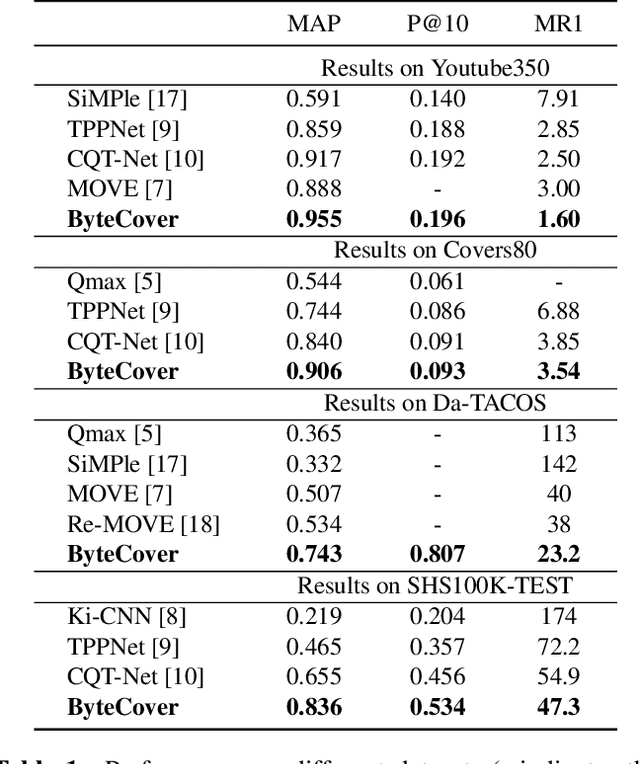
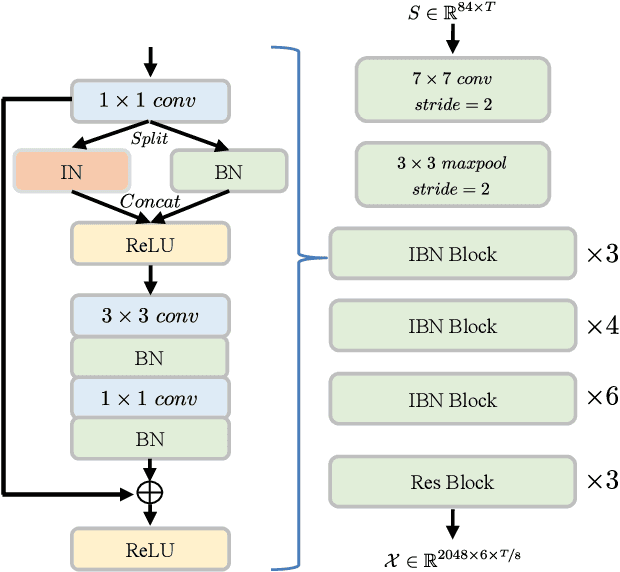

We present in this paper ByteCover, which is a new feature learning method for cover song identification (CSI). ByteCover is built based on the classical ResNet model, and two major improvements are designed to further enhance the capability of the model for CSI. In the first improvement, we introduce the integration of instance normalization (IN) and batch normalization (BN) to build IBN blocks, which are major components of our ResNet-IBN model. With the help of the IBN blocks, our CSI model can learn features that are invariant to the changes of musical attributes such as key, tempo, timbre and genre, while preserving the version information. In the second improvement, we employ the BNNeck method to allow a multi-loss training and encourage our method to jointly optimize a classification loss and a triplet loss, and by this means, the inter-class discrimination and intra-class compactness of cover songs, can be ensured at the same time. A set of experiments demonstrated the effectiveness and efficiency of ByteCover on multiple datasets, and in the Da-TACOS dataset, ByteCover outperformed the best competitive system by 20.9\%.
Contrastive Unsupervised Learning for Audio Fingerprinting
Oct 26, 2020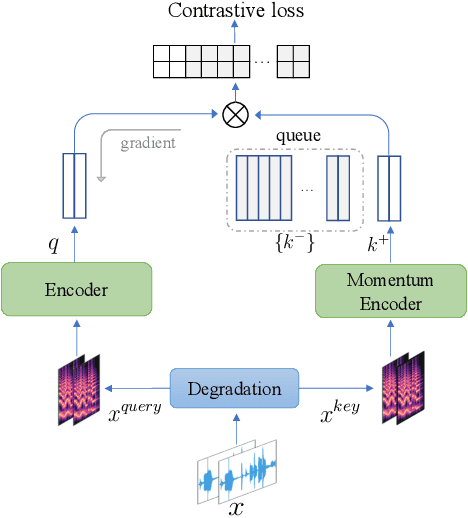
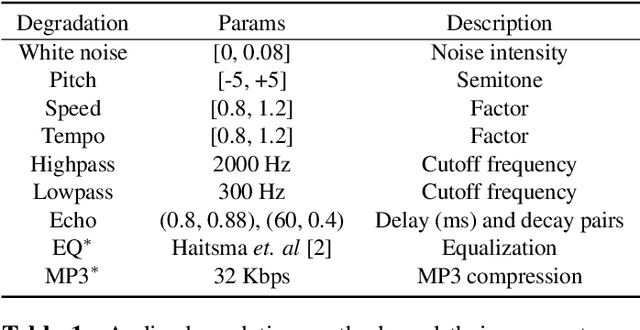
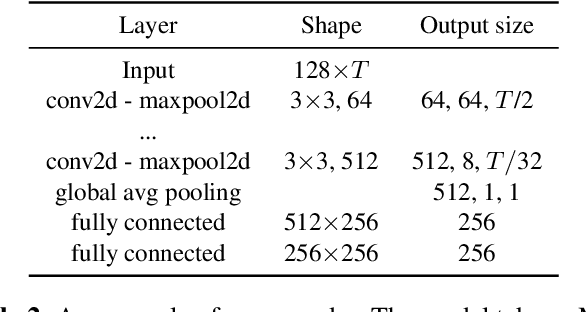
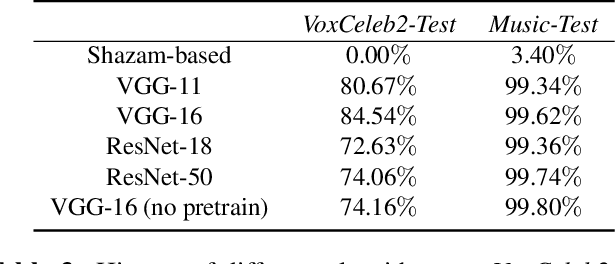
The rise of video-sharing platforms has attracted more and more people to shoot videos and upload them to the Internet. These videos mostly contain a carefully-edited background audio track, where serious speech change, pitch shifting and various types of audio effects may involve, and existing audio identification systems may fail to recognize the audio. To solve this problem, in this paper, we introduce the idea of contrastive learning to the task of audio fingerprinting (AFP). Contrastive learning is an unsupervised approach to learn representations that can effectively group similar samples and discriminate dissimilar ones. In our work, we consider an audio track and its differently distorted versions as similar while considering different audio tracks as dissimilar. Based on the momentum contrast (MoCo) framework, we devise a contrastive learning method for AFP, which can generate fingerprints that are both discriminative and robust. A set of experiments showed that our AFP method is effective for audio identification, with robustness to serious audio distortions, including the challenging speed change and pitch shifting.