 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Unsupervised Learning for Audio Fingerprinting
Paper and Code
Oct 26, 2020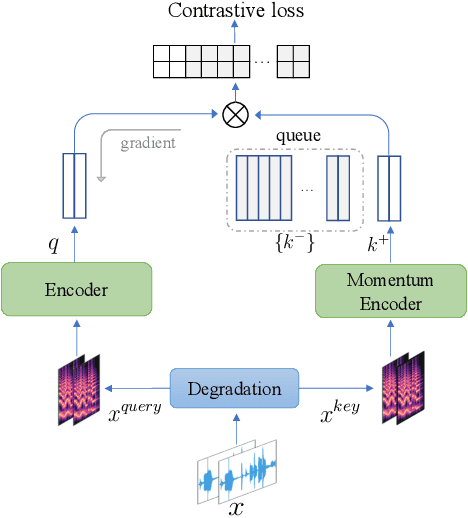
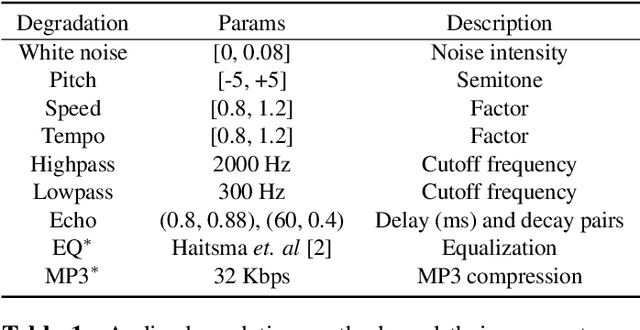
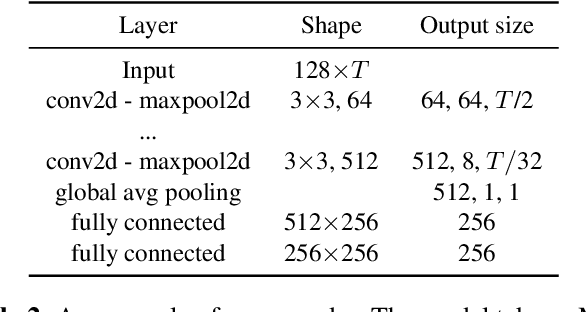
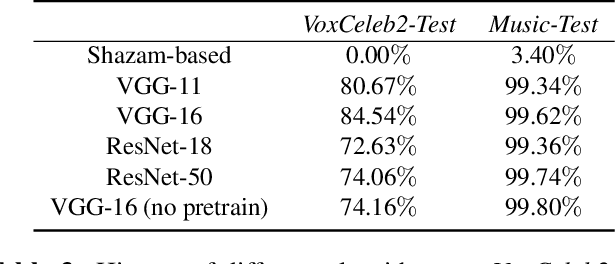
The rise of video-sharing platforms has attracted more and more people to shoot videos and upload them to the Internet. These videos mostly contain a carefully-edited background audio track, where serious speech change, pitch shifting and various types of audio effects may involve, and existing audio identification systems may fail to recognize the audio. To solve this problem, in this paper, we introduce the idea of contrastive learning to the task of audio fingerprinting (AFP). Contrastive learning is an unsupervised approach to learn representations that can effectively group similar samples and discriminate dissimilar ones. In our work, we consider an audio track and its differently distorted versions as similar while considering different audio tracks as dissimilar. Based on the momentum contrast (MoCo) framework, we devise a contrastive learning method for AFP, which can generate fingerprints that are both discriminative and robust. A set of experiments showed that our AFP method is effective for audio identification, with robustness to serious audio distortions, including the challenging speed change and pitch shifting.