 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Kimi-Audio Technical Report
Apr 25, 2025



We present Kimi-Audio, an open-source audio foundation model that excels in audio understanding, generation, and conversation. We detail the practices in building Kimi-Audio, including model architecture, data curation, training recipe, inference deployment, and evaluation. Specifically, we leverage a 12.5Hz audio tokenizer, design a novel LLM-based architecture with continuous features as input and discrete tokens as output, and develop a chunk-wise streaming detokenizer based on flow matching. We curate a pre-training dataset that consists of more than 13 million hours of audio data covering a wide range of modalities including speech, sound, and music, and build a pipeline to construct high-quality and diverse post-training data. Initialized from a pre-trained LLM, Kimi-Audio is continual pre-trained on both audio and text data with several carefully designed tasks, and then fine-tuned to support a diverse of audio-related tasks. Extensive evaluation shows that Kimi-Audio achieves state-of-the-art performance on a range of audio benchmarks including speech recognition, audio understanding, audio question answering, and speech conversation. We release the codes, model checkpoints, as well as the evaluation toolkits in https://github.com/MoonshotAI/Kimi-Audio.
ECBench: Can Multi-modal Foundation Models Understand the Egocentric World? A Holistic Embodied Cognition Benchmark
Jan 09, 2025



The enhancement of generalization in robots by large vision-language models (LVLMs) is increasingly evident. Therefore, the embodied cognitive abilities of LVLMs based on egocentric videos are of great interest. However, current datasets for embodied video question answering lack comprehensive and systematic evaluation frameworks. Critical embodied cognitive issues, such as robotic self-cognition, dynamic scene perception, and hallucination, are rarely addressed. To tackle these challenges, we propose ECBench, a high-quality benchmark designed to systematically evaluate the embodied cognitive abilities of LVLMs. ECBench features a diverse range of scene video sources, open and varied question formats, and 30 dimensions of embodied cognition. To ensure quality, balance, and high visual dependence, ECBench uses class-independent meticulous human annotation and multi-round question screening strategies. Additionally, we introduce ECEval, a comprehensive evaluation system that ensures the fairness and rationality of the indicators. Utilizing ECBench, we conduct extensive evaluations of proprietary, open-source, and task-specific LVLMs. ECBench is pivotal in advancing the embodied cognitive capabilities of LVLMs, laying a solid foundation for developing reliable core models for embodied agents. All data and code are available at https://github.com/Rh-Dang/ECBench.
Addressing Representation Collapse in Vector Quantized Models with One Linear Layer
Nov 04, 2024
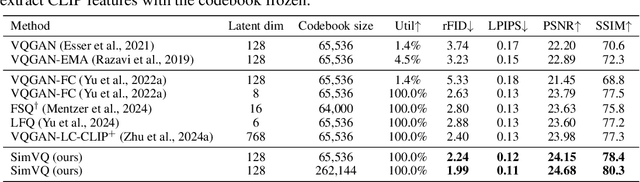
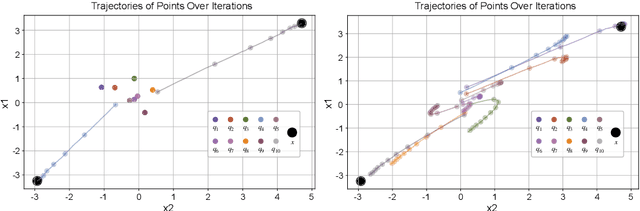
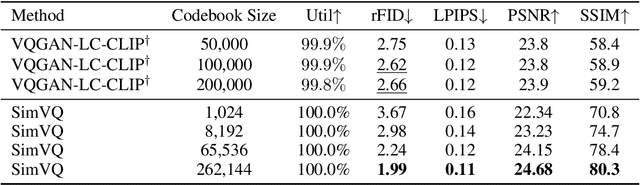
Vector Quantization (VQ) is a widely used method for converting continuous representations into discrete codes, which has become fundamental in unsupervised representation learning and latent generative models. However, VQ models are often hindered by the problem of representation collapse in the latent space, which leads to low codebook utilization and limits the scalability of the codebook for large-scale training. Existing methods designed to mitigate representation collapse typically reduce the dimensionality of latent space at the expense of model capacity, which do not fully resolve the core issue. In this study, we conduct a theoretical analysis of representation collapse in VQ models and identify its primary cause as the disjoint optimization of the codebook, where only a small subset of code vectors are updated through gradient descent. To address this issue, we propose \textbf{SimVQ}, a novel method which reparameterizes the code vectors through a linear transformation layer based on a learnable latent basis. This transformation optimizes the \textit{entire linear space} spanned by the codebook, rather than merely updating \textit{the code vector} selected by the nearest-neighbor search in vanilla VQ models. Although it is commonly understood that the multiplication of two linear matrices is equivalent to applying a single linear layer, our approach works surprisingly well in resolving the collapse issue in VQ models with just one linear layer. We validate the efficacy of SimVQ through extensive experiments across various modalities, including image and audio data with different model architectures. Our code is available at \url{https://github.com/youngsheen/SimVQ}.
Chain of Ideas: Revolutionizing Research Via Novel Idea Development with LLM Agents
Oct 25, 2024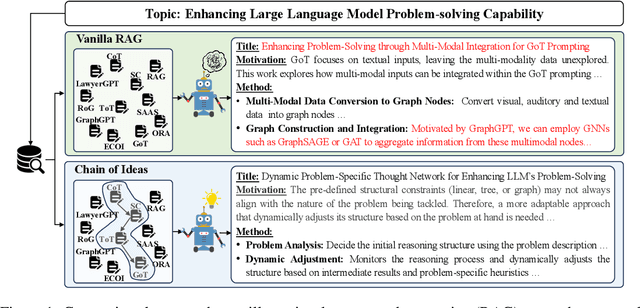

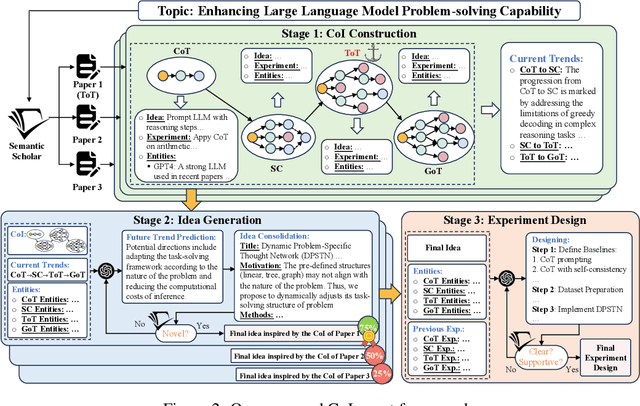
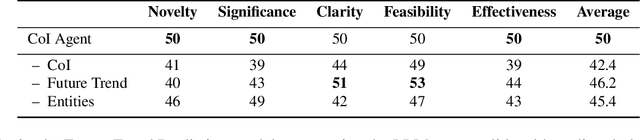
Effective research ideation is a critical step for scientific research. However, the exponential increase in scientific literature makes it challenging for researchers to stay current with recent advances and identify meaningful research directions. Recent developments in large language models~(LLMs) suggest a promising avenue for automating the generation of novel research ideas. However, existing methods for idea generation either trivially prompt LLMs or directly expose LLMs to extensive literature without indicating useful information. Inspired by the research process of human researchers, we propose a Chain-of-Ideas~(CoI) agent, an LLM-based agent that organizes relevant literature in a chain structure to effectively mirror the progressive development in a research domain. This organization facilitates LLMs to capture the current advancements in research, thereby enhancing their ideation capabilities. Furthermore, we propose Idea Arena, an evaluation protocol that can comprehensively evaluate idea generation methods from different perspectives, aligning closely with the preferences of human researchers. Experimental results indicate that the CoI agent consistently outperforms other methods and shows comparable quality as humans in research idea generation. Moreover, our CoI agent is budget-friendly, with a minimum cost of \$0.50 to generate a candidate idea and its corresponding experimental design.
Chain of Ideas: Revolutionizing Research in Novel Idea Development with LLM Agents
Oct 17, 2024Effective research ideation is a critical step for scientific research. However, the exponential increase in scientific literature makes it challenging for researchers to stay current with recent advances and identify meaningful research directions. Recent developments in large language models~(LLMs) suggest a promising avenue for automating the generation of novel research ideas. However, existing methods for idea generation either trivially prompt LLMs or directly expose LLMs to extensive literature without indicating useful information. Inspired by the research process of human researchers, we propose a Chain-of-Ideas~(CoI) agent, an LLM-based agent that organizes relevant literature in a chain structure to effectively mirror the progressive development in a research domain. This organization facilitates LLMs to capture the current advancements in research, thereby enhancing their ideation capabilities. Furthermore, we propose Idea Arena, an evaluation protocol that can comprehensively evaluate idea generation methods from different perspectives, aligning closely with the preferences of human researchers. Experimental results indicate that the CoI agent consistently outperforms other methods and shows comparable quality as humans in research idea generation. Moreover, our CoI agent is budget-friendly, with a minimum cost of \$0.50 to generate a candidate idea and its corresponding experimental design.
DiffATR: Diffusion-based Generative Modeling for Audio-Text Retrieval
Sep 16, 2024



Existing audio-text retrieval (ATR) methods are essentially discriminative models that aim to maximize the conditional likelihood, represented as p(candidates|query). Nevertheless, this methodology fails to consider the intrinsic data distribution p(query), leading to difficulties in discerning out-of-distribution data. In this work, we attempt to tackle this constraint through a generative perspective and model the relationship between audio and text as their joint probability p(candidates,query). To this end, we present a diffusion-based ATR framework (DiffATR), which models ATR as an iterative procedure that progressively generates joint distribution from noise. Throughout its training phase, DiffATR is optimized from both generative and discriminative viewpoints: the generator is refined through a generation loss, while the feature extractor benefits from a contrastive loss, thus combining the merits of both methodologies. Experiments on the AudioCaps and Clotho datasets with superior performances, verify the effectiveness of our approach. Notably, without any alterations, our DiffATR consistently exhibits strong performance in out-of-domain retrieval settings.
Audio-text Retrieval with Transformer-based Hierarchical Alignment and Disentangled Cross-modal Representation
Sep 14, 2024


Most existing audio-text retrieval (ATR) approaches typically rely on a single-level interaction to associate audio and text, limiting their ability to align different modalities and leading to suboptimal matches. In this work, we present a novel ATR framework that leverages two-stream Transformers in conjunction with a Hierarchical Alignment (THA) module to identify multi-level correspondences of different Transformer blocks between audio and text. Moreover, current ATR methods mainly focus on learning a global-level representation, missing out on intricate details to capture audio occurrences that correspond to textual semantics. To bridge this gap, we introduce a Disentangled Cross-modal Representation (DCR) approach that disentangles high-dimensional features into compact latent factors to grasp fine-grained audio-text semantic correlations. Additionally, we develop a confidence-aware (CA) module to estimate the confidence of each latent factor pair and adaptively aggregate cross-modal latent factors to achieve local semantic alignment. Experiments show that our THA effectively boosts ATR performance, with the DCR approach further contributing to consistent performance gains.
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Jun 11, 2024



In this paper, we present the VideoLLaMA 2, a set of Video Large Language Models (Video-LLMs) designed to enhance spatial-temporal modeling and audio understanding in video and audio-oriented tasks. Building upon its predecessor, VideoLLaMA 2 incorporates a tailor-made Spatial-Temporal Convolution (STC) connector, which effectively captures the intricate spatial and temporal dynamics of video data. Additionally, we integrate an Audio Branch into the model through joint training, thereby enriching the multimodal understanding capabilities of the model by seamlessly incorporating audio cues. Comprehensive evaluations on multiple-choice video question answering (MC-VQA), open-ended video question answering (OE-VQA), and video captioning (VC) tasks demonstrate that VideoLLaMA 2 consistently achieves competitive results among open-source models and even gets close to some proprietary models on several benchmarks. Furthermore, VideoLLaMA 2 exhibits reasonable improvements in audio-only and audio-video question-answering (AQA & OE-AVQA) benchmarks over existing models. These advancements underline VideoLLaMA 2's superior performance in multimodal comprehension, setting a new standard for intelligent video analysis systems. All models are public to facilitate further research.
SLIT: Boosting Audio-Text Pre-Training via Multi-Stage Learning and Instruction Tuning
Feb 20, 2024Audio-text pre-training (ATP) has witnessed remarkable strides across a variety of downstream tasks. Yet, most existing pretrained audio models only specialize in either discriminative tasks or generative tasks. In this study, we develop SLIT, a novel ATP framework which transfers flexibly to both audio-text understanding and generation tasks, bootstrapping audio-text pre-training from frozen pretrained audio encoders and large language models. To bridge the modality gap during pre-training, we leverage Q-Former, which undergoes a multi-stage pre-training process. The first stage enhances audio-text representation learning from a frozen audio encoder, while the second stage boosts audio-to-text generative learning with a frozen language model. Furthermore, we introduce an ATP instruction tuning strategy, which enables flexible and informative feature extraction tailered to the given instructions for different tasks. Experiments show that SLIT achieves superior performances on a variety of audio-text understanding and generation tasks, and even demonstrates strong generalization capabilities when directly applied to zero-shot scenarios.