 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRynnBrain: Open Embodied Foundation Models
Feb 13, 2026Despite rapid progress in multimodal foundation models, embodied intelligence community still lacks a unified, physically grounded foundation model that integrates perception, reasoning, and planning within real-world spatial-temporal dynamics. We introduce RynnBrain, an open-source spatiotemporal foundation model for embodied intelligence. RynnBrain strengthens four core capabilities in a unified framework: comprehensive egocentric understanding, diverse spatiotemporal localization, physically grounded reasoning, and physics-aware planning. The RynnBrain family comprises three foundation model scales (2B, 8B, and 30B-A3B MoE) and four post-trained variants tailored for downstream embodied tasks (i.e., RynnBrain-Nav, RynnBrain-Plan, and RynnBrain-VLA) or complex spatial reasoning tasks (i.e., RynnBrain-CoP). In terms of extensive evaluations on 20 embodied benchmarks and 8 general vision understanding benchmarks, our RynnBrain foundation models largely outperform existing embodied foundation models by a significant margin. The post-trained model suite further substantiates two key potentials of the RynnBrain foundation model: (i) enabling physically grounded reasoning and planning, and (ii) serving as a strong pretrained backbone that can be efficiently adapted to diverse embodied tasks.
RynnVLA-001: Using Human Demonstrations to Improve Robot Manipulation
Sep 18, 2025This paper presents RynnVLA-001, a vision-language-action(VLA) model built upon large-scale video generative pretraining from human demonstrations. We propose a novel two-stage pretraining methodology. The first stage, Ego-Centric Video Generative Pretraining, trains an Image-to-Video model on 12M ego-centric manipulation videos to predict future frames conditioned on an initial frame and a language instruction. The second stage, Human-Centric Trajectory-Aware Modeling, extends this by jointly predicting future keypoint trajectories, thereby effectively bridging visual frame prediction with action prediction. Furthermore, to enhance action representation, we propose ActionVAE, a variational autoencoder that compresses sequences of actions into compact latent embeddings, reducing the complexity of the VLA output space. When finetuned on the same downstream robotics datasets, RynnVLA-001 achieves superior performance over state-of-the-art baselines, demonstrating that the proposed pretraining strategy provides a more effective initialization for VLA models.
Towards Affordance-Aware Robotic Dexterous Grasping with Human-like Priors
Aug 12, 2025A dexterous hand capable of generalizable grasping objects is fundamental for the development of general-purpose embodied AI. However, previous methods focus narrowly on low-level grasp stability metrics, neglecting affordance-aware positioning and human-like poses which are crucial for downstream manipulation. To address these limitations, we propose AffordDex, a novel framework with two-stage training that learns a universal grasping policy with an inherent understanding of both motion priors and object affordances. In the first stage, a trajectory imitator is pre-trained on a large corpus of human hand motions to instill a strong prior for natural movement. In the second stage, a residual module is trained to adapt these general human-like motions to specific object instances. This refinement is critically guided by two components: our Negative Affordance-aware Segmentation (NAA) module, which identifies functionally inappropriate contact regions, and a privileged teacher-student distillation process that ensures the final vision-based policy is highly successful. Extensive experiments demonstrate that AffordDex not only achieves universal dexterous grasping but also remains remarkably human-like in posture and functionally appropriate in contact location. As a result, AffordDex significantly outperforms state-of-the-art baselines across seen objects, unseen instances, and even entirely novel categories.
WorldVLA: Towards Autoregressive Action World Model
Jun 26, 2025We present WorldVLA, an autoregressive action world model that unifies action and image understanding and generation. Our WorldVLA intergrates Vision-Language-Action (VLA) model and world model in one single framework. The world model predicts future images by leveraging both action and image understanding, with the purpose of learning the underlying physics of the environment to improve action generation. Meanwhile, the action model generates the subsequent actions based on image observations, aiding in visual understanding and in turn helps visual generation of the world model. We demonstrate that WorldVLA outperforms standalone action and world models, highlighting the mutual enhancement between the world model and the action model. In addition, we find that the performance of the action model deteriorates when generating sequences of actions in an autoregressive manner. This phenomenon can be attributed to the model's limited generalization capability for action prediction, leading to the propagation of errors from earlier actions to subsequent ones. To address this issue, we propose an attention mask strategy that selectively masks prior actions during the generation of the current action, which shows significant performance improvement in the action chunk generation task.
ZeroSearch: Incentivize the Search Capability of LLMs without Searching
May 07, 2025Effective information searching is essential for enhancing the reasoning and generation capabilities of large language models (LLMs). Recent research has explored using reinforcement learning (RL) to improve LLMs' search capabilities by interacting with live search engines in real-world environments. While these approaches show promising results, they face two major challenges: (1) Uncontrolled Document Quality: The quality of documents returned by search engines is often unpredictable, introducing noise and instability into the training process. (2) Prohibitively High API Costs: RL training requires frequent rollouts, potentially involving hundreds of thousands of search requests, which incur substantial API expenses and severely constrain scalability. To address these challenges, we introduce ZeroSearch, a reinforcement learning framework that incentivizes the search capabilities of LLMs without interacting with real search engines. Our approach begins with lightweight supervised fine-tuning to transform the LLM into a retrieval module capable of generating both relevant and noisy documents in response to a query. During RL training, we employ a curriculum-based rollout strategy that incrementally degrades the quality of generated documents, progressively eliciting the model's reasoning ability by exposing it to increasingly challenging retrieval scenarios. Extensive experiments demonstrate that ZeroSearch effectively incentivizes the search capabilities of LLMs using a 3B LLM as the retrieval module. Remarkably, a 7B retrieval module achieves comparable performance to the real search engine, while a 14B retrieval module even surpasses it. Furthermore, it generalizes well across both base and instruction-tuned models of various parameter sizes and is compatible with a wide range of RL algorithms.
Chain of Ideas: Revolutionizing Research Via Novel Idea Development with LLM Agents
Oct 25, 2024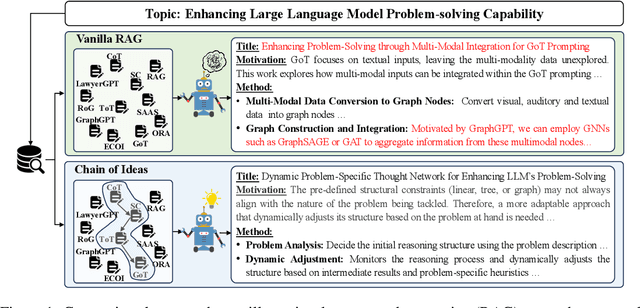

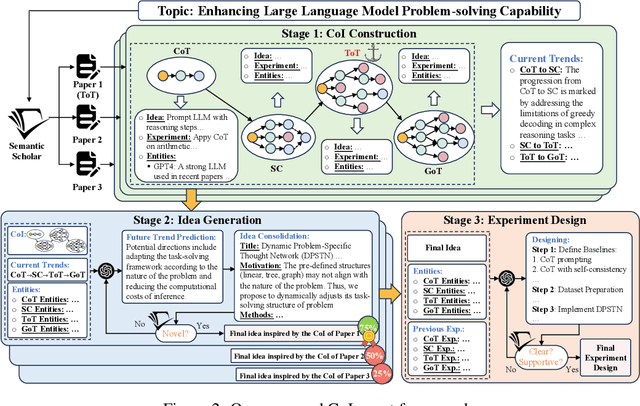
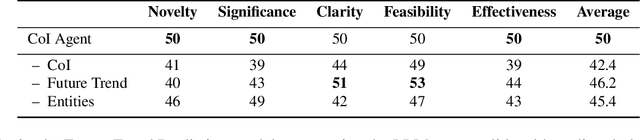
Effective research ideation is a critical step for scientific research. However, the exponential increase in scientific literature makes it challenging for researchers to stay current with recent advances and identify meaningful research directions. Recent developments in large language models~(LLMs) suggest a promising avenue for automating the generation of novel research ideas. However, existing methods for idea generation either trivially prompt LLMs or directly expose LLMs to extensive literature without indicating useful information. Inspired by the research process of human researchers, we propose a Chain-of-Ideas~(CoI) agent, an LLM-based agent that organizes relevant literature in a chain structure to effectively mirror the progressive development in a research domain. This organization facilitates LLMs to capture the current advancements in research, thereby enhancing their ideation capabilities. Furthermore, we propose Idea Arena, an evaluation protocol that can comprehensively evaluate idea generation methods from different perspectives, aligning closely with the preferences of human researchers. Experimental results indicate that the CoI agent consistently outperforms other methods and shows comparable quality as humans in research idea generation. Moreover, our CoI agent is budget-friendly, with a minimum cost of \$0.50 to generate a candidate idea and its corresponding experimental design.
Chain of Ideas: Revolutionizing Research in Novel Idea Development with LLM Agents
Oct 17, 2024Effective research ideation is a critical step for scientific research. However, the exponential increase in scientific literature makes it challenging for researchers to stay current with recent advances and identify meaningful research directions. Recent developments in large language models~(LLMs) suggest a promising avenue for automating the generation of novel research ideas. However, existing methods for idea generation either trivially prompt LLMs or directly expose LLMs to extensive literature without indicating useful information. Inspired by the research process of human researchers, we propose a Chain-of-Ideas~(CoI) agent, an LLM-based agent that organizes relevant literature in a chain structure to effectively mirror the progressive development in a research domain. This organization facilitates LLMs to capture the current advancements in research, thereby enhancing their ideation capabilities. Furthermore, we propose Idea Arena, an evaluation protocol that can comprehensively evaluate idea generation methods from different perspectives, aligning closely with the preferences of human researchers. Experimental results indicate that the CoI agent consistently outperforms other methods and shows comparable quality as humans in research idea generation. Moreover, our CoI agent is budget-friendly, with a minimum cost of \$0.50 to generate a candidate idea and its corresponding experimental design.
AIGB: Generative Auto-bidding via Diffusion Modeling
May 25, 2024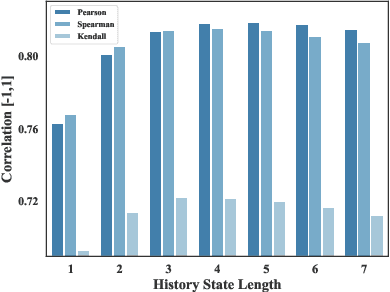
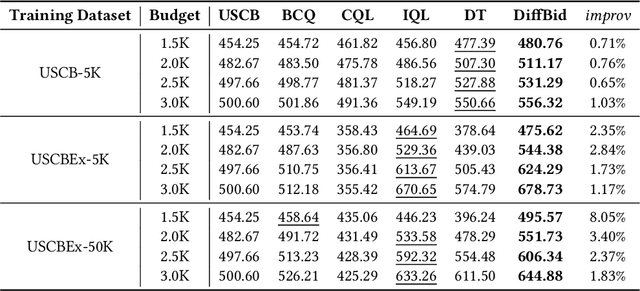
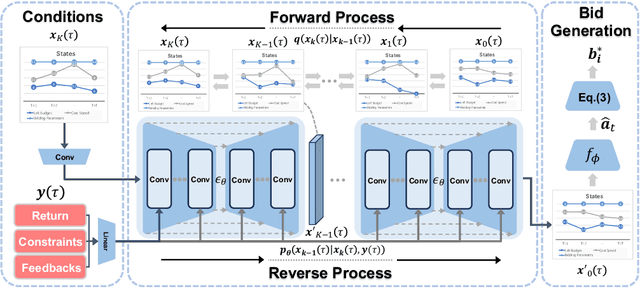
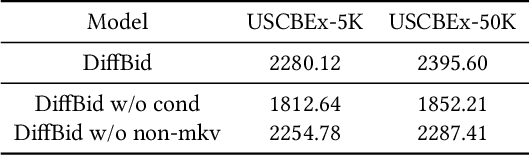
Auto-bidding plays a crucial role in facilitating online advertising by automatically providing bids for advertisers. Reinforcement learning (RL) has gained popularity for auto-bidding. However, most current RL auto-bidding methods are modeled through the Markovian Decision Process (MDP), which assumes the Markovian state transition. This assumption restricts the ability to perform in long horizon scenarios and makes the model unstable when dealing with highly random online advertising environments. To tackle this issue, this paper introduces AI-Generated Bidding (AIGB), a novel paradigm for auto-bidding through generative modeling. In this paradigm, we propose DiffBid, a conditional diffusion modeling approach for bid generation. DiffBid directly models the correlation between the return and the entire trajectory, effectively avoiding error propagation across time steps in long horizons. Additionally, DiffBid offers a versatile approach for generating trajectories that maximize given targets while adhering to specific constraints. Extensive experiments conducted on the real-world dataset and online A/B test on Alibaba advertising platform demonstrate the effectiveness of DiffBid, achieving 2.81% increase in GMV and 3.36% increase in ROI.
Boosting Disfluency Detection with Large Language Model as Disfluency Generator
Mar 13, 2024



Current disfluency detection methods heavily rely on costly and scarce human-annotated data. To tackle this issue, some approaches employ heuristic or statistical features to generate disfluent sentences, partially improving detection performance. However, these sentences often deviate from real-life scenarios, constraining overall model enhancement. In this study, we propose a lightweight data augmentation approach for disfluency detection, utilizing the superior generative and semantic understanding capabilities of large language model (LLM) to generate disfluent sentences as augmentation data. We leverage LLM to generate diverse and more realistic sentences guided by specific prompts, without the need for fine-tuning the LLM. Subsequently, we apply an uncertainty-aware data filtering approach to improve the quality of the generated sentences, utilized in training a small detection model for improved performance. Experiments using enhanced data yielded state-of-the-art results. The results showed that using a small amount of LLM-generated enhanced data can significantly improve performance, thereby further enhancing cost-effectiveness.
On Manipulating Signals of User-Item Graph: A Jacobi Polynomial-based Graph Collaborative Filtering
Jun 06, 2023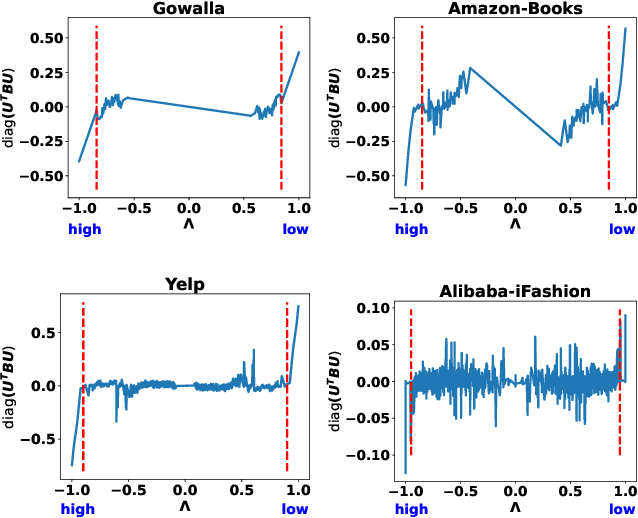
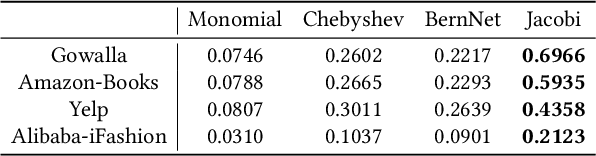
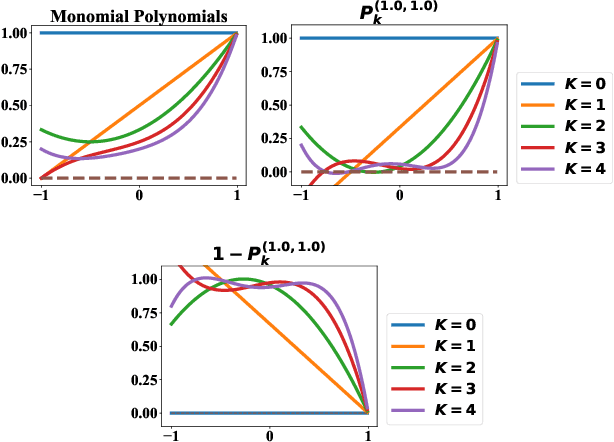
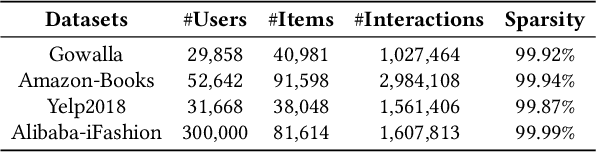
Collaborative filtering (CF) is an important research direction in recommender systems that aims to make recommendations given the information on user-item interactions. Graph CF has attracted more and more attention in recent years due to its effectiveness in leveraging high-order information in the user-item bipartite graph for better recommendations. Specifically, recent studies show the success of graph neural networks (GNN) for CF is attributed to its low-pass filtering effects. However, current researches lack a study of how different signal components contributes to recommendations, and how to design strategies to properly use them well. To this end, from the view of spectral transformation, we analyze the important factors that a graph filter should consider to achieve better performance. Based on the discoveries, we design JGCF, an efficient and effective method for CF based on Jacobi polynomial bases and frequency decomposition strategies. Extensive experiments on four widely used public datasets show the effectiveness and efficiency of the proposed methods, which brings at most 27.06% performance gain on Alibaba-iFashion. Besides, the experimental results also show that JGCF is better at handling sparse datasets, which shows potential in making recommendations for cold-start users.