 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Faster Path to Continual Learning
Apr 13, 2026Continual Learning (CL) aims to train neural networks on a dynamic stream of tasks without forgetting previously learned knowledge. Among optimization-based approaches, C-Flat has emerged as a promising solution due to its plug-and-play nature and its ability to encourage uniformly low-loss regions for both new and old tasks. However, C-Flat requires three additional gradient computations per iteration, imposing substantial overhead on the optimization process. In this work, we propose C-Flat Turbo, a faster yet stronger optimizer that significantly reduces the training cost. We show that the gradients associated with first-order flatness contain direction-invariant components relative to the proxy-model gradients, enabling us to skip redundant gradient computations in the perturbed ascent steps. Moreover, we observe that these flatness-promoting gradients progressively stabilize across tasks, which motivates a linear scheduling strategy with an adaptive trigger to allocate larger turbo steps for later tasks. Experiments show that C-Flat Turbo is 1.0$\times$ to 1.25$\times$ faster than C-Flat across a wide range of CL methods, while achieving comparable or even improved accuracy.
Knowledge is Power: Advancing Few-shot Action Recognition with Multimodal Semantics from MLLMs
Mar 27, 2026Multimodal Large Language Models (MLLMs) have propelled the field of few-shot action recognition (FSAR). However, preliminary explorations in this area primarily focus on generating captions to form a suboptimal feature->caption->feature pipeline and adopt metric learning solely within the visual space. In this paper, we propose FSAR-LLaVA, the first end-to-end method to leverage MLLMs (such as Video-LLaVA) as a multimodal knowledge base for directly enhancing FSAR. First, at the feature level, we leverage the MLLM's multimodal decoder to extract spatiotemporally and semantically enriched representations, which are then decoupled and enhanced by our Multimodal Feature-Enhanced Module into distinct visual and textual features that fully exploit their semantic knowledge for FSAR. Next, we leverage the versatility of MLLMs to craft input prompts that flexibly adapt to diverse scenarios, and use their aligned outputs to drive our designed Composite Task-Oriented Prototype Construction, effectively bridging the distribution gap between meta-train and meta-test sets. Finally, to enable multimodal features to guide metric learning jointly, we introduce a training-free Multimodal Prototype Matching Metric that adaptively selects the most decisive cues and efficiently leverages the decoupled feature representations produced by MLLMs. Extensive experiments demonstrate superior performance across various tasks with minimal trainable parameters.
LumosX: Relate Any Identities with Their Attributes for Personalized Video Generation
Mar 20, 2026Recent advances in diffusion models have significantly improved text-to-video generation, enabling personalized content creation with fine-grained control over both foreground and background elements. However, precise face-attribute alignment across subjects remains challenging, as existing methods lack explicit mechanisms to ensure intra-group consistency. Addressing this gap requires both explicit modeling strategies and face-attribute-aware data resources. We therefore propose LumosX, a framework that advances both data and model design. On the data side, a tailored collection pipeline orchestrates captions and visual cues from independent videos, while multimodal large language models (MLLMs) infer and assign subject-specific dependencies. These extracted relational priors impose a finer-grained structure that amplifies the expressive control of personalized video generation and enables the construction of a comprehensive benchmark. On the modeling side, Relational Self-Attention and Relational Cross-Attention intertwine position-aware embeddings with refined attention dynamics to inscribe explicit subject-attribute dependencies, enforcing disciplined intra-group cohesion and amplifying the separation between distinct subject clusters. Comprehensive evaluations on our benchmark demonstrate that LumosX achieves state-of-the-art performance in fine-grained, identity-consistent, and semantically aligned personalized multi-subject video generation. Code and models are available at https://jiazheng-xing.github.io/lumosx-home/.
DreamVideo-Omni: Omni-Motion Controlled Multi-Subject Video Customization with Latent Identity Reinforcement Learning
Mar 12, 2026While large-scale diffusion models have revolutionized video synthesis, achieving precise control over both multi-subject identity and multi-granularity motion remains a significant challenge. Recent attempts to bridge this gap often suffer from limited motion granularity, control ambiguity, and identity degradation, leading to suboptimal performance on identity preservation and motion control. In this work, we present DreamVideo-Omni, a unified framework enabling harmonious multi-subject customization with omni-motion control via a progressive two-stage training paradigm. In the first stage, we integrate comprehensive control signals for joint training, encompassing subject appearances, global motion, local dynamics, and camera movements. To ensure robust and precise controllability, we introduce a condition-aware 3D rotary positional embedding to coordinate heterogeneous inputs and a hierarchical motion injection strategy to enhance global motion guidance. Furthermore, to resolve multi-subject ambiguity, we introduce group and role embeddings to explicitly anchor motion signals to specific identities, effectively disentangling complex scenes into independent controllable instances. In the second stage, to mitigate identity degradation, we design a latent identity reward feedback learning paradigm by training a latent identity reward model upon a pretrained video diffusion backbone. This provides motion-aware identity rewards in the latent space, prioritizing identity preservation aligned with human preferences. Supported by our curated large-scale dataset and the comprehensive DreamOmni Bench for multi-subject and omni-motion control evaluation, DreamVideo-Omni demonstrates superior performance in generating high-quality videos with precise controllability.
Why Does RL Generalize Better Than SFT? A Data-Centric Perspective on VLM Post-Training
Feb 11, 2026The adaptation of large-scale Vision-Language Models (VLMs) through post-training reveals a pronounced generalization gap: models fine-tuned with Reinforcement Learning (RL) consistently achieve superior out-of-distribution (OOD) performance compared to those trained with Supervised Fine-Tuning (SFT). This paper posits a data-centric explanation for this phenomenon, contending that RL's generalization advantage arises from an implicit data filtering mechanism that inherently prioritizes medium-difficulty training samples. To test this hypothesis, we systematically evaluate the OOD generalization of SFT models across training datasets of varying difficulty levels. Our results confirm that data difficulty is a critical factor, revealing that training on hard samples significantly degrades OOD performance. Motivated by this finding, we introduce Difficulty-Curated SFT (DC-SFT), a straightforward method that explicitly filters the training set based on sample difficulty. Experiments show that DC-SFT not only substantially enhances OOD generalization over standard SFT, but also surpasses the performance of RL-based training, all while providing greater stability and computational efficiency. This work offers a data-centric account of the OOD generalization gap in VLMs and establishes a more efficient pathway to achieving robust generalization. Code is available at https://github.com/byyx666/DC-SFT.
MCIE: Multimodal LLM-Driven Complex Instruction Image Editing with Spatial Guidance
Feb 08, 2026Recent advances in instruction-based image editing have shown remarkable progress. However, existing methods remain limited to relatively simple editing operations, hindering real-world applications that require complex and compositional instructions. In this work, we address these limitations from the perspectives of architectural design, data, and evaluation protocols. Specifically, we identify two key challenges in current models: insufficient instruction compliance and background inconsistency. To this end, we propose MCIE-E1, a Multimodal Large Language Model-Driven Complex Instruction Image Editing method that integrates two key modules: a spatial-aware cross-attention module and a background-consistent cross-attention module. The former enhances instruction-following capability by explicitly aligning semantic instructions with spatial regions through spatial guidance during the denoising process, while the latter preserves features in unedited regions to maintain background consistency. To enable effective training, we construct a dedicated data pipeline to mitigate the scarcity of complex instruction-based image editing datasets, combining fine-grained automatic filtering via a powerful MLLM with rigorous human validation. Finally, to comprehensively evaluate complex instruction-based image editing, we introduce CIE-Bench, a new benchmark with two new evaluation metrics. Experimental results on CIE-Bench demonstrate that MCIE-E1 consistently outperforms previous state-of-the-art methods in both quantitative and qualitative assessments, achieving a 23.96% improvement in instruction compliance.
Continual GUI Agents
Jan 29, 2026As digital environments (data distribution) are in flux, with new GUI data arriving over time-introducing new domains or resolutions-agents trained on static environments deteriorate in performance. In this work, we introduce Continual GUI Agents, a new task that requires GUI agents to perform continual learning under shifted domains and resolutions. We find existing methods fail to maintain stable grounding as GUI distributions shift over time, due to the diversity of UI interaction points and regions in fluxing scenarios. To address this, we introduce GUI-Anchoring in Flux (GUI-AiF), a new reinforcement fine-tuning framework that stabilizes continual learning through two novel rewards: Anchoring Point Reward in Flux (APR-iF) and Anchoring Region Reward in Flux (ARR-iF). These rewards guide the agents to align with shifting interaction points and regions, mitigating the tendency of existing reward strategies to over-adapt to static grounding cues (e.g., fixed coordinates or element scales). Extensive experiments show GUI-AiF surpasses state-of-the-art baselines. Our work establishes the first continual learning framework for GUI agents, revealing the untapped potential of reinforcement fine-tuning for continual GUI Agents.
CogFlow: Bridging Perception and Reasoning through Knowledge Internalization for Visual Mathematical Problem Solving
Jan 05, 2026Despite significant progress, multimodal large language models continue to struggle with visual mathematical problem solving. Some recent works recognize that visual perception is a bottleneck in visual mathematical reasoning, but their solutions are limited to improving the extraction and interpretation of visual inputs. Notably, they all ignore the key issue of whether the extracted visual cues are faithfully integrated and properly utilized in subsequent reasoning. Motivated by this, we present CogFlow, a novel cognitive-inspired three-stage framework that incorporates a knowledge internalization stage, explicitly simulating the hierarchical flow of human reasoning: perception$\Rightarrow$internalization$\Rightarrow$reasoning. Inline with this hierarchical flow, we holistically enhance all its stages. We devise Synergistic Visual Rewards to boost perception capabilities in parametric and semantic spaces, jointly improving visual information extraction from symbols and diagrams. To guarantee faithful integration of extracted visual cues into subsequent reasoning, we introduce a Knowledge Internalization Reward model in the internalization stage, bridging perception and reasoning. Moreover, we design a Visual-Gated Policy Optimization algorithm to further enforce the reasoning is grounded with the visual knowledge, preventing models seeking shortcuts that appear coherent but are visually ungrounded reasoning chains. Moreover, we contribute a new dataset MathCog for model training, which contains samples with over 120K high-quality perception-reasoning aligned annotations. Comprehensive experiments and analysis on commonly used visual mathematical reasoning benchmarks validate the superiority of the proposed CogFlow.
ReViSE: Towards Reason-Informed Video Editing in Unified Models with Self-Reflective Learning
Dec 11, 2025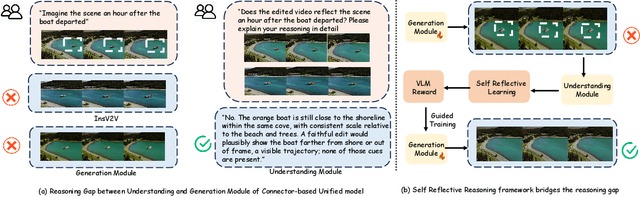
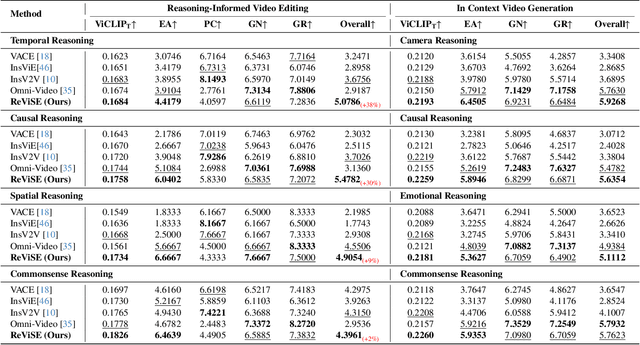

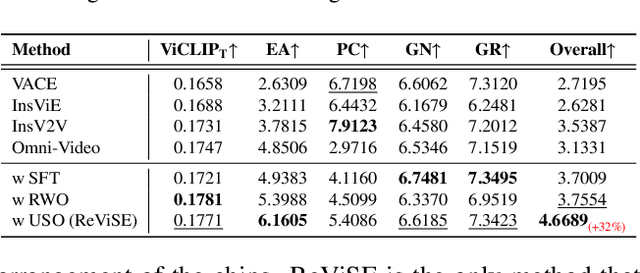
Video unified models exhibit strong capabilities in understanding and generation, yet they struggle with reason-informed visual editing even when equipped with powerful internal vision-language models (VLMs). We attribute this gap to two factors: 1) existing datasets are inadequate for training and evaluating reasoning-aware video editing, and 2) an inherent disconnect between the models' reasoning and editing capabilities, which prevents the rich understanding from effectively instructing the editing process. Bridging this gap requires an integrated framework that connects reasoning with visual transformation. To address this gap, we introduce the Reason-Informed Video Editing (RVE) task, which requires reasoning about physical plausibility and causal dynamics during editing. To support systematic evaluation, we construct RVE-Bench, a comprehensive benchmark with two complementary subsets: Reasoning-Informed Video Editing and In-Context Video Generation. These subsets cover diverse reasoning dimensions and real-world editing scenarios. Building upon this foundation, we propose the ReViSE, a Self-Reflective Reasoning (SRF) framework that unifies generation and evaluation within a single architecture. The model's internal VLM provides intrinsic feedback by assessing whether the edited video logically satisfies the given instruction. The differential feedback that refines the generator's reasoning behavior during training. Extensive experiments on RVE-Bench demonstrate that ReViSE significantly enhances editing accuracy and visual fidelity, achieving a 32% improvement of the Overall score in the reasoning-informed video editing subset over state-of-the-art methods.
SAMora: Enhancing SAM through Hierarchical Self-Supervised Pre-Training for Medical Images
Nov 09, 2025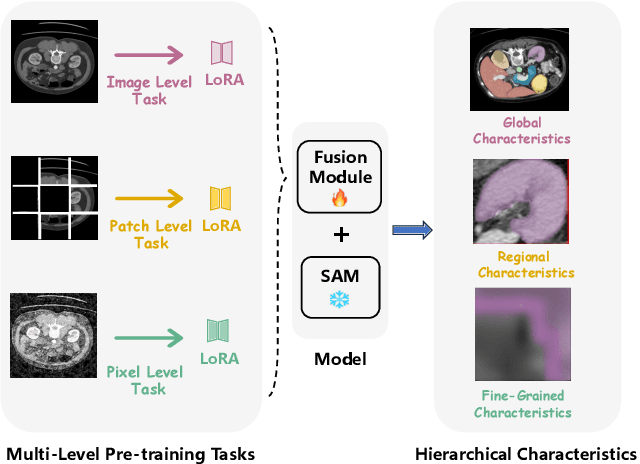
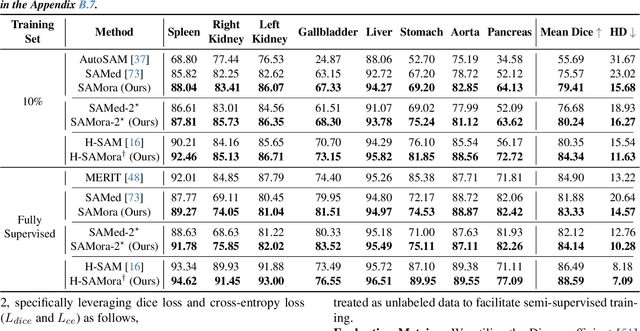
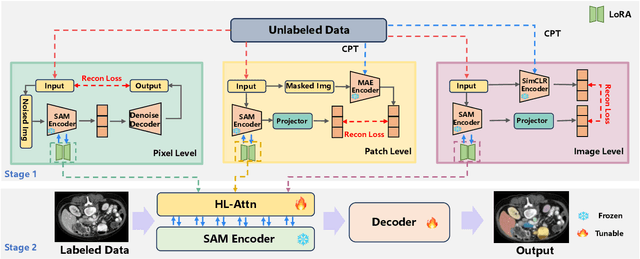
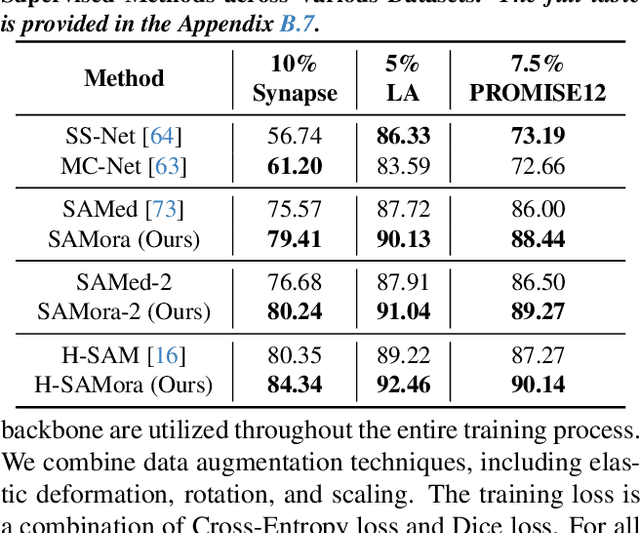
The Segment Anything Model (SAM) has demonstrated significant potential in medical image segmentation. Yet, its performance is limited when only a small amount of labeled data is available, while there is abundant valuable yet often overlooked hierarchical information in medical data. To address this limitation, we draw inspiration from self-supervised learning and propose SAMora, an innovative framework that captures hierarchical medical knowledge by applying complementary self-supervised learning objectives at the image, patch, and pixel levels. To fully exploit the complementarity of hierarchical knowledge within LoRAs, we introduce HL-Attn, a hierarchical fusion module that integrates multi-scale features while maintaining their distinct characteristics. SAMora is compatible with various SAM variants, including SAM2, SAMed, and H-SAM. Experimental results on the Synapse, LA, and PROMISE12 datasets demonstrate that SAMora outperforms existing SAM variants. It achieves state-of-the-art performance in both few-shot and fully supervised settings while reducing fine-tuning epochs by 90%. The code is available at https://github.com/ShChen233/SAMora.