 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZoom to Essence: Trainless GUI Grounding by Inferring upon Interface Elements
Mar 15, 2026Multimodal Large Language Model (MLLM)-based Graphical User Interface (GUI) agents develop rapidly, with visual grounding that maps natural language instructions to target UI elements serving as the core capability. Existing GUI agents typically fine-tune MLLM on massive datasets to handle challenges in understanding instructions and UI interfaces, which not only incurs high data annotation costs but also makes performance dependent on data quality and distribution. To avoid such cumbersome yet ineffective training, we notice that complex UI interfaces can be decomposed into basic visual elements directly understandable by common MLLMs. Consequently, we propose ZoomUI that leverages inference scaling to guide common MLLMs in progressively anchor instruction elements to increasingly detailed interface elements. Specifically, ZoomUI first optimizes the latent thinking to transform original instruction into element visual features description, and subsequently leverages internal attention to iteratively zoom in target element interface region. Evaluations on extensive benchmarks demonstrate that ZoomUI reaches or even surpasses SOTA baselines.
Branch, or Layer? Zeroth-Order Optimization for Continual Learning of Vision-Language Models
Jun 14, 2025Continual learning in vision-language models (VLMs) faces critical challenges in balancing parameter efficiency, memory consumption, and optimization stability. While First-Order (FO) optimization (e.g., SGD) dominate current approaches, their deterministic gradients often trap models in suboptimal local minima and incur substantial memory overhead. This paper pioneers a systematic exploration of Zeroth-Order (ZO) optimization for vision-language continual learning (VLCL). We first identify the incompatibility of naive full-ZO adoption in VLCL due to modality-specific instability. To resolve this, we selectively applying ZO to either vision or language modalities while retaining FO in the complementary branch. Furthermore, we develop a layer-wise optimization paradigm that interleaves ZO and FO across network layers, capitalizing on the heterogeneous learning dynamics of shallow versus deep representations. A key theoretical insight reveals that ZO perturbations in vision branches exhibit higher variance than language counterparts, prompting a gradient sign normalization mechanism with modality-specific perturbation constraints. Extensive experiments on four benchmarks demonstrate that our method achieves state-of-the-art performance, reducing memory consumption by 89.1% compared to baselines. Code will be available upon publication.
A Light Weight Model for Active Speaker Detection
Mar 08, 2023



Active speaker detection is a challenging task in audio-visual scenario understanding, which aims to detect who is speaking in one or more speakers scenarios. This task has received extensive attention as it is crucial in applications such as speaker diarization, speaker tracking, and automatic video editing. The existing studies try to improve performance by inputting multiple candidate information and designing complex models. Although these methods achieved outstanding performance, their high consumption of memory and computational power make them difficult to be applied in resource-limited scenarios. Therefore, we construct a lightweight active speaker detection architecture by reducing input candidates, splitting 2D and 3D convolutions for audio-visual feature extraction, and applying gated recurrent unit (GRU) with low computational complexity for cross-modal modeling. Experimental results on the AVA-ActiveSpeaker dataset show that our framework achieves competitive mAP performance (94.1% vs. 94.2%), while the resource costs are significantly lower than the state-of-the-art method, especially in model parameters (1.0M vs. 22.5M, about 23x) and FLOPs (0.6G vs. 2.6G, about 4x). In addition, our framework also performs well on the Columbia dataset showing good robustness. The code and model weights are available at https://github.com/Junhua-Liao/Light-ASD.
Monolingual Recognizers Fusion for Code-switching Speech Recognition
Nov 02, 2022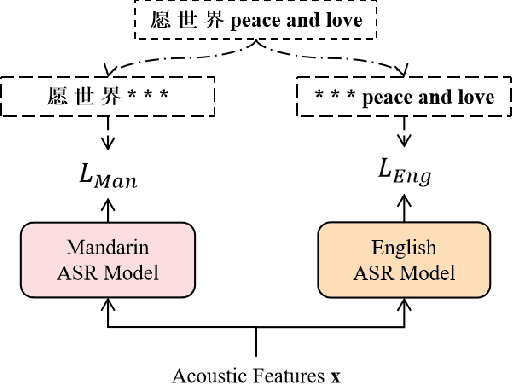
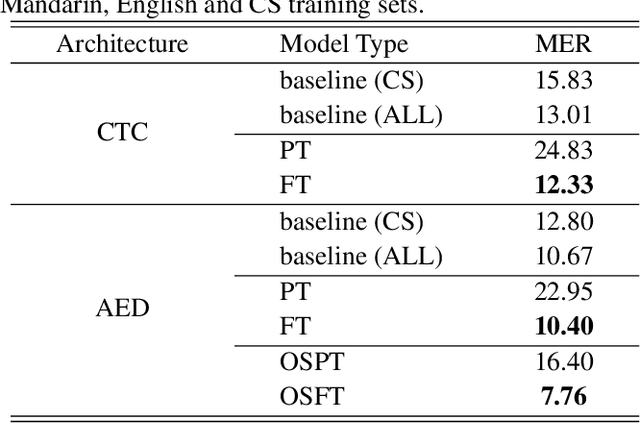
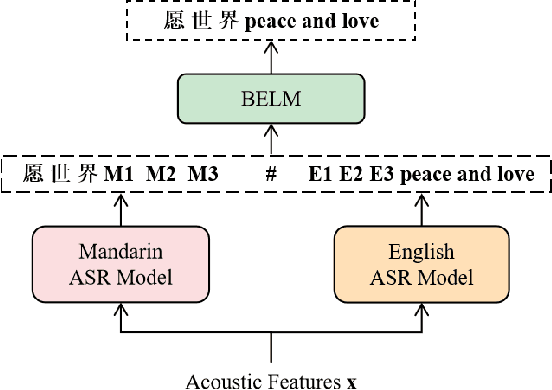
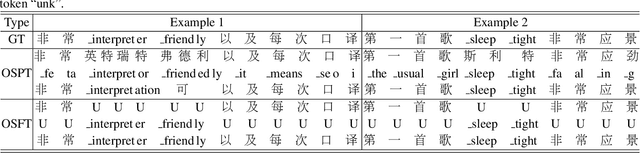
The bi-encoder structure has been intensively investigated in code-switching (CS) automatic speech recognition (ASR). However, most existing methods require the structures of two monolingual ASR models (MAMs) should be the same and only use the encoder of MAMs. This leads to the problem that pre-trained MAMs cannot be timely and fully used for CS ASR. In this paper, we propose a monolingual recognizers fusion method for CS ASR. It has two stages: the speech awareness (SA) stage and the language fusion (LF) stage. In the SA stage, acoustic features are mapped to two language-specific predictions by two independent MAMs. To keep the MAMs focused on their own language, we further extend the language-aware training strategy for the MAMs. In the LF stage, the BELM fuses two language-specific predictions to get the final prediction. Moreover, we propose a text simulation strategy to simplify the training process of the BELM and reduce reliance on CS data. Experiments on a Mandarin-English corpus show the efficiency of the proposed method. The mix error rate is significantly reduced on the test set after using open-source pre-trained MAMs.