 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Data Efficiency Dilemma: A Federated and Augmented Learning Framework For Alzheimer's Disease Detection via Speech
Feb 16, 2026Early diagnosis of Alzheimer's Disease (AD) is crucial for delaying its progression. While AI-based speech detection is non-invasive and cost-effective, it faces a critical data efficiency dilemma due to medical data scarcity and privacy barriers. Therefore, we propose FAL-AD, a novel framework that synergistically integrates federated learning with data augmentation to systematically optimize data efficiency. Our approach delivers three key breakthroughs: First, absolute efficiency improvement through voice conversion-based augmentation, which generates diverse pathological speech samples via cross-category voice-content recombination. Second, collaborative efficiency breakthrough via an adaptive federated learning paradigm, maximizing cross-institutional benefits under privacy constraints. Finally, representational efficiency optimization by an attentive cross-modal fusion model, which achieves fine-grained word-level alignment and acoustic-textual interaction. Evaluated on ADReSSo, FAL-AD achieves a state-of-the-art multi-modal accuracy of 91.52%, outperforming all centralized baselines and demonstrating a practical solution to the data efficiency dilemma. Our source code is publicly available at https://github.com/smileix/fal-ad.
Monolingual Recognizers Fusion for Code-switching Speech Recognition
Nov 02, 2022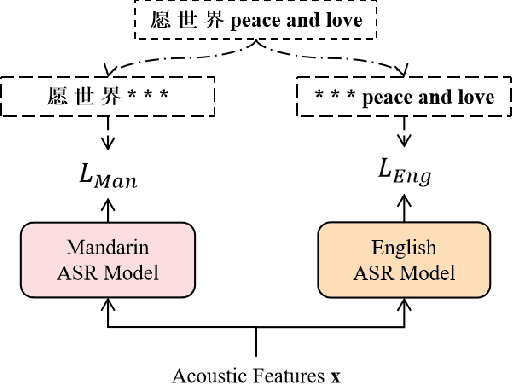
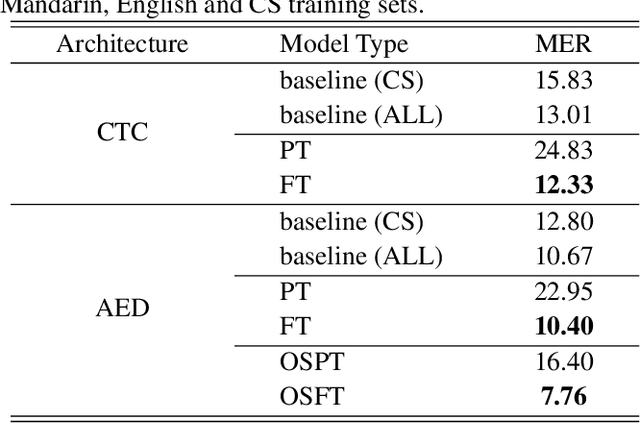
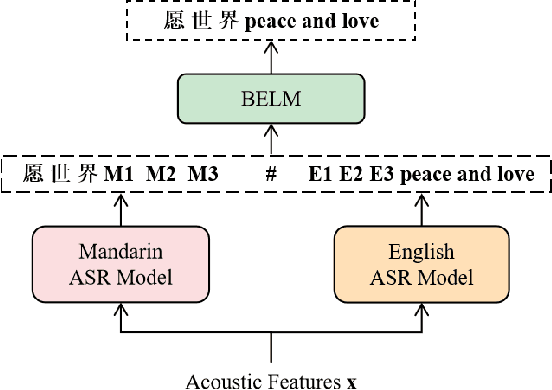
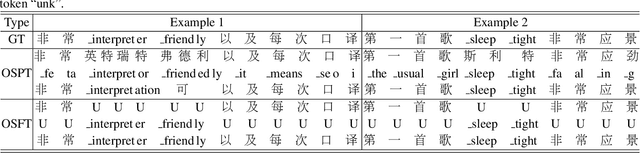
The bi-encoder structure has been intensively investigated in code-switching (CS) automatic speech recognition (ASR). However, most existing methods require the structures of two monolingual ASR models (MAMs) should be the same and only use the encoder of MAMs. This leads to the problem that pre-trained MAMs cannot be timely and fully used for CS ASR. In this paper, we propose a monolingual recognizers fusion method for CS ASR. It has two stages: the speech awareness (SA) stage and the language fusion (LF) stage. In the SA stage, acoustic features are mapped to two language-specific predictions by two independent MAMs. To keep the MAMs focused on their own language, we further extend the language-aware training strategy for the MAMs. In the LF stage, the BELM fuses two language-specific predictions to get the final prediction. Moreover, we propose a text simulation strategy to simplify the training process of the BELM and reduce reliance on CS data. Experiments on a Mandarin-English corpus show the efficiency of the proposed method. The mix error rate is significantly reduced on the test set after using open-source pre-trained MAMs.
Language-specific Characteristic Assistance for Code-switching Speech Recognition
Jul 05, 2022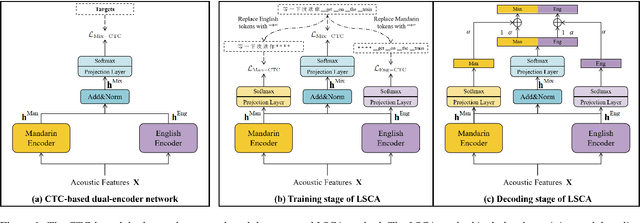

Dual-encoder structure successfully utilizes two language-specific encoders (LSEs) for code-switching speech recognition. Because LSEs are initialized by two pre-trained language-specific models (LSMs), the dual-encoder structure can exploit sufficient monolingual data and capture the individual language attributes. However, existing methods have no language constraints on LSEs and underutilize language-specific knowledge of LSMs. In this paper, we propose a language-specific characteristic assistance (LSCA) method to mitigate the above problems. Specifically, during training, we introduce two language-specific losses as language constraints and generate corresponding language-specific targets for them. During decoding, we take the decoding abilities of LSMs into account by combining the output probabilities of two LSMs and the mixture model to obtain the final predictions. Experiments show that either the training or decoding method of LSCA can improve the model's performance. Furthermore, the best result can obtain up to 15.4% relative error reduction on the code-switching test set by combining the training and decoding methods of LSCA. Moreover, the system can process code-switching speech recognition tasks well without extra shared parameters or even retraining based on two pre-trained LSMs by using our method.