 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOTSA: A Cross-Lingual Speech Alignment Framework for Low Resource Speech-to-Text Translation
Nov 12, 2025Speech Large Language Models (SpeechLLMs) have achieved breakthroughs in multilingual speech-to-text translation (S2TT). However, existing approaches often overlook semantic commonalities across source languages, leading to biased translation performance. In this work, we propose \textbf{POTSA} (Parallel Optimal Transport for Speech Alignment), a new framework based on cross-lingual parallel speech pairs and Optimal Transport (OT), designed to bridge high- and low-resource translation gaps. First, we introduce a Bias Compensation module to coarsely align initial speech representations across languages. Second, we impose token-level OT constraints on a Q-Former using parallel speech pairs to establish fine-grained consistency of representations. Then, we apply a layer scheduling strategy to focus OT constraints on the most semantically beneficial layers. Experiments on the FLEURS dataset show that our method achieves SOTA performance, with +0.93 BLEU on average over five common languages and +5.05 BLEU on zero-shot languages, using only 10 hours of parallel speech per source language.
ASDA: Audio Spectrogram Differential Attention Mechanism for Self-Supervised Representation Learning
Jul 03, 2025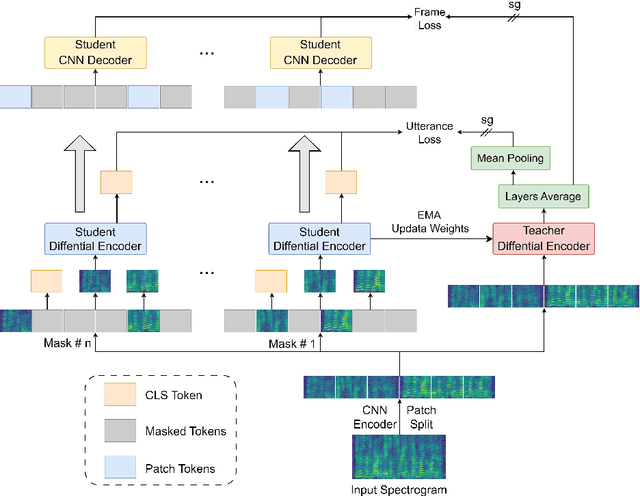



In recent advancements in audio self-supervised representation learning, the standard Transformer architecture has emerged as the predominant approach, yet its attention mechanism often allocates a portion of attention weights to irrelevant information, potentially impairing the model's discriminative ability. To address this, we introduce a differential attention mechanism, which effectively mitigates ineffective attention allocation through the integration of dual-softmax operations and appropriately tuned differential coefficients. Experimental results demonstrate that our ASDA model achieves state-of-the-art (SOTA) performance across multiple benchmarks, including audio classification (49.0% mAP on AS-2M, 41.5% mAP on AS20K), keyword spotting (98.3% accuracy on SPC-2), and environmental sound classification (96.1% accuracy on ESC-50). These results highlight ASDA's effectiveness in audio tasks, paving the way for broader applications.
Rethinking Contrastive Learning in Graph Anomaly Detection: A Clean-View Perspective
May 23, 2025Graph anomaly detection aims to identify unusual patterns in graph-based data, with wide applications in fields such as web security and financial fraud detection. Existing methods typically rely on contrastive learning, assuming that a lower similarity between a node and its local subgraph indicates abnormality. However, these approaches overlook a crucial limitation: the presence of interfering edges invalidates this assumption, since it introduces disruptive noise that compromises the contrastive learning process. Consequently, this limitation impairs the ability to effectively learn meaningful representations of normal patterns, leading to suboptimal detection performance. To address this issue, we propose a Clean-View Enhanced Graph Anomaly Detection framework (CVGAD), which includes a multi-scale anomaly awareness module to identify key sources of interference in the contrastive learning process. Moreover, to mitigate bias from the one-step edge removal process, we introduce a novel progressive purification module. This module incrementally refines the graph by iteratively identifying and removing interfering edges, thereby enhancing model performance. Extensive experiments on five benchmark datasets validate the effectiveness of our approach.
Characteristic-Specific Partial Fine-Tuning for Efficient Emotion and Speaker Adaptation in Codec Language Text-to-Speech Models
Jan 24, 2025



Recently, emotional speech generation and speaker cloning have garnered significant interest in text-to-speech (TTS). With the open-sourcing of codec language TTS models trained on massive datasets with large-scale parameters, adapting these general pre-trained TTS models to generate speech with specific emotional expressions and target speaker characteristics has become a topic of great attention. Common approaches, such as full and adapter-based fine-tuning, often overlook the specific contributions of model parameters to emotion and speaker control. Treating all parameters uniformly during fine-tuning, especially when the target data has limited content diversity compared to the pre-training corpus, results in slow training speed and an increased risk of catastrophic forgetting. To address these challenges, we propose a characteristic-specific partial fine-tuning strategy, short as CSP-FT. First, we use a weighted-sum approach to analyze the contributions of different Transformer layers in a pre-trained codec language TTS model for emotion and speaker control in the generated speech. We then selectively fine-tune the layers with the highest and lowest characteristic-specific contributions to generate speech with target emotional expression and speaker identity. Experimental results demonstrate that our method achieves performance comparable to, or even surpassing, full fine-tuning in generating speech with specific emotional expressions and speaker identities. Additionally, CSP-FT delivers approximately 2x faster training speeds, fine-tunes only around 8% of parameters, and significantly reduces catastrophic forgetting. Furthermore, we show that codec language TTS models perform competitively with self-supervised models in speaker identification and emotion classification tasks, offering valuable insights for developing universal speech processing models.
Reducing the Gap Between Pretrained Speech Enhancement and Recognition Models Using a Real Speech-Trained Bridging Module
Jan 05, 2025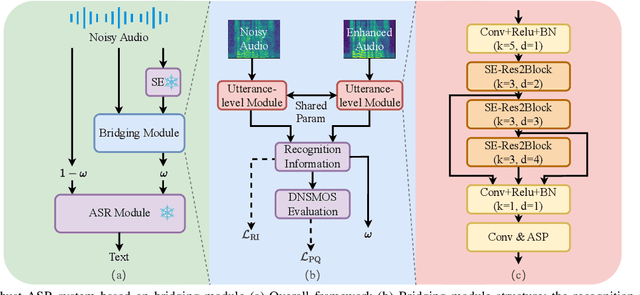
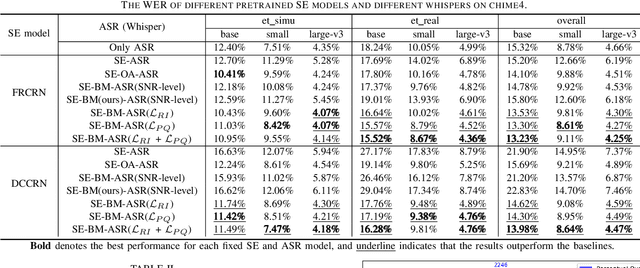
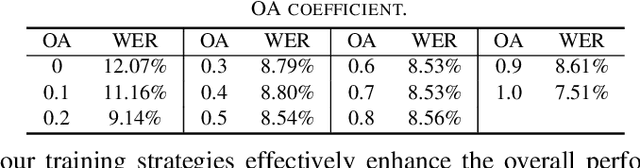
The information loss or distortion caused by single-channel speech enhancement (SE) harms the performance of automatic speech recognition (ASR). Observation addition (OA) is an effective post-processing method to improve ASR performance by balancing noisy and enhanced speech. Determining the OA coefficient is crucial. However, the currently supervised OA coefficient module, called the bridging module, only utilizes simulated noisy speech for training, which has a severe mismatch with real noisy speech. In this paper, we propose training strategies to train the bridging module with real noisy speech. First, DNSMOS is selected to evaluate the perceptual quality of real noisy speech with no need for the corresponding clean label to train the bridging module. Additional constraints during training are introduced to enhance the robustness of the bridging module further. Each utterance is evaluated by the ASR back-end using various OA coefficients to obtain the word error rates (WERs). The WERs are used to construct a multidimensional vector. This vector is introduced into the bridging module with multi-task learning and is used to determine the optimal OA coefficients. The experimental results on the CHiME-4 dataset show that the proposed methods all had significant improvement compared with the simulated data trained bridging module, especially under real evaluation sets.
Mamba-SEUNet: Mamba UNet for Monaural Speech Enhancement
Dec 21, 2024In recent speech enhancement (SE) research, transformer and its variants have emerged as the predominant methodologies. However, the quadratic complexity of the self-attention mechanism imposes certain limitations on practical deployment. Mamba, as a novel state-space model (SSM), has gained widespread application in natural language processing and computer vision due to its strong capabilities in modeling long sequences and relatively low computational complexity. In this work, we introduce Mamba-SEUNet, an innovative architecture that integrates Mamba with U-Net for SE tasks. By leveraging bidirectional Mamba to model forward and backward dependencies of speech signals at different resolutions, and incorporating skip connections to capture multi-scale information, our approach achieves state-of-the-art (SOTA) performance. Experimental results on the VCTK+DEMAND dataset indicate that Mamba-SEUNet attains a PESQ score of 3.59, while maintaining low computational complexity. When combined with the Perceptual Contrast Stretching technique, Mamba-SEUNet further improves the PESQ score to 3.73.
Enriching Multimodal Sentiment Analysis through Textual Emotional Descriptions of Visual-Audio Content
Dec 12, 2024



Multimodal Sentiment Analysis (MSA) stands as a critical research frontier, seeking to comprehensively unravel human emotions by amalgamating text, audio, and visual data. Yet, discerning subtle emotional nuances within audio and video expressions poses a formidable challenge, particularly when emotional polarities across various segments appear similar. In this paper, our objective is to spotlight emotion-relevant attributes of audio and visual modalities to facilitate multimodal fusion in the context of nuanced emotional shifts in visual-audio scenarios. To this end, we introduce DEVA, a progressive fusion framework founded on textual sentiment descriptions aimed at accentuating emotional features of visual-audio content. DEVA employs an Emotional Description Generator (EDG) to transmute raw audio and visual data into textualized sentiment descriptions, thereby amplifying their emotional characteristics. These descriptions are then integrated with the source data to yield richer, enhanced features. Furthermore, DEVA incorporates the Text-guided Progressive Fusion Module (TPF), leveraging varying levels of text as a core modality guide. This module progressively fuses visual-audio minor modalities to alleviate disparities between text and visual-audio modalities. Experimental results on widely used sentiment analysis benchmark datasets, including MOSI, MOSEI, and CH-SIMS, underscore significant enhancements compared to state-of-the-art models. Moreover, fine-grained emotion experiments corroborate the robust sensitivity of DEVA to subtle emotional variations.
Progressive Residual Extraction based Pre-training for Speech Representation Learning
Aug 31, 2024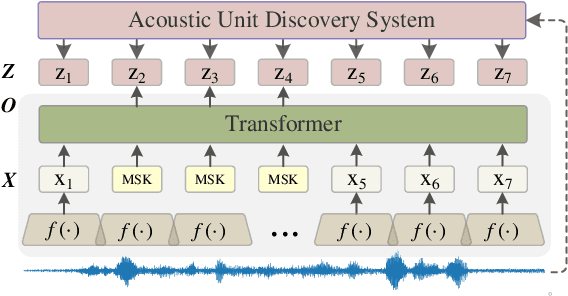
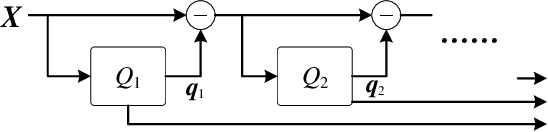
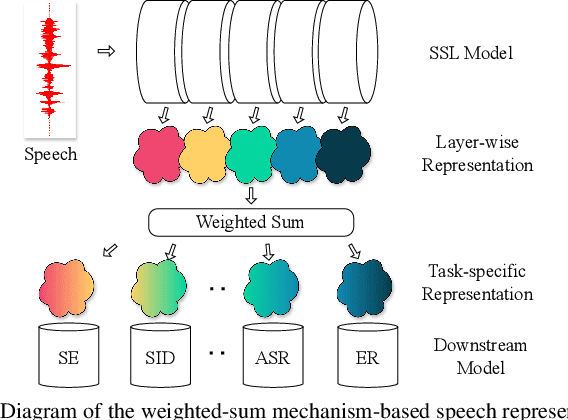
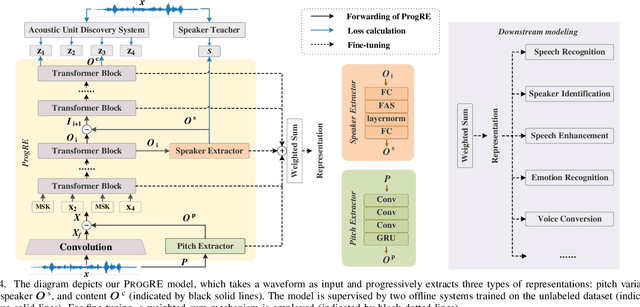
Self-supervised learning (SSL) has garnered significant attention in speech processing, excelling in linguistic tasks such as speech recognition. However, jointly improving the performance of pre-trained models on various downstream tasks, each requiring different speech information, poses significant challenges. To this purpose, we propose a progressive residual extraction based self-supervised learning method, named ProgRE. Specifically, we introduce two lightweight and specialized task modules into an encoder-style SSL backbone to enhance its ability to extract pitch variation and speaker information from speech. Furthermore, to prevent the interference of reinforced pitch variation and speaker information with irrelevant content information learning, we residually remove the information extracted by these two modules from the main branch. The main branch is then trained using HuBERT's speech masking prediction to ensure the performance of the Transformer's deep-layer features on content tasks. In this way, we can progressively extract pitch variation, speaker, and content representations from the input speech. Finally, we can combine multiple representations with diverse speech information using different layer weights to obtain task-specific representations for various downstream tasks. Experimental results indicate that our proposed method achieves joint performance improvements on various tasks, such as speaker identification, speech recognition, emotion recognition, speech enhancement, and voice conversion, compared to excellent SSL methods such as wav2vec2.0, HuBERT, and WavLM.
VQ-CTAP: Cross-Modal Fine-Grained Sequence Representation Learning for Speech Processing
Aug 11, 2024Deep learning has brought significant improvements to the field of cross-modal representation learning. For tasks such as text-to-speech (TTS), voice conversion (VC), and automatic speech recognition (ASR), a cross-modal fine-grained (frame-level) sequence representation is desired, emphasizing the semantic content of the text modality while de-emphasizing the paralinguistic information of the speech modality. We propose a method called "Vector Quantized Contrastive Token-Acoustic Pre-training (VQ-CTAP)", which uses the cross-modal aligned sequence transcoder to bring text and speech into a joint multimodal space, learning how to connect text and speech at the frame level. The proposed VQ-CTAP is a paradigm for cross-modal sequence representation learning, offering a promising solution for fine-grained generation and recognition tasks in speech processing. The VQ-CTAP can be directly applied to VC and ASR tasks without fine-tuning or additional structures. We propose a sequence-aware semantic connector, which connects multiple frozen pre-trained modules for the TTS task, exhibiting a plug-and-play capability. We design a stepping optimization strategy to ensure effective model convergence by gradually injecting and adjusting the influence of various loss components. Furthermore, we propose a semantic-transfer-wise paralinguistic consistency loss to enhance representational capabilities, allowing the model to better generalize to unseen data and capture the nuances of paralinguistic information. In addition, VQ-CTAP achieves high-compression speech coding at a rate of 25Hz from 24kHz input waveforms, which is a 960-fold reduction in the sampling rate. The audio demo is available at https://qiangchunyu.github.io/VQCTAP/
An Initial Investigation of Language Adaptation for TTS Systems under Low-resource Scenarios
Jun 13, 2024Self-supervised learning (SSL) representations from massively multilingual models offer a promising solution for low-resource language speech tasks. Despite advancements, language adaptation in TTS systems remains an open problem. This paper explores the language adaptation capability of ZMM-TTS, a recent SSL-based multilingual TTS system proposed in our previous work. We conducted experiments on 12 languages using limited data with various fine-tuning configurations. We demonstrate that the similarity in phonetics between the pre-training and target languages, as well as the language category, affects the target language's adaptation performance. Additionally, we find that the fine-tuning dataset size and number of speakers influence adaptability. Surprisingly, we also observed that using paired data for fine-tuning is not always optimal compared to audio-only data. Beyond speech intelligibility, our analysis covers speaker similarity, language identification, and predicted MOS.