 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrgan-aware Multi-scale Medical Image Segmentation Using Text Prompt Engineering
Mar 18, 2025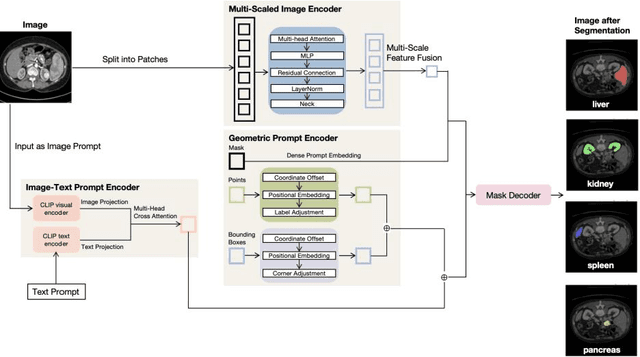
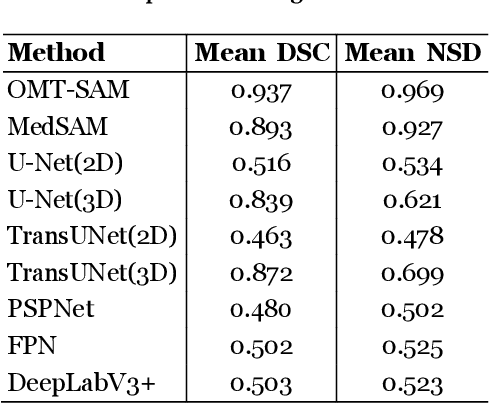
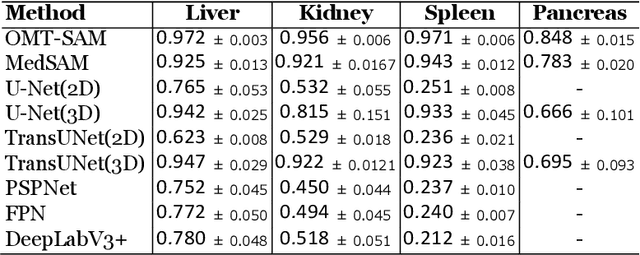
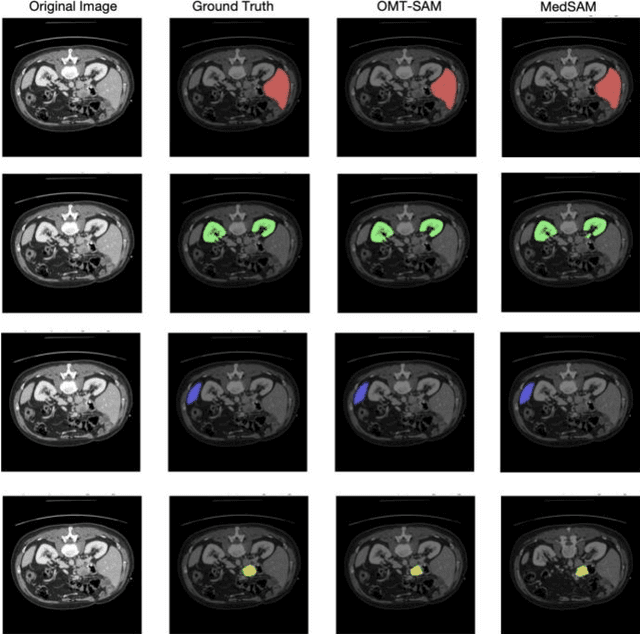
Accurate segmentation is essential for effective treatment planning and disease monitoring. Existing medical image segmentation methods predominantly rely on uni-modal visual inputs, such as images or videos, requiring labor-intensive manual annotations. Additionally, medical imaging techniques capture multiple intertwined organs within a single scan, further complicating segmentation accuracy. To address these challenges, MedSAM, a large-scale medical segmentation model based on the Segment Anything Model (SAM), was developed to enhance segmentation accuracy by integrating image features with user-provided prompts. While MedSAM has demonstrated strong performance across various medical segmentation tasks, it primarily relies on geometric prompts (e.g., points and bounding boxes) and lacks support for text-based prompts, which could help specify subtle or ambiguous anatomical structures. To overcome these limitations, we propose the Organ-aware Multi-scale Text-guided Medical Image Segmentation Model (OMT-SAM) for multi-organ segmentation. Our approach introduces CLIP encoders as a novel image-text prompt encoder, operating with the geometric prompt encoder to provide informative contextual guidance. We pair descriptive textual prompts with corresponding images, processing them through pre-trained CLIP encoders and a cross-attention mechanism to generate fused image-text embeddings. Additionally, we extract multi-scale visual features from MedSAM, capturing fine-grained anatomical details at different levels of granularity. We evaluate OMT-SAM on the FLARE 2021 dataset, benchmarking its performance against existing segmentation methods. Empirical results demonstrate that OMT-SAM achieves a mean Dice Similarity Coefficient of 0.937, outperforming MedSAM (0.893) and other segmentation models, highlighting its superior capability in handling complex medical image segmentation tasks.
Reducing the Gap Between Pretrained Speech Enhancement and Recognition Models Using a Real Speech-Trained Bridging Module
Jan 05, 2025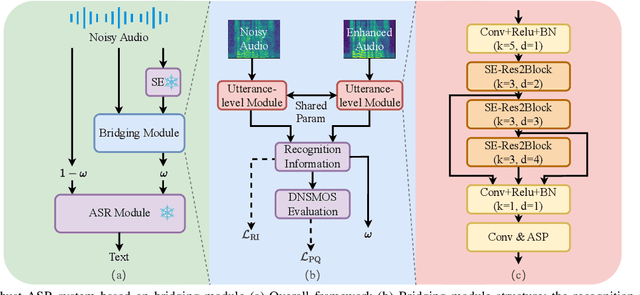
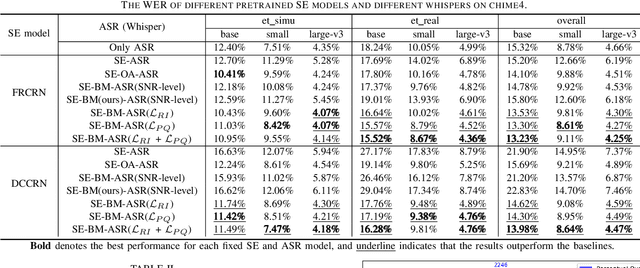
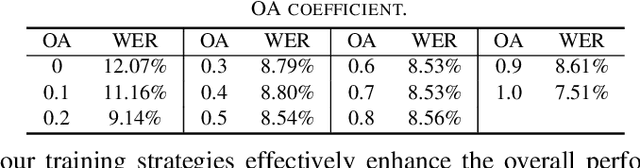
The information loss or distortion caused by single-channel speech enhancement (SE) harms the performance of automatic speech recognition (ASR). Observation addition (OA) is an effective post-processing method to improve ASR performance by balancing noisy and enhanced speech. Determining the OA coefficient is crucial. However, the currently supervised OA coefficient module, called the bridging module, only utilizes simulated noisy speech for training, which has a severe mismatch with real noisy speech. In this paper, we propose training strategies to train the bridging module with real noisy speech. First, DNSMOS is selected to evaluate the perceptual quality of real noisy speech with no need for the corresponding clean label to train the bridging module. Additional constraints during training are introduced to enhance the robustness of the bridging module further. Each utterance is evaluated by the ASR back-end using various OA coefficients to obtain the word error rates (WERs). The WERs are used to construct a multidimensional vector. This vector is introduced into the bridging module with multi-task learning and is used to determine the optimal OA coefficients. The experimental results on the CHiME-4 dataset show that the proposed methods all had significant improvement compared with the simulated data trained bridging module, especially under real evaluation sets.
A Post Auto-regressive GAN Vocoder Focused on Spectrum Fracture
Apr 12, 2022
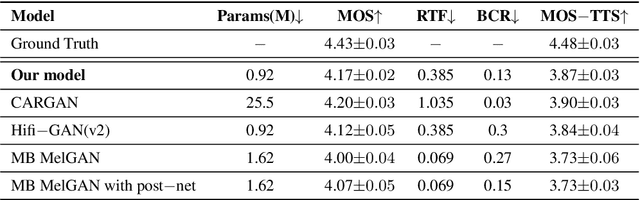
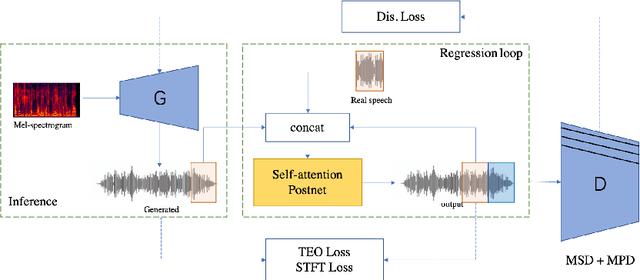
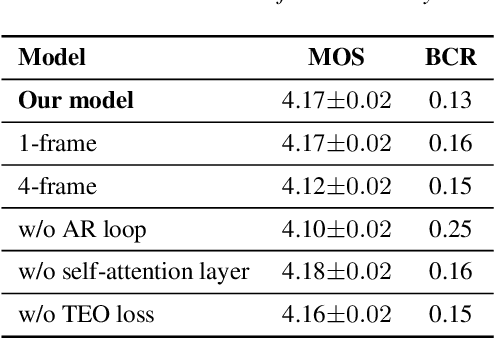
Generative adversarial networks (GANs) have been indicated their superiority in usage of the real-time speech synthesis. Nevertheless, most of them make use of deep convolutional layers as their backbone, which may cause the absence of previous signal information. However, the generation of speech signals invariably require preceding waveform samples in its reconstruction, as the lack of this can lead to artifacts in generated speech. To address this conflict, in this paper, we propose an improved model: a post auto-regressive (AR) GAN vocoder with a self-attention layer, which merging self-attention in an AR loop. It will not participate in inference, but can assist the generator to learn temporal dependencies within frames in training. Furthermore, an ablation study was done to confirm the contribution of each part. Systematic experiments show that our model leads to a consistent improvement on both objective and subjective evaluation performance.
Improving Prosody for Unseen Texts in Speech Synthesis by Utilizing Linguistic Information and Noisy Data
Nov 15, 2021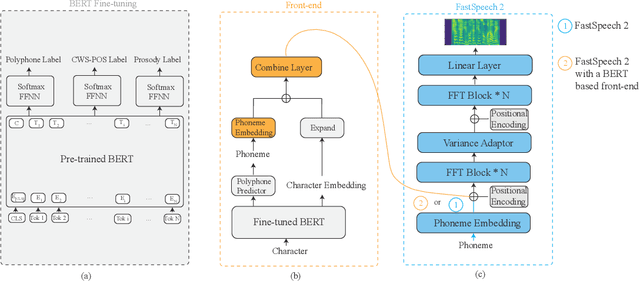

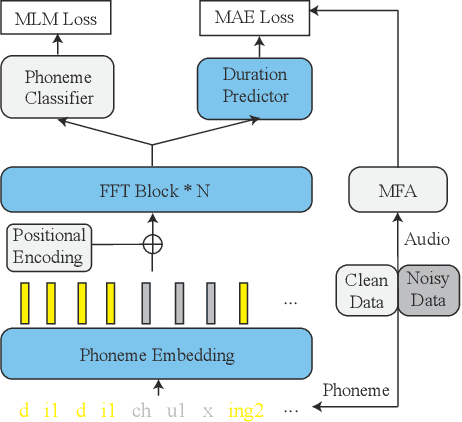

Recent advancements in end-to-end speech synthesis have made it possible to generate highly natural speech. However, training these models typically requires a large amount of high-fidelity speech data, and for unseen texts, the prosody of synthesized speech is relatively unnatural. To address these issues, we propose to combine a fine-tuned BERT-based front-end with a pre-trained FastSpeech2-based acoustic model to improve prosody modeling. The pre-trained BERT is fine-tuned on the polyphone disambiguation task, the joint Chinese word segmentation (CWS) and part-of-speech (POS) tagging task, and the prosody structure prediction (PSP) task in a multi-task learning framework. FastSpeech 2 is pre-trained on large-scale external data that are noisy but easier to obtain. Experimental results show that both the fine-tuned BERT model and the pre-trained FastSpeech 2 can improve prosody, especially for those structurally complex sentences.