 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Post Auto-regressive GAN Vocoder Focused on Spectrum Fracture
Apr 12, 2022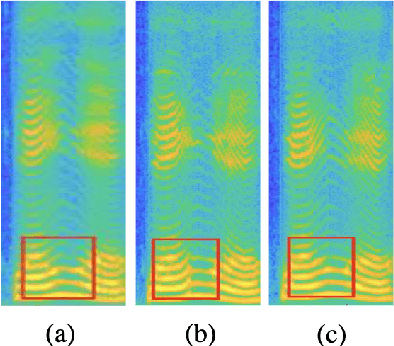
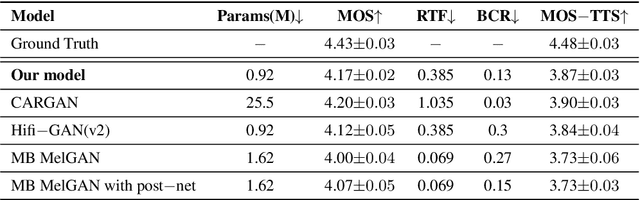
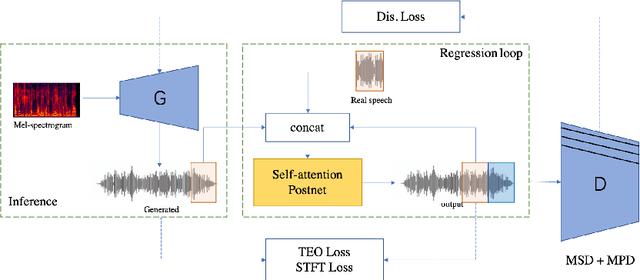
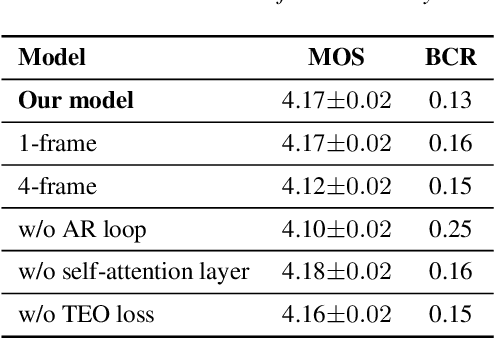
Generative adversarial networks (GANs) have been indicated their superiority in usage of the real-time speech synthesis. Nevertheless, most of them make use of deep convolutional layers as their backbone, which may cause the absence of previous signal information. However, the generation of speech signals invariably require preceding waveform samples in its reconstruction, as the lack of this can lead to artifacts in generated speech. To address this conflict, in this paper, we propose an improved model: a post auto-regressive (AR) GAN vocoder with a self-attention layer, which merging self-attention in an AR loop. It will not participate in inference, but can assist the generator to learn temporal dependencies within frames in training. Furthermore, an ablation study was done to confirm the contribution of each part. Systematic experiments show that our model leads to a consistent improvement on both objective and subjective evaluation performance.