 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-In-the-Loop Software Development Agents
Nov 19, 2024Recently, Large Language Models (LLMs)-based multi-agent paradigms for software engineering are introduced to automatically resolve software development tasks (e.g., from a given issue to source code). However, existing work is evaluated based on historical benchmark datasets, does not consider human feedback at each stage of the automated software development process, and has not been deployed in practice. In this paper, we introduce a Human-in-the-loop LLM-based Agents framework (HULA) for software development that allows software engineers to refine and guide LLMs when generating coding plans and source code for a given task. We design, implement, and deploy the HULA framework into Atlassian JIRA for internal uses. Through a multi-stage evaluation of the HULA framework, Atlassian software engineers perceive that HULA can minimize the overall development time and effort, especially in initiating a coding plan and writing code for straightforward tasks. On the other hand, challenges around code quality are raised to be solved in some cases. We draw lessons learned and discuss opportunities for future work, which will pave the way for the advancement of LLM-based agents in software development.
DeepSpeed4Science Initiative: Enabling Large-Scale Scientific Discovery through Sophisticated AI System Technologies
Oct 11, 2023



In the upcoming decade, deep learning may revolutionize the natural sciences, enhancing our capacity to model and predict natural occurrences. This could herald a new era of scientific exploration, bringing significant advancements across sectors from drug development to renewable energy. To answer this call, we present DeepSpeed4Science initiative (deepspeed4science.ai) which aims to build unique capabilities through AI system technology innovations to help domain experts to unlock today's biggest science mysteries. By leveraging DeepSpeed's current technology pillars (training, inference and compression) as base technology enablers, DeepSpeed4Science will create a new set of AI system technologies tailored for accelerating scientific discoveries by addressing their unique complexity beyond the common technical approaches used for accelerating generic large language models (LLMs). In this paper, we showcase the early progress we made with DeepSpeed4Science in addressing two of the critical system challenges in structural biology research.
VISinger 2: High-Fidelity End-to-End Singing Voice Synthesis Enhanced by Digital Signal Processing Synthesizer
Nov 05, 2022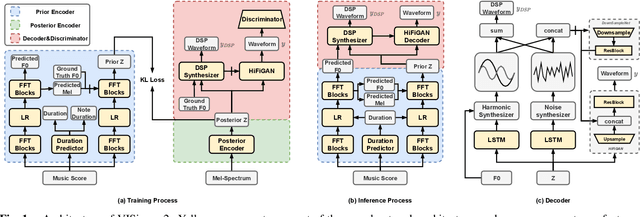
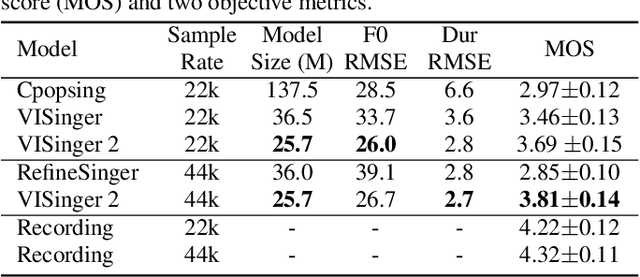
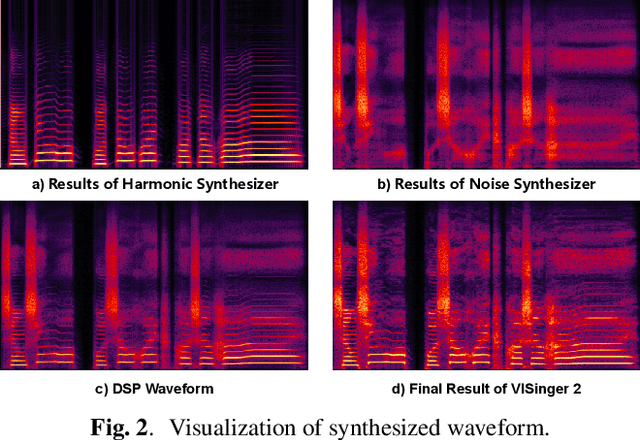
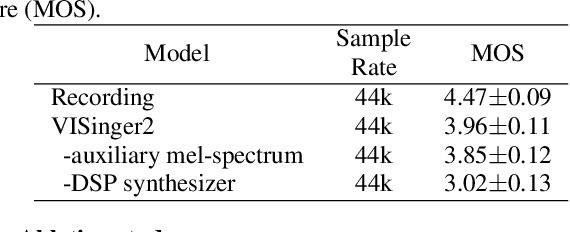
End-to-end singing voice synthesis (SVS) model VISinger can achieve better performance than the typical two-stage model with fewer parameters. However, VISinger has several problems: text-to-phase problem, the end-to-end model learns the meaningless mapping of text-to-phase; glitches problem, the harmonic components corresponding to the periodic signal of the voiced segment occurs a sudden change with audible artefacts; low sampling rate, the sampling rate of 24KHz does not meet the application needs of high-fidelity generation with the full-band rate (44.1KHz or higher). In this paper, we propose VISinger 2 to address these issues by integrating the digital signal processing (DSP) methods with VISinger. Specifically, inspired by recent advances in differentiable digital signal processing (DDSP), we incorporate a DSP synthesizer into the decoder to solve the above issues. The DSP synthesizer consists of a harmonic synthesizer and a noise synthesizer to generate periodic and aperiodic signals, respectively, from the latent representation z in VISinger. It supervises the posterior encoder to extract the latent representation without phase information and avoid the prior encoder modelling text-to-phase mapping. To avoid glitch artefacts, the HiFi-GAN is modified to accept the waveforms generated by the DSP synthesizer as a condition to produce the singing voice. Moreover, with the improved waveform decoder, VISinger 2 manages to generate 44.1kHz singing audio with richer expression and better quality. Experiments on OpenCpop corpus show that VISinger 2 outperforms VISinger, CpopSing and RefineSinger in both subjective and objective metrics.
A Post Auto-regressive GAN Vocoder Focused on Spectrum Fracture
Apr 12, 2022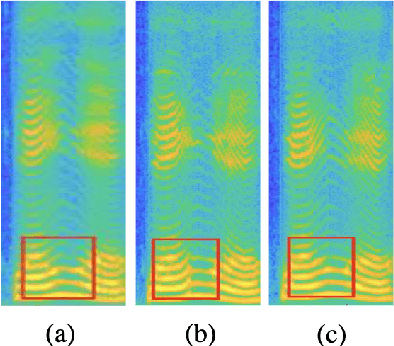
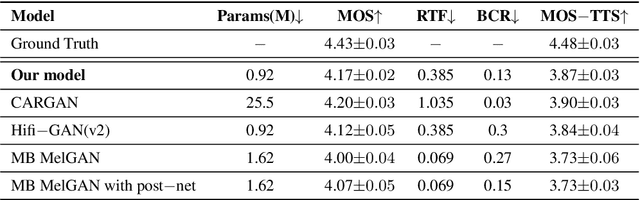
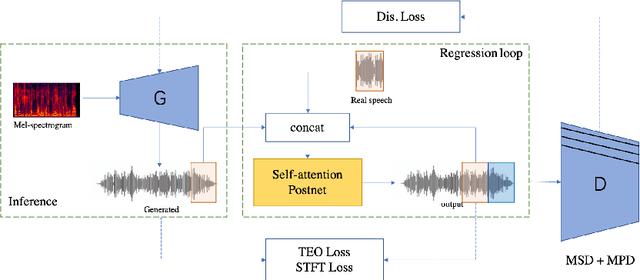
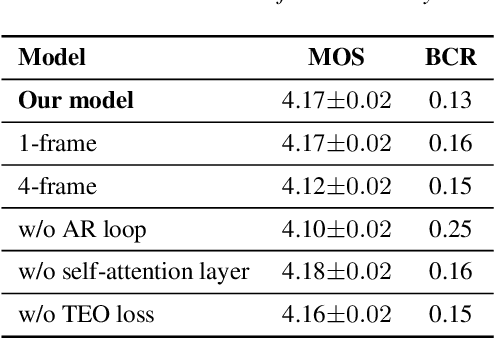
Generative adversarial networks (GANs) have been indicated their superiority in usage of the real-time speech synthesis. Nevertheless, most of them make use of deep convolutional layers as their backbone, which may cause the absence of previous signal information. However, the generation of speech signals invariably require preceding waveform samples in its reconstruction, as the lack of this can lead to artifacts in generated speech. To address this conflict, in this paper, we propose an improved model: a post auto-regressive (AR) GAN vocoder with a self-attention layer, which merging self-attention in an AR loop. It will not participate in inference, but can assist the generator to learn temporal dependencies within frames in training. Furthermore, an ablation study was done to confirm the contribution of each part. Systematic experiments show that our model leads to a consistent improvement on both objective and subjective evaluation performance.
Improving Prosody for Unseen Texts in Speech Synthesis by Utilizing Linguistic Information and Noisy Data
Nov 15, 2021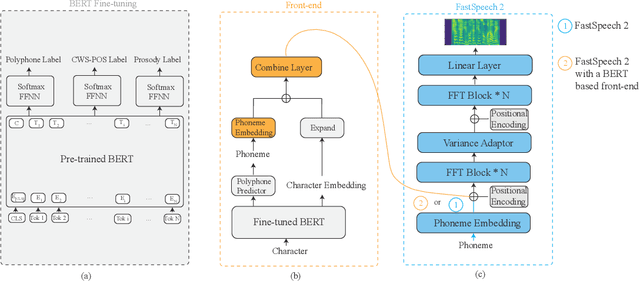

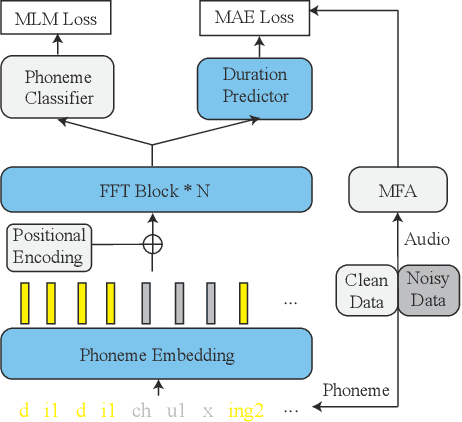

Recent advancements in end-to-end speech synthesis have made it possible to generate highly natural speech. However, training these models typically requires a large amount of high-fidelity speech data, and for unseen texts, the prosody of synthesized speech is relatively unnatural. To address these issues, we propose to combine a fine-tuned BERT-based front-end with a pre-trained FastSpeech2-based acoustic model to improve prosody modeling. The pre-trained BERT is fine-tuned on the polyphone disambiguation task, the joint Chinese word segmentation (CWS) and part-of-speech (POS) tagging task, and the prosody structure prediction (PSP) task in a multi-task learning framework. FastSpeech 2 is pre-trained on large-scale external data that are noisy but easier to obtain. Experimental results show that both the fine-tuned BERT model and the pre-trained FastSpeech 2 can improve prosody, especially for those structurally complex sentences.
Speech SIMCLR: Combining Contrastive and Reconstruction Objective for Self-supervised Speech Representation Learning
Oct 27, 2020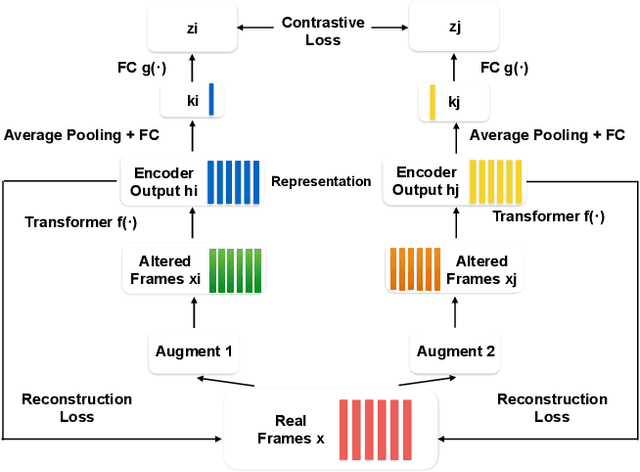

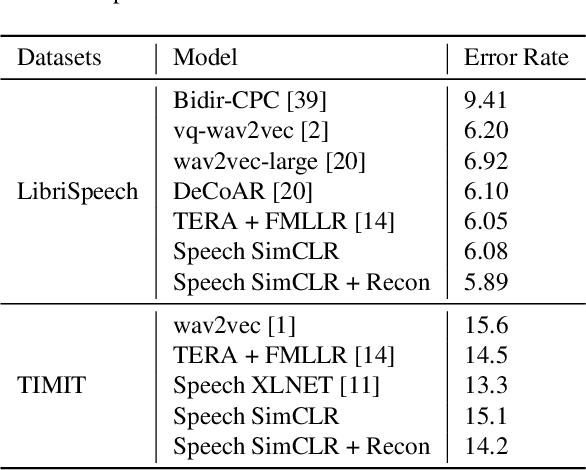

Self-supervised visual pretraining has shown significant progress recently. Among those methods, SimCLR greatly advanced the state of the art in self-supervised and semi-supervised learning on ImageNet. The input feature representations for speech and visual tasks are both continuous, so it is natural to consider applying similar objective on speech representation learning. In this paper, we propose Speech SimCLR, a new self-supervised objective for speech representation learning. During training, Speech SimCLR applies augmentation on raw speech and its spectrogram. Its objective is the combination of contrastive loss that maximizes agreement between differently augmented samples in the latent space and reconstruction loss of input representation. The proposed method achieved competitive results on speech emotion recognition and speech recognition. When used as feature extractor, our best model achieved 5.89% word error rate on LibriSpeech test-clean set using LibriSpeech 960 hours as pretraining data and LibriSpeech train-clean-100 set as fine-tuning data, which is the lowest error rate obtained in this setup to the best of our knowledge.
A Further Study of Unsupervised Pre-training for Transformer Based Speech Recognition
Jun 23, 2020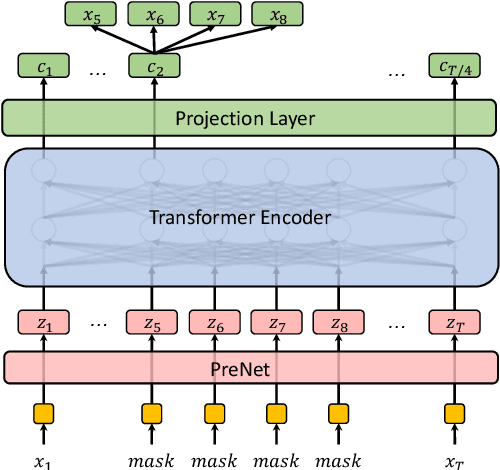
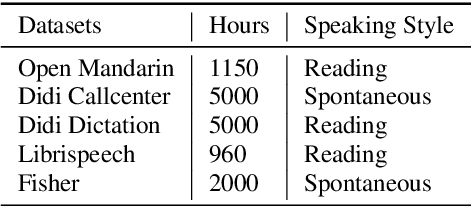
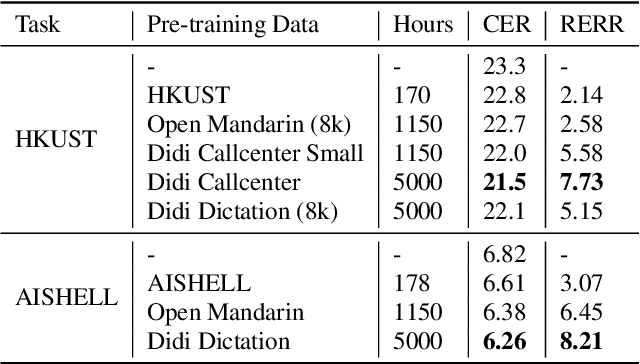
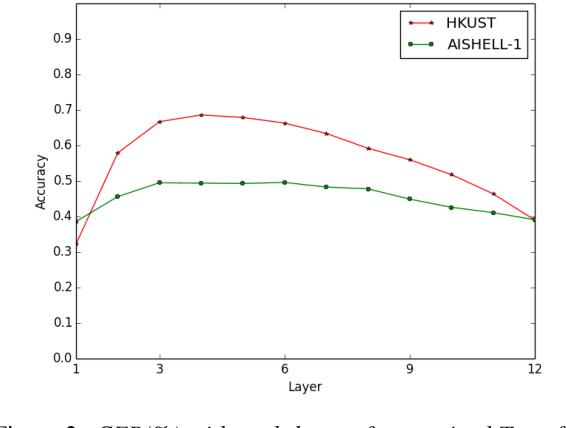
Building a good speech recognition system usually requires large amounts of transcribed data, which is expensive to collect. To tackle this problem, many unsupervised pre-training methods have been proposed. Among these methods, Masked Predictive Coding achieved significant improvements on various speech recognition datasets with BERT-like Masked Reconstruction loss and Transformer backbone. However, many aspects of MPC have not been fully investigated. In this paper, we conduct a further study on MPC and focus on three important aspects: the effect of pre-training data speaking style, its extension on streaming model, and how to better transfer learned knowledge from pre-training stage to downstream tasks. Experiments reveled that pre-training data with matching speaking style is more useful on downstream recognition tasks. A unified training objective with APC and MPC provided 8.46% relative error reduction on streaming model trained on HKUST. Also, the combination of target data adaption and layer-wise discriminative training helped the knowledge transfer of MPC, which achieved 3.99% relative error reduction on AISHELL over a strong baseline.
Cross-task pre-training for acoustic scene classification
Oct 22, 2019
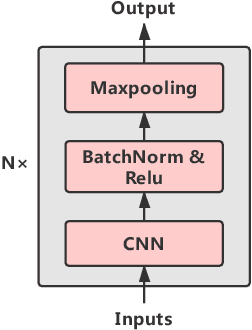
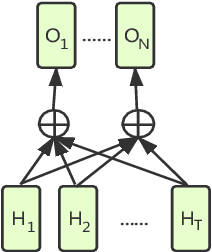
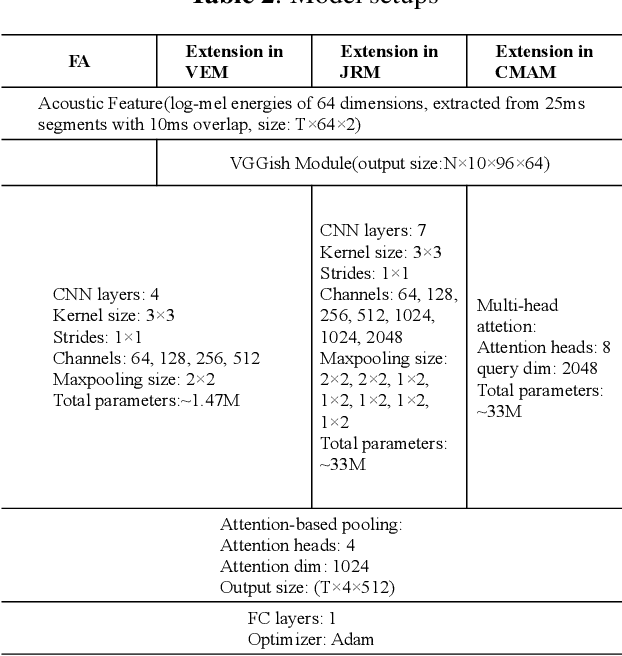
Acoustic scene classification(ASC) and acoustic event detection(AED) are different but related tasks. Acoustic scenes can be shaped by occurred acoustic events which can provide useful information in training ASC tasks. However, most of the datasets are provided without either the acoustic event or scene labels. Therefore, We explored cross-task pre-training mechanism to utilize acoustic event information extracted from the pre-trained model to optimize the ASC task. We present three cross-task pre-training architectures and evaluated them in feature-based and fine-tuning strategies on two datasets respectively: TAU Urban Acoustic Scenes 2019 dataset and TUT Acoustic Scenes 2017 dataset. Results have shown that cross-task pre-training mechanism can significantly improve the performance of ASC tasks and the performance of our best model improved relatively 9.5% in the TAU Urban Acoustic Scenes 2019 dataset, and also improved 10% in the TUT Acoustic Scenes 2017 dataset compared with the official baseline.