 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRotation Equivariant Convolutions in Deformable Registration of Brain MRI
Apr 09, 2026Image registration is a fundamental task that aligns anatomical structures between images. While CNNs perform well, they lack rotation equivariance - a rotated input does not produce a correspondingly rotated output. This hinders performance by failing to exploit the rotational symmetries inherent in anatomical structures, particularly in brain MRI. In this work, we integrate rotation-equivariant convolutions into deformable brain MRI registration networks. We evaluate this approach by replacing standard encoders with equivariant ones in three baseline architectures, testing on multiple public brain MRI datasets. Our experiments demonstrate that equivariant encoders have three key advantages: 1) They achieve higher registration accuracy while reducing network parameters, confirming the benefit of this anatomical inductive bias. 2) They outperform baselines on rotated input pairs, demonstrating robustness to orientation variations common in clinical practice. 3) They show improved performance with less training data, indicating greater sample efficiency. Our results demonstrate that incorporating geometric priors is a critical step toward building more robust, accurate, and efficient registration models.
MoME: Mixture of Visual Language Medical Experts for Medical Imaging Segmentation
Oct 30, 2025In this study, we propose MoME, a Mixture of Visual Language Medical Experts, for Medical Image Segmentation. MoME adapts the successful Mixture of Experts (MoE) paradigm, widely used in Large Language Models (LLMs), for medical vision-language tasks. The architecture enables dynamic expert selection by effectively utilizing multi-scale visual features tailored to the intricacies of medical imagery, enriched with textual embeddings. This work explores a novel integration of vision-language models for this domain. Utilizing an assembly of 10 datasets, encompassing 3,410 CT scans, MoME demonstrates strong performance on a comprehensive medical imaging segmentation benchmark. Our approach explores the integration of foundation models for medical imaging, benefiting from the established efficacy of MoE in boosting model performance by incorporating textual information. Demonstrating competitive precision across multiple datasets, MoME explores a novel architecture for achieving robust results in medical image analysis.
XOCT: Enhancing OCT to OCTA Translation via Cross-Dimensional Supervised Multi-Scale Feature Learning
Sep 09, 2025Optical Coherence Tomography Angiography (OCTA) and its derived en-face projections provide high-resolution visualization of the retinal and choroidal vasculature, which is critical for the rapid and accurate diagnosis of retinal diseases. However, acquiring high-quality OCTA images is challenging due to motion sensitivity and the high costs associated with software modifications for conventional OCT devices. Moreover, current deep learning methods for OCT-to-OCTA translation often overlook the vascular differences across retinal layers and struggle to reconstruct the intricate, dense vascular details necessary for reliable diagnosis. To overcome these limitations, we propose XOCT, a novel deep learning framework that integrates Cross-Dimensional Supervision (CDS) with a Multi-Scale Feature Fusion (MSFF) network for layer-aware vascular reconstruction. Our CDS module leverages 2D layer-wise en-face projections, generated via segmentation-weighted z-axis averaging, as supervisory signals to compel the network to learn distinct representations for each retinal layer through fine-grained, targeted guidance. Meanwhile, the MSFF module enhances vessel delineation through multi-scale feature extraction combined with a channel reweighting strategy, effectively capturing vascular details at multiple spatial scales. Our experiments on the OCTA-500 dataset demonstrate XOCT's improvements, especially for the en-face projections which are significant for clinical evaluation of retinal pathologies, underscoring its potential to enhance OCTA accessibility, reliability, and diagnostic value for ophthalmic disease detection and monitoring. The code is available at https://github.com/uci-cbcl/XOCT.
GameIR: A Large-Scale Synthesized Ground-Truth Dataset for Image Restoration over Gaming Content
Aug 29, 2024
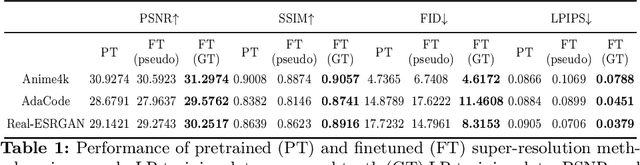
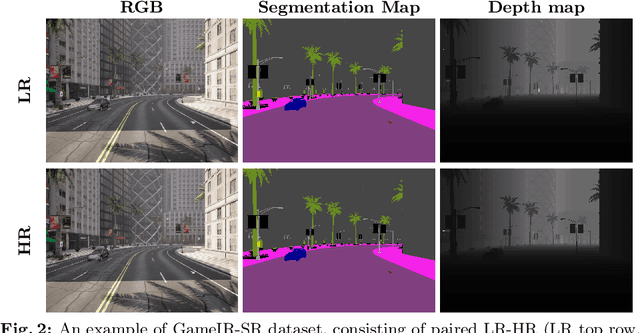
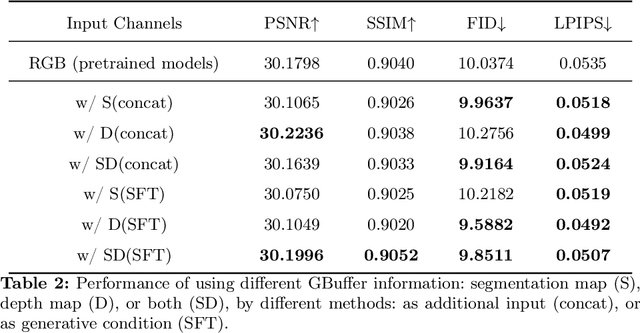
Image restoration methods like super-resolution and image synthesis have been successfully used in commercial cloud gaming products like NVIDIA's DLSS. However, restoration over gaming content is not well studied by the general public. The discrepancy is mainly caused by the lack of ground-truth gaming training data that match the test cases. Due to the unique characteristics of gaming content, the common approach of generating pseudo training data by degrading the original HR images results in inferior restoration performance. In this work, we develop GameIR, a large-scale high-quality computer-synthesized ground-truth dataset to fill in the blanks, targeting at two different applications. The first is super-resolution with deferred rendering, to support the gaming solution of rendering and transferring LR images only and restoring HR images on the client side. We provide 19200 LR-HR paired ground-truth frames coming from 640 videos rendered at 720p and 1440p for this task. The second is novel view synthesis (NVS), to support the multiview gaming solution of rendering and transferring part of the multiview frames and generating the remaining frames on the client side. This task has 57,600 HR frames from 960 videos of 160 scenes with 6 camera views. In addition to the RGB frames, the GBuffers during the deferred rendering stage are also provided, which can be used to help restoration. Furthermore, we evaluate several SOTA super-resolution algorithms and NeRF-based NVS algorithms over our dataset, which demonstrates the effectiveness of our ground-truth GameIR data in improving restoration performance for gaming content. Also, we test the method of incorporating the GBuffers as additional input information for helping super-resolution and NVS. We release our dataset and models to the general public to facilitate research on restoration methods over gaming content.
Orion-14B: Open-source Multilingual Large Language Models
Jan 20, 2024In this study, we introduce Orion-14B, a collection of multilingual large language models with 14 billion parameters. We utilize a data scheduling approach to train a foundational model on a diverse corpus of 2.5 trillion tokens, sourced from texts in English, Chinese, Japanese, Korean, and other languages. Additionally, we fine-tuned a series of models tailored for conversational applications and other specific use cases. Our evaluation results demonstrate that Orion-14B achieves state-of-the-art performance across a broad spectrum of tasks. We make the Orion-14B model family and its associated code publicly accessible https://github.com/OrionStarAI/Orion, aiming to inspire future research and practical applications in the field.
CVTHead: One-shot Controllable Head Avatar with Vertex-feature Transformer
Nov 11, 2023Reconstructing personalized animatable head avatars has significant implications in the fields of AR/VR. Existing methods for achieving explicit face control of 3D Morphable Models (3DMM) typically rely on multi-view images or videos of a single subject, making the reconstruction process complex. Additionally, the traditional rendering pipeline is time-consuming, limiting real-time animation possibilities. In this paper, we introduce CVTHead, a novel approach that generates controllable neural head avatars from a single reference image using point-based neural rendering. CVTHead considers the sparse vertices of mesh as the point set and employs the proposed Vertex-feature Transformer to learn local feature descriptors for each vertex. This enables the modeling of long-range dependencies among all the vertices. Experimental results on the VoxCeleb dataset demonstrate that CVTHead achieves comparable performance to state-of-the-art graphics-based methods. Moreover, it enables efficient rendering of novel human heads with various expressions, head poses, and camera views. These attributes can be explicitly controlled using the coefficients of 3DMMs, facilitating versatile and realistic animation in real-time scenarios.
Light Field Diffusion for Single-View Novel View Synthesis
Sep 23, 2023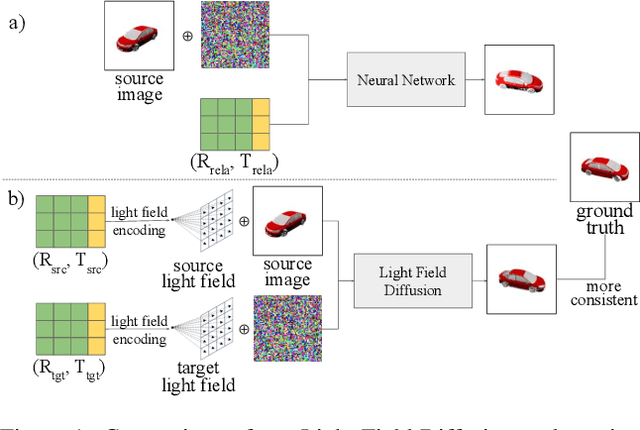
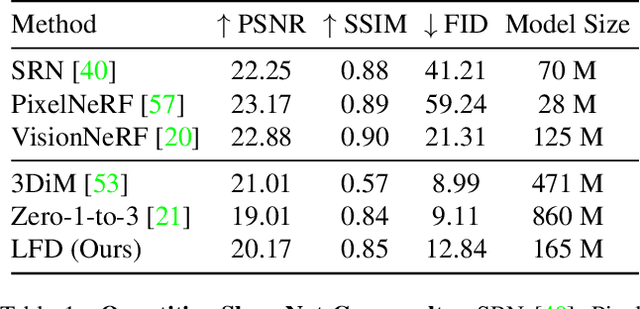
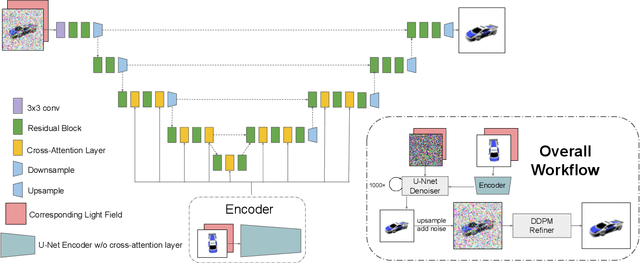
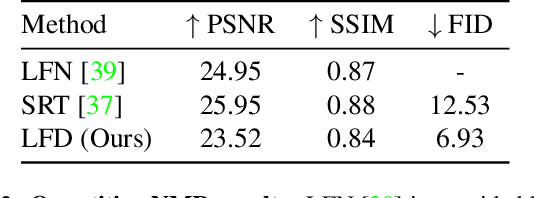
Single-view novel view synthesis, the task of generating images from new viewpoints based on a single reference image, is an important but challenging task in computer vision. Recently, Denoising Diffusion Probabilistic Model (DDPM) has become popular in this area due to its strong ability to generate high-fidelity images. However, current diffusion-based methods directly rely on camera pose matrices as viewing conditions, globally and implicitly introducing 3D constraints. These methods may suffer from inconsistency among generated images from different perspectives, especially in regions with intricate textures and structures. In this work, we present Light Field Diffusion (LFD), a conditional diffusion-based model for single-view novel view synthesis. Unlike previous methods that employ camera pose matrices, LFD transforms the camera view information into light field encoding and combines it with the reference image. This design introduces local pixel-wise constraints within the diffusion models, thereby encouraging better multi-view consistency. Experiments on several datasets show that our LFD can efficiently generate high-fidelity images and maintain better 3D consistency even in intricate regions. Our method can generate images with higher quality than NeRF-based models, and we obtain sample quality similar to other diffusion-based models but with only one-third of the model size.
Self-Sampling Meta SAM: Enhancing Few-shot Medical Image Segmentation with Meta-Learning
Sep 01, 2023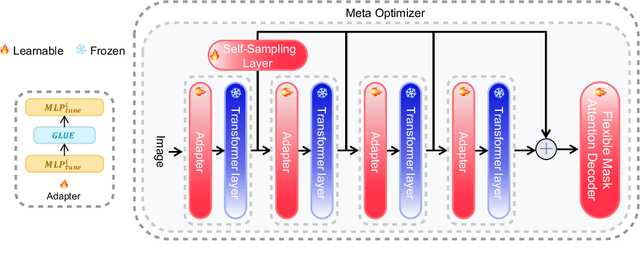
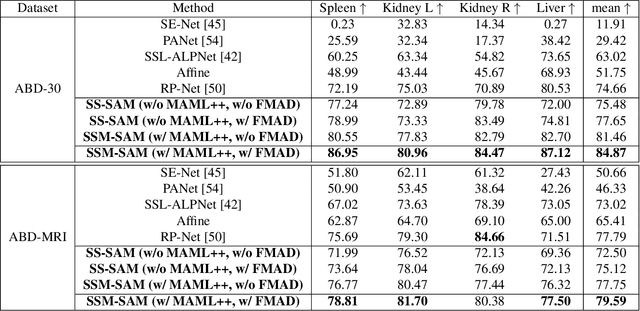
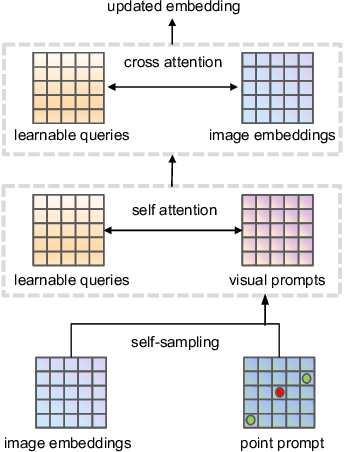
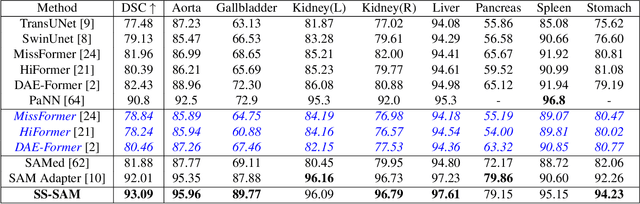
While the Segment Anything Model (SAM) excels in semantic segmentation for general-purpose images, its performance significantly deteriorates when applied to medical images, primarily attributable to insufficient representation of medical images in its training dataset. Nonetheless, gathering comprehensive datasets and training models that are universally applicable is particularly challenging due to the long-tail problem common in medical images. To address this gap, here we present a Self-Sampling Meta SAM (SSM-SAM) framework for few-shot medical image segmentation. Our innovation lies in the design of three key modules: 1) An online fast gradient descent optimizer, further optimized by a meta-learner, which ensures swift and robust adaptation to new tasks. 2) A Self-Sampling module designed to provide well-aligned visual prompts for improved attention allocation; and 3) A robust attention-based decoder specifically designed for medical few-shot learning to capture relationship between different slices. Extensive experiments on a popular abdominal CT dataset and an MRI dataset demonstrate that the proposed method achieves significant improvements over state-of-the-art methods in few-shot segmentation, with an average improvements of 10.21% and 1.80% in terms of DSC, respectively. In conclusion, we present a novel approach for rapid online adaptation in interactive image segmentation, adapting to a new organ in just 0.83 minutes. Code is publicly available on GitHub upon acceptance.
Optron: Better Medical Image Registration via Training in the Loop
Aug 29, 2023Previously, in the field of medical image registration, there are primarily two paradigms, the traditional optimization-based methods, and the deep-learning-based methods. Each of these paradigms has its advantages, and in this work, we aim to take the best of both worlds. Instead of developing a new deep learning model, we designed a robust training architecture that is simple and generalizable. We present Optron, a general training architecture incorporating the idea of training-in-the-loop. By iteratively optimizing the prediction result of a deep learning model through a plug-and-play optimizer module in the training loop, Optron introduces pseudo ground truth to an unsupervised training process. And by bringing the training process closer to that of supervised training, Optron can consistently improve the models' performance and convergence speed. We evaluated our method on various combinations of models and datasets, and we have achieved state-of-the-art performance on the IXI dataset, improving the previous state-of-the-art method TransMorph by a significant margin of +1.6% DSC. Moreover, Optron also consistently achieved positive results with other models and datasets. It increases the validation DSC for VoxelMorph and ViT-V-Net by +2.3% and +2.2% respectively on IXI, demonstrating our method's generalizability. Our implementation is publicly available at https://github.com/miraclefactory/optron
Hybrid-CSR: Coupling Explicit and Implicit Shape Representation for Cortical Surface Reconstruction
Jul 23, 2023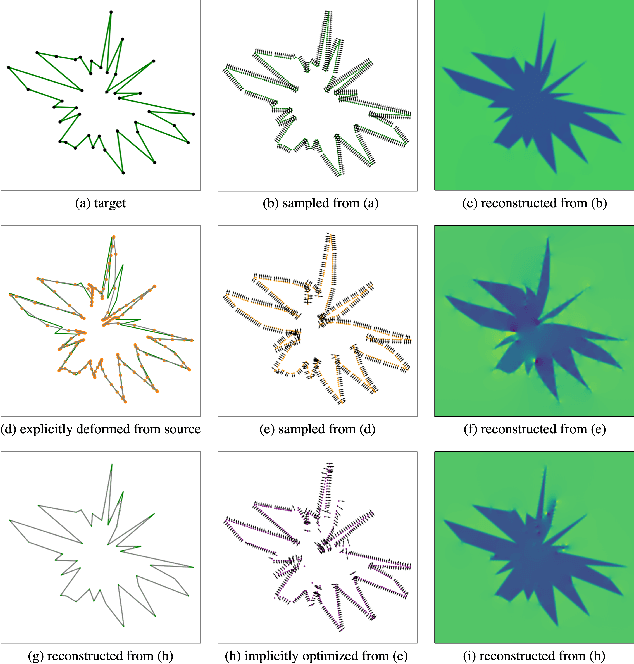
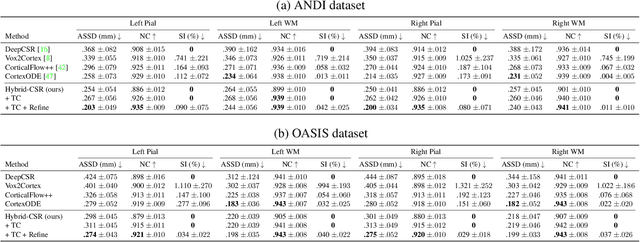
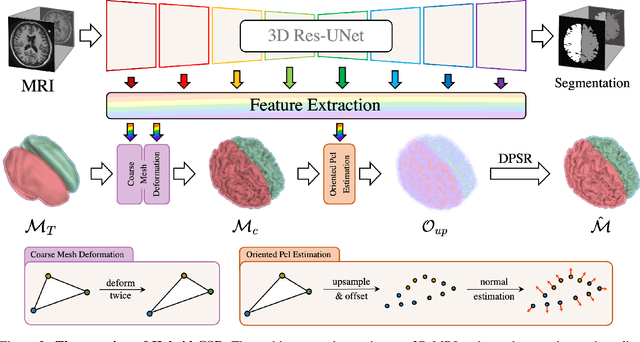
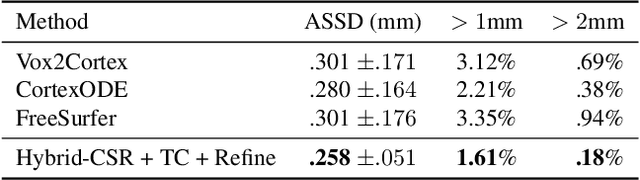
We present Hybrid-CSR, a geometric deep-learning model that combines explicit and implicit shape representations for cortical surface reconstruction. Specifically, Hybrid-CSR begins with explicit deformations of template meshes to obtain coarsely reconstructed cortical surfaces, based on which the oriented point clouds are estimated for the subsequent differentiable poisson surface reconstruction. By doing so, our method unifies explicit (oriented point clouds) and implicit (indicator function) cortical surface reconstruction. Compared to explicit representation-based methods, our hybrid approach is more friendly to capture detailed structures, and when compared with implicit representation-based methods, our method can be topology aware because of end-to-end training with a mesh-based deformation module. In order to address topology defects, we propose a new topology correction pipeline that relies on optimization-based diffeomorphic surface registration. Experimental results on three brain datasets show that our approach surpasses existing implicit and explicit cortical surface reconstruction methods in numeric metrics in terms of accuracy, regularity, and consistency.